Timon Harz
December 20, 2024
Slow Thinking with LLMs: Key Lessons from Imitation, Exploration, and Self-Improvement for AI Development
Explore how integrating "slow thinking" into Large Language Models can enhance their reasoning, adaptability, and ethical decision-making, creating more intelligent AI systems. Learn how these principles shape the future of AI development and its real-world applications.
Reasoning systems like OpenAI's O1 were recently introduced to tackle complex tasks by using slow-thinking processes. However, it is evident that large language models (LLMs) have limitations in areas like planning, problem decomposition, idea refinement, summarization, and rethinking, due to the constraints of their training and methodology. While these tools aim to enhance reasoning, they still rely heavily on structured guidance and additional processing time, leading to questions about their ability to handle intricate tasks independently without consistent human intervention.
Most current reasoning systems are based on fast-thinking approaches, providing quick answers but often lacking depth and accuracy. These systems, which have been developed and maintained primarily within the industry, typically don't disclose their core techniques. As a result, they struggle with extended reasoning, significantly hindering their ability to solve complex problems. Methods like tree search and reward models have been employed in some systems but have proven ineffective at generalizing across domains or were too slow for real-world applications. Newer systems have introduced test-time scaling, which allocates more processing time and generates detailed reasoning steps, or "thoughts," to reach solutions. Additionally, fine-tuning LLMs with extended chains of thought has shown improvements in handling more complex tasks.
To address these challenges, researchers from the Gaoling School of Artificial Intelligence, Renmin University of China, and BAAI have proposed a solution involving a three-phase framework—imitation, exploration, and self-improvement. This innovative approach aims to enhance reasoning in language models by refining the training process, creating systems that can reason more effectively, similar to OpenAI's O1.
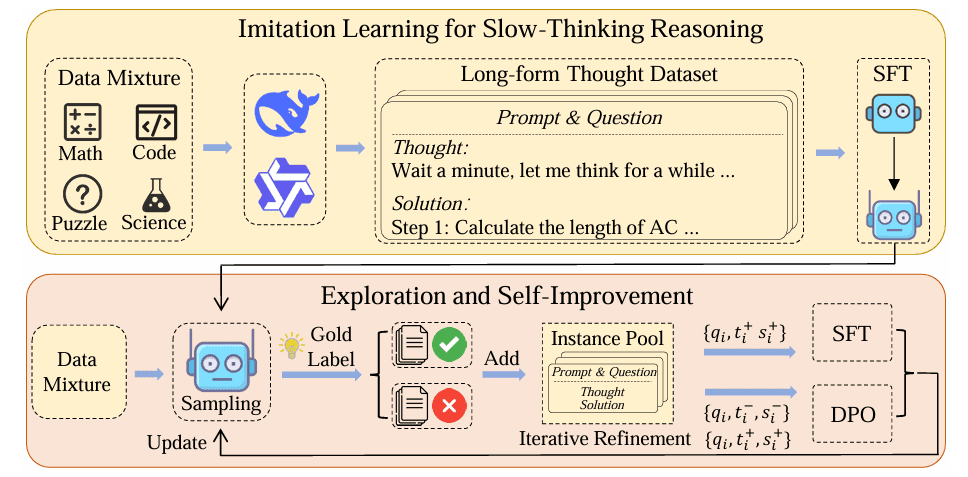
The model underwent training in three distinct phases to enhance its reasoning capabilities. In the imitation phase, it was taught to follow specific formats with minimal data, generating reasoning and solutions accordingly. The exploration phase focused on tackling complex problems, where the model worked on generating multiple solutions and refining them based on correct answers, particularly for tasks requiring slow thinking. During the self-improvement phase, high-quality data and advanced techniques like supervised fine-tuning (SFT) and direct preference optimization (DPO) were used to further refine the model’s reasoning abilities. Metrics such as length and perplexity helped eliminate low-quality data, but the model faced limitations due to insufficient challenging problems and the absence of reinforcement learning, owing to resource constraints. The primary goal of this approach was to continuously improve the model's reasoning through iterative refinement.
To evaluate the effectiveness of this framework, researchers tested it against three challenging benchmarks: MATH-OAI, AIME2024, and GPQA. MATH-OAI consisted of 500 competitive mathematics problems, AIME2024 included 30 high school-level questions, and GPQA featured 198 multiple-choice questions across biology, physics, and chemistry. The experiments focused on mathematics, with Qwen2.5-32B-Instruct as the backbone model, compared to other models like o1-preview, DeepSeek-R1-LitePreview, and QwQ-32B. A greedy search method, utilizing up to 32k tokens, was used during testing.
The results revealed that slow-thinking systems like o1-preview performed particularly well on AIME, while exploration-based training and distillation techniques also showed competitive results. Models trained with 3.9k instances from distillation achieved an accuracy of 90.2% on MATH-OAI and 46.7% on AIME. Iterative SFT and exploration training led to improvements on benchmarks like AIME and MATH-OAI, with variants trained on 1.1k instances consistently showing performance gains. However, performance was somewhat inconsistent, particularly on AIME, due to limited exploration capacity and the smaller number of test samples. The analysis also indicated that excluding hard problems diminished performance, while combining data from various domains, including mathematical tasks, enhanced the model's reasoning. Further DPO analysis suggested that aligning the thought process with SFT led to more stable optimization, although more experiments are required to fine-tune these strategies. This combination of iterative training, distillation, and exploration showed promise in improving performance across all tested benchmarks.
In conclusion, the researchers demonstrated the effectiveness of a slow-thinking framework for enhancing reasoning systems, particularly in solving complex problems. The approach, which leverages long-form thought data, allows models to generalize and tackle difficult tasks, especially in mathematics. The framework benefits from continuous self-improvement through exploration and flexible reasoning, though the research remains in its early stages. While the model shows progress, it still lags behind industry-standard systems in terms of performance. As the field develops, this framework could serve as a valuable foundation for future research in enhancing AI reasoning systems.
The concept of "slow thinking" is deeply rooted in human cognition, representing a deliberate and effortful mode of processing information. This contrasts with "fast thinking," which is automatic, intuitive, and often subconscious. The distinction between these two modes was extensively explored by psychologist Daniel Kahneman in his seminal work, *Thinking, Fast and Slow*. Kahneman delineates human thought processes into two systems:
- **System 1**: This system operates automatically and quickly, with little or no effort and no sense of voluntary control. It encompasses our instincts, intuitions, and immediate reactions.
- **System 2**: In contrast, System 2 allocates attention to the effortful mental activities that demand it, including complex computations. The operations of this system are often associated with the subjective experience of agency, choice, and concentration.
System 2, or "slow thinking," is characterized by its deliberative nature. It involves conscious reasoning, critical thinking, and the application of logic to solve problems. Engaging System 2 requires more cognitive resources and is typically slower than the automatic responses of System 1. However, it allows for more accurate and thoughtful decision-making, especially in complex or unfamiliar situations.
The significance of slow thinking in human cognition lies in its capacity to override the biases and heuristics that often govern fast thinking. While System 1 is efficient and effective for routine tasks and quick judgments, it is also susceptible to errors and biases. System 2 provides a check on these automatic responses, enabling individuals to engage in more rational and reflective thought processes.
Understanding the interplay between these two systems is crucial for various fields, including psychology, education, and artificial intelligence. Recognizing when to rely on fast thinking and when to engage slow thinking can lead to better decision-making and problem-solving strategies. Moreover, this understanding has practical applications in areas such as marketing, where insights into consumer behavior can be enhanced by considering the dual processes of human cognition.
In the realm of artificial intelligence, particularly in the development of Large Language Models (LLMs), the principles of slow thinking offer valuable lessons. By emulating the deliberative processes of human cognition, AI systems can be designed to engage in more thoughtful and accurate information processing. This approach involves integrating mechanisms that allow AI to perform complex reasoning tasks, evaluate multiple perspectives, and learn from experience, thereby enhancing their performance and reliability.
In summary, slow thinking is a fundamental aspect of human cognition, enabling individuals to engage in thoughtful, deliberate, and logical reasoning. Its significance extends beyond human psychology, offering valuable insights into the development of intelligent systems that mirror human cognitive processes.
The concept of "slow thinking," as delineated by psychologist Daniel Kahneman, refers to the deliberate, effortful, and analytical mode of human cognition, contrasting with the rapid, intuitive, and automatic "fast thinking." In the realm of artificial intelligence, particularly concerning Large Language Models (LLMs), integrating principles of slow thinking has become a focal point for enhancing reasoning capabilities and overall performance.
LLMs, such as OpenAI's GPT series, are predominantly designed to generate responses based on patterns learned from extensive datasets. This process often mirrors fast thinking, producing quick and contextually relevant outputs. However, these models can struggle with tasks requiring complex reasoning, multi-step problem-solving, and nuanced understanding—domains where slow thinking excels.
To address these challenges, researchers have been exploring methods to incorporate slow thinking into LLMs. One notable approach is "System 2 distillation," a technique developed by Meta's AI research team. This method involves training LLMs to perform complex reasoning tasks without necessitating intermediate steps, thereby enhancing their ability to handle intricate problems more efficiently. By distilling System 2 thinking into LLMs, the models can engage in more thoughtful and deliberate reasoning processes, akin to human slow thinking.
Another significant advancement is the development of dual-mind conversational agents, such as DUMA. This framework employs two generative LLMs dedicated to fast and slow thinking, respectively. The fast-thinking model serves as the primary interface for external interactions, generating initial responses. When the complexity of a response warrants, the slow-thinking model is engaged to provide a more thorough and reasoned reply. This dual-mind configuration allows for a seamless transition between intuitive responses and deliberate problem-solving processes, enhancing the model's adaptability and performance across various tasks.
Furthermore, integrating slow thinking into LLMs has been shown to improve their performance on complex reasoning tasks. For instance, a study demonstrated that LLMs trained with methods inspired by human slow thinking exhibited enhanced reasoning abilities, enabling them to solve problems that require multi-step logical deductions. This integration not only boosts the accuracy of the models but also their reliability in handling tasks that demand a higher level of cognitive processing.
The application of slow thinking principles to AI development is not without its challenges. Incorporating deliberate reasoning processes can lead to increased computational demands and longer response times. Balancing the efficiency of fast thinking with the depth of slow thinking is a critical consideration in AI design. Researchers are actively exploring dynamic decision-making frameworks that enable LLMs to autonomously select between fast and slow inference methods, optimizing both efficiency and effectiveness.
In summary, applying the concept of slow thinking to AI and LLMs involves integrating deliberate, analytical reasoning processes into models traditionally characterized by rapid, pattern-based responses. This integration enhances the models' ability to tackle complex, multi-step problems, improving their performance and reliability. As AI continues to evolve, incorporating elements of human cognition, such as slow thinking, will be pivotal in developing more sophisticated and capable intelligent systems.
In the evolving landscape of artificial intelligence (AI), particularly within the realm of Large Language Models (LLMs), the integration of human cognitive principles has become a focal point for enhancing AI capabilities. Among these principles, the concept of "slow thinking"—a deliberate, effortful, and analytical mode of processing information—offers valuable insights into developing more sophisticated AI systems. This approach emphasizes the importance of thoughtful reasoning, critical analysis, and the capacity to engage in complex problem-solving, all of which are essential for advancing AI technologies.
A pivotal aspect of this development is the application of imitation learning, a technique where AI systems learn by observing and replicating human behaviors and decisions. This method has been instrumental in enabling AI to perform tasks that require a nuanced understanding of human actions and intentions. For instance, in robotics, imitation learning allows machines to acquire skills by mimicking human demonstrations, thereby accelerating the learning process and enhancing the robot's ability to perform complex tasks. Similarly, in autonomous driving, AI systems utilize imitation learning to understand and replicate human driving patterns, contributing to safer and more efficient vehicle operation. The effectiveness of imitation learning in these contexts underscores its significance in bridging the gap between human expertise and machine learning.
Beyond imitation, exploration plays a crucial role in AI development. In human cognition, exploration involves seeking new experiences and information, leading to learning and adaptation. Translating this to AI, exploration enables systems to venture beyond their initial programming, discovering novel solutions and strategies. This is particularly evident in reinforcement learning, where AI agents explore various actions to maximize rewards, thereby enhancing their performance over time. However, exploration in AI presents challenges, such as the need for efficient reward structures and the balance between exploration and exploitation. Recent research has addressed these challenges by integrating intrinsic motivation into exploration strategies, encouraging AI agents to explore based on curiosity and self-improvement, rather than solely on external rewards. This approach has shown promise in improving the efficiency and effectiveness of exploration in AI systems.
The third key lesson is self-improvement, which involves AI systems enhancing their own capabilities through continuous learning and adaptation. This mirrors the human capacity for self-reflection and growth. In AI, self-improvement is achieved through mechanisms such as reinforcement learning, where agents learn from their interactions with the environment, and self-supervised learning, where models generate their own labels to improve performance. The concept of self-improvement in AI also encompasses the idea of artificial self-enhancement, where AI systems autonomously upgrade their algorithms and functionalities, potentially leading to superintelligent capabilities. While this presents exciting possibilities, it also raises ethical and safety concerns, emphasizing the need for careful consideration in the development of self-improving AI systems.
Integrating these principles—imitation, exploration, and self-improvement—into AI development offers a pathway to creating systems that not only perform tasks but also reason, adapt, and evolve in ways that mirror human cognitive processes. This integration holds the potential to advance AI technologies, making them more robust, adaptable, and capable of handling complex, real-world challenges. As AI continues to evolve, the lessons drawn from human cognition will be instrumental in shaping the future of intelligent systems.
Understanding Slow Thinking
The concept of "slow thinking" pertains to a deliberate, effortful, and analytical mode of processing information, contrasting with "fast thinking," which is automatic, intuitive, and often subconscious. This distinction was extensively explored by psychologist Daniel Kahneman in his seminal work, Thinking, Fast and Slow. Kahneman delineates human thought processes into two systems:
System 1: This system operates automatically and quickly, with little or no effort and no sense of voluntary control. It encompasses our instincts, intuitions, and immediate reactions.
System 2: In contrast, System 2 allocates attention to the effortful mental activities that demand it, including complex computations. The operations of this system are often associated with the subjective experience of agency, choice, and concentration.
System 2, or "slow thinking," is characterized by its deliberative nature. It involves conscious reasoning, critical thinking, and the application of logic to solve problems. Engaging System 2 requires more cognitive resources and is typically slower than the automatic responses of System 1. However, it allows for more accurate and thoughtful decision-making, especially in complex or unfamiliar situations.
The significance of slow thinking in human cognition lies in its capacity to override the biases and heuristics that often govern fast thinking. While System 1 is efficient and effective for routine tasks and quick judgments, it is also susceptible to errors and biases. System 2 provides a check on these automatic responses, enabling individuals to engage in more rational and reflective thought processes.
Understanding the interplay between these two systems is crucial for various fields, including psychology, education, and artificial intelligence. Recognizing when to rely on fast thinking and when to engage slow thinking can lead to better decision-making and problem-solving strategies. Moreover, this understanding has practical applications in areas such as marketing, where insights into consumer behavior can be enhanced by considering the dual processes of human cognition.
In the realm of artificial intelligence, particularly in the development of Large Language Models (LLMs), the principles of slow thinking offer valuable lessons. By emulating the deliberative processes of human cognition, AI systems can be designed to engage in more thoughtful and accurate information processing. This approach involves integrating mechanisms that allow AI to perform complex reasoning tasks, evaluate multiple perspectives, and learn from experience, thereby enhancing their performance and reliability.
Engaging in slow thinking—characterized by deliberate, effortful, and analytical processing—significantly enhances our capacity for deeper insights, more thoughtful decision-making, and effective problem-solving. This mode of cognition, often referred to as System 2 thinking, contrasts with the rapid, intuitive, and automatic responses of System 1 thinking. While System 1 is efficient for routine tasks and quick judgments, it is also susceptible to biases and errors. In contrast, slow thinking allows for a more thorough evaluation of information, leading to more accurate and reasoned conclusions.
One of the primary benefits of slow thinking is its ability to reduce cognitive biases. System 1 thinking, due to its reliance on heuristics and immediate impressions, can lead to systematic errors in judgment. By engaging System 2, individuals can critically assess their initial reactions, question assumptions, and consider alternative perspectives, thereby mitigating biases such as confirmation bias, anchoring, and availability heuristics. This reflective process enhances the quality of decision-making, particularly in complex or unfamiliar situations.
Moreover, slow thinking facilitates a deeper understanding of complex issues. When faced with intricate problems, taking the time to analyze and synthesize information leads to more comprehensive insights. This analytical approach enables individuals to identify underlying patterns, recognize interconnections, and foresee potential consequences, thereby enhancing problem-solving abilities. For instance, in scientific research, slow thinking allows for the careful design of experiments, critical evaluation of data, and thoughtful interpretation of results, leading to more robust and reliable conclusions.
In the context of decision-making, slow thinking encourages a more measured and thoughtful approach. While quick decisions may be necessary in certain situations, taking the time to deliberate can lead to better outcomes. This is particularly evident in high-stakes scenarios where the consequences of decisions are significant. For example, in medical diagnostics, physicians who engage in slow thinking are more likely to consider a broader range of potential diagnoses, leading to more accurate assessments and treatment plans.
Furthermore, slow thinking enhances creativity and innovation. By allowing time for reflection and incubation, individuals can connect disparate ideas, leading to novel solutions and creative breakthroughs. This process is evident in various fields, from artistic endeavors to technological innovations, where deliberate contemplation leads to the development of new concepts and approaches.
In summary, slow thinking is a vital cognitive process that underpins deeper insights, thoughtful decision-making, and effective problem-solving. By engaging in deliberate and analytical thought, individuals can enhance their cognitive abilities, leading to more accurate judgments, innovative solutions, and a better understanding of complex issues.
In the development of artificial intelligence (AI) systems, particularly Large Language Models (LLMs), integrating the concept of slow thinking—characterized by deliberate, effortful, and analytical processing—has become a focal point for enhancing AI capabilities. This approach draws inspiration from human cognitive processes, as delineated by psychologist Daniel Kahneman in his work Thinking, Fast and Slow, which distinguishes between two modes of thinking:
System 1: Fast, automatic, and intuitive thinking.
System 2: Slow, deliberate, and analytical thinking.
Integrating slow thinking into AI development involves designing systems that can engage in thoughtful reasoning, critical analysis, and complex problem-solving, thereby enhancing their performance and reliability.
One significant application of slow thinking in AI is the development of dual-process architectures that emulate human cognitive functions. For instance, the SOFAI (Slow and Fast AI) architecture incorporates both fast and slow solvers, enabling AI systems to handle tasks ranging from routine responses to complex problem-solving scenarios. This dual-process approach allows AI to balance efficiency with thoroughness, adapting to the demands of various tasks.
Moreover, the concept of slow thinking has been applied to conversational agents. The DUMA framework introduces a dual-mind mechanism by utilizing two generative LLMs dedicated to fast and slow thinking, respectively. This design enables the agent to provide quick responses when appropriate and engage in meticulous planning and reasoning for more complex inquiries, thereby enhancing the quality and depth of interactions.
In the realm of robotics, slow thinking has been integrated into language-conditioned robotic manipulation. By adopting a dual-process approach, robots can classify tasks and make decisions based on instruction types, allowing them to handle both simple actions and tasks requiring intent recognition and reasoning. This integration leads to more adaptable and intelligent robotic systems capable of performing a wide range of activities.
Furthermore, the application of slow thinking in AI has been explored in the context of navigation in constrained environments. By combining fast and slow decision-making processes, AI systems can evolve over time, transitioning from slow to fast thinking as they gain experience. This progression enhances decision quality, resource consumption, and efficiency, enabling AI to navigate complex environments more effectively.
In summary, integrating slow thinking into AI development offers a pathway to creating systems that not only perform tasks but also reason, adapt, and evolve in ways that mirror human cognitive processes. This integration holds the potential to advance AI technologies, making them more robust, adaptable, and capable of handling complex, real-world challenges. As AI continues to evolve, the lessons drawn from human cognition will be instrumental in shaping the future of intelligent systems.
Lesson 1: Imitation as a Learning Tool for LLMs
Large Language Models (LLMs) generate responses by leveraging extensive datasets and human behavior patterns through a process known as imitation learning. This methodology enables LLMs to produce human-like text by learning from the vast amounts of data they are trained on, which include books, articles, and other textual sources. By analyzing these datasets, LLMs identify patterns, structures, and nuances in language, allowing them to generate coherent and contextually relevant responses.
Imitation learning, a fundamental concept in machine learning, involves training models to replicate the behavior of an expert by observing and mimicking their actions. In the context of LLMs, the "expert" is the human-generated text present in the training data. Through this process, LLMs learn to predict the next word or sequence of words based on the patterns observed in the training data, effectively imitating human language use.
The effectiveness of LLMs in generating human-like responses is a direct result of their training on diverse and extensive datasets. These datasets encompass a wide range of topics, writing styles, and contexts, enabling LLMs to understand and generate text across various domains. The diversity of the training data is crucial, as it allows LLMs to handle a multitude of topics and respond appropriately to different prompts.
Furthermore, LLMs can be fine-tuned using specific datasets to enhance their performance in particular areas. For instance, fine-tuning an LLM on a dataset of medical literature can improve its ability to generate accurate and contextually relevant responses in the medical domain. This adaptability is a significant advantage, as it allows LLMs to be tailored for specialized applications, thereby increasing their utility and effectiveness.
The process of imitation learning in LLMs also involves the application of reinforcement learning techniques. By incorporating human feedback into the training process, LLMs can adjust their responses to align more closely with human preferences and expectations. This integration of reinforcement learning with imitation learning enhances the model's ability to generate responses that are not only linguistically coherent but also contextually appropriate and aligned with human values. The combination of these learning strategies enables LLMs to produce responses that are both accurate and nuanced, reflecting the complexities of human language and behavior.
In summary, LLMs utilize imitation learning from extensive datasets and human behavior patterns to generate responses. By analyzing and mimicking the structures and nuances of human language present in their training data, LLMs can produce coherent and contextually relevant text. The integration of reinforcement learning further refines their ability to align with human preferences, enhancing their effectiveness in various applications.
Imitation learning, a fundamental approach in machine learning, involves training models to replicate the behavior of an expert by observing and mimicking their actions. In the context of Large Language Models (LLMs), this method entails training the models on extensive datasets comprising human-generated text, enabling them to generate responses that mirror human language patterns. While imitation learning offers several advantages, it also presents certain limitations that are crucial to consider in AI development.
Advantages of Imitation Learning in LLMs
Sample Efficiency: Imitation learning is typically more sample-efficient than reinforcement learning because it learns directly from expert demonstrations, reducing the need for extensive trial-and-error interactions. This efficiency is particularly beneficial when acquiring real-world data is costly or time-consuming.
Alignment with Human Behavior: By training on human-generated text, LLMs can capture the nuances and complexities of human language, leading to responses that are contextually relevant and linguistically coherent. This alignment enhances the model's ability to engage in natural and meaningful interactions with users.
Reduced Need for Explicit Programming: Imitation learning allows LLMs to learn tasks through observation rather than explicit programming. This capability enables the models to handle a wide range of tasks without the need for task-specific programming, thereby increasing their versatility and applicability across various domains.
Facilitation of Transfer Learning: Models trained through imitation learning can be fine-tuned on specific tasks or datasets, facilitating transfer learning. This adaptability allows LLMs to perform specialized tasks effectively, even when limited task-specific data is available.
Limitations of Imitation Learning in LLMs
Dependence on Quality of Training Data: The performance of LLMs trained via imitation learning is heavily dependent on the quality and diversity of the training data. If the data contains biases or inaccuracies, the model is likely to replicate these issues in its responses, potentially leading to undesirable outcomes.
Inability to Handle Novel Situations: Imitation learning primarily enables models to replicate observed behaviors. Consequently, LLMs may struggle to handle novel or unforeseen situations that were not present in the training data, limiting their ability to generalize beyond the scenarios they have been trained on.
Risk of Overfitting: There is a risk that LLMs may overfit to the specific patterns present in the training data, leading to a lack of robustness and adaptability. Overfitting can result in models that perform well on training data but fail to generalize to new, unseen data.
Challenges in Capturing Long-Term Dependencies: Imitation learning may not effectively capture long-term dependencies and complex reasoning patterns inherent in human language. This limitation can result in models that generate responses lacking coherence over extended interactions or fail to maintain context in long conversations.
Potential for Misalignment with Human Intent: While imitation learning aligns models with observed human behavior, it does not inherently ensure that the model's actions align with human intent or ethical standards. Without additional mechanisms to incorporate human values and preferences, LLMs may produce outputs that are misaligned with desired outcomes.
Difficulty in Handling Ambiguity: Imitation learning may not equip LLMs to effectively handle ambiguous or contradictory information. Without explicit guidance or additional training, models might generate responses that are inconsistent or unclear when faced with ambiguous inputs.
Limited Ability to Innovate: Since imitation learning focuses on replicating existing behaviors, LLMs may have limited capacity for innovation or creative problem-solving. This limitation can hinder the development of models capable of generating novel solutions or ideas beyond those present in the training data.
In summary, while imitation learning offers significant advantages in training LLMs, such as sample efficiency and alignment with human behavior, it also presents notable limitations. These include dependence on the quality of training data, challenges in handling novel situations, and potential misalignment with human intent. Addressing these limitations requires careful consideration of training methodologies, data curation, and the integration of additional learning strategies to enhance the robustness and adaptability of LLMs.
The quality of imitation learning plays a pivotal role in shaping the development of Large Language Models (LLMs) that produce accurate and human-like responses. Imitation learning, a fundamental approach in machine learning, involves training models to replicate the behavior of an expert by observing and mimicking their actions. In the context of LLMs, this method entails training the models on extensive datasets comprising human-generated text, enabling them to generate responses that mirror human language patterns. The effectiveness of this training approach is heavily influenced by the quality of the data used, which directly impacts the model's ability to understand and generate human-like text.
High-quality training data is essential for LLMs to learn the nuances and complexities of human language. When LLMs are trained on datasets that accurately represent human language, they are better equipped to generate responses that are contextually relevant, coherent, and linguistically sophisticated. Conversely, training on low-quality or noisy data can lead to models that produce outputs with grammatical errors, inconsistencies, and a lack of contextual understanding. This underscores the importance of curating and preprocessing training data to ensure its quality, as the model's performance is intrinsically linked to the data it learns from.
Moreover, the diversity of the training data contributes significantly to the model's ability to generalize across various topics and contexts. A diverse dataset exposes the LLM to a wide range of language patterns, styles, and subject matter, enabling it to handle different prompts and generate responses that are both accurate and contextually appropriate. This diversity is particularly crucial in applications where the model is expected to engage in conversations on a multitude of topics, as it enhances the model's adaptability and responsiveness.
The impact of data quality on LLM performance has been a subject of research in the AI community. Studies have shown that the presence of noisy or false data in training sets can adversely affect the model's ability to generate accurate and truthful responses. For instance, research indicates that when LLMs are trained with datasets containing false information, they may learn to produce unfaithful answers, even when they possess the correct information. This phenomenon highlights the critical need for data curation and validation to maintain the integrity of the training process.
Furthermore, the quality of imitation learning influences the model's capacity to understand and replicate complex human behaviors and reasoning patterns. High-quality training data enables LLMs to capture subtle aspects of human communication, such as tone, intent, and emotional nuance, leading to more empathetic and context-aware responses. This capability is particularly valuable in applications like customer service, mental health support, and educational tools, where understanding and appropriately responding to human emotions and intentions are paramount.
In summary, the quality of imitation learning is a critical determinant in the development of LLMs that produce accurate and human-like responses. Ensuring high-quality, diverse, and well-curated training data is essential for enabling LLMs to learn the complexities of human language and behavior, thereby enhancing their performance and applicability across various domains.
Lesson 2: Exploration and the Role of Curiosity in AI Development
Exploration is a fundamental aspect of artificial intelligence (AI) development, serving as a catalyst for innovation and advancement. In the realm of AI, exploration involves delving into new methodologies, algorithms, and applications to uncover novel solutions and enhance existing systems. This process is crucial for pushing the boundaries of AI capabilities and ensuring that these systems can adapt to a wide array of tasks and environments.
One of the primary reasons exploration is vital in AI development is its role in fostering innovation. By experimenting with diverse approaches and technologies, researchers and developers can discover more efficient algorithms, improve system performance, and create applications that were previously unimaginable. This spirit of exploration leads to breakthroughs that can revolutionize industries, from healthcare to finance, by introducing AI solutions that are more accurate, efficient, and capable of handling complex tasks.
Moreover, exploration enables AI systems to learn from a broader range of data and experiences. In machine learning, particularly reinforcement learning, the exploration-exploitation dilemma is a central concept. This dilemma involves balancing the need to explore new actions to discover their potential rewards (exploration) with the need to exploit known actions that yield high rewards (exploitation). Effective exploration allows AI systems to avoid local optima and discover more optimal solutions, thereby enhancing their performance and adaptability.
Furthermore, exploration is essential for the development of autonomous AI systems. For AI to operate effectively in dynamic and unpredictable environments, it must be capable of exploring and learning from its surroundings without explicit programming for every possible scenario. This capability is particularly important in applications such as robotics, where AI systems must navigate and interact with the physical world, and in natural language processing, where understanding and generating human-like text require exposure to diverse linguistic patterns and contexts.
Incorporating exploration into AI development also addresses the limitations of traditional supervised learning. While supervised learning relies on labeled datasets, exploration allows AI systems to learn from unlabeled data and real-world interactions, leading to more robust and generalizable models. This approach is particularly beneficial in situations where labeled data is scarce or expensive to obtain, enabling AI systems to learn from the vast amounts of unstructured data available in the real world.
However, it is important to recognize that exploration in AI development comes with its own set of challenges. Unrestricted exploration can lead to unintended behaviors or outcomes, especially in complex systems. Therefore, it is crucial to implement mechanisms that guide exploration in a manner that aligns with desired objectives and ethical standards. This includes developing frameworks for safe exploration, where AI systems can explore new possibilities without causing harm or deviating from intended goals.
Exploration is a fundamental aspect of artificial intelligence (AI) development, particularly in the context of Large Language Models (LLMs). While LLMs are initially trained on extensive datasets to learn patterns and generate human-like text, their ability to explore beyond their initial programming is crucial for adapting to new contexts, learning novel patterns, and providing more accurate and contextually relevant responses.
In traditional machine learning, models are trained on predefined datasets, which can limit their ability to generalize to new, unseen situations. Exploration allows LLMs to go beyond this limitation by enabling them to interact with new data, environments, and tasks, thereby learning new patterns and behaviors. This process is akin to how humans learn through experience and experimentation, allowing AI systems to adapt and improve over time.
Recent research has investigated the extent to which LLMs can engage in exploration. A study titled "Can large language models explore in-context?" examined the performance of LLMs like GPT-3.5, GPT-4, and Llama2 in simple multi-armed bandit environments. The researchers found that while LLMs could engage in exploration under certain conditions, achieving robust exploratory behavior often required substantial interventions, such as chain-of-thought reasoning and externally summarized interaction histories. This suggests that while LLMs have the potential for exploration, their ability to do so effectively may depend on specific training and prompt engineering techniques.
Another study, "Efficient Exploration for LLMs," demonstrated that incorporating efficient exploration strategies could significantly enhance the performance of LLMs in tasks requiring human feedback. By generating queries using double Thompson sampling and representing uncertainty with an epistemic neural network, the researchers showed that LLMs could achieve high levels of performance with fewer queries, highlighting the importance of exploration in improving AI systems.
Furthermore, the integration of LLMs with reinforcement learning frameworks has been explored to guide exploration in AI systems. The ExploRLLM approach leverages the inductive bias of foundation models to guide exploration in reinforcement learning, enhancing training efficiency and enabling AI systems to discover more optimal solutions.
In the realm of artificial intelligence (AI) development, particularly within the framework of reinforcement learning (RL), the exploration-exploitation trade-off is a fundamental concept that significantly influences the efficacy and adaptability of AI systems. This trade-off pertains to the balance between two distinct strategies: exploration, which involves seeking out new information and experiences, and exploitation, which focuses on utilizing existing knowledge to maximize immediate rewards.
Exploration enables AI systems to discover novel strategies, uncover hidden patterns, and adapt to unforeseen circumstances. By venturing into uncharted territories, AI models can enhance their generalization capabilities, leading to more robust and versatile performance across diverse scenarios. However, excessive exploration without sufficient exploitation can result in inefficiencies, as the system may spend considerable time and resources on suboptimal actions that do not yield immediate benefits. This inefficiency can hinder the learning process and delay the achievement of optimal performance.
Conversely, exploitation allows AI systems to leverage their current knowledge to make decisions that maximize immediate rewards. By capitalizing on known successful strategies, the system can achieve short-term gains. However, overemphasis on exploitation can lead to stagnation, where the AI becomes entrenched in suboptimal policies and fails to adapt to new or changing environments. This lack of adaptability can be detrimental, especially in dynamic settings where conditions evolve over time.
Striking an optimal balance between exploration and exploitation is crucial for the development of AI systems that are both efficient and adaptable. Achieving this balance involves implementing strategies that allow the AI to explore new possibilities while also exploiting known successful actions. Techniques such as epsilon-greedy algorithms, which introduce randomness into action selection, and Upper Confidence Bound (UCB) methods, which consider the uncertainty of action values, are commonly employed to manage this trade-off. These methods help in determining when to explore and when to exploit, thereby enhancing the learning process and overall performance of the AI system.
Recent advancements in AI research have further refined approaches to balancing exploration and exploitation. For instance, the SEREN (SElective Reinforcement Exploration Network) framework introduces a game-theoretic approach to this trade-off, employing two agents: an exploiter that focuses on known rewards and a switcher that determines when to activate an exploration policy. This method has demonstrated improved convergence rates and performance in various benchmarks.
Additionally, studies have explored dynamic strategies that adjust the exploration-exploitation balance based on the learning phase. The BHEEM (Bayesian Hierarchical Exploration-Exploitation Method) approach, for example, dynamically modulates this balance as more data is acquired, leading to enhanced performance in active learning scenarios.
In summary, the exploration-exploitation trade-off is a pivotal element in AI development, influencing how systems learn, adapt, and perform across various tasks. A nuanced understanding and application of this balance are essential for creating AI models that are not only efficient in utilizing existing knowledge but also capable of exploring new avenues to achieve optimal performance in complex and dynamic environments.
Lesson 3: Self-Improvement: Continuous Learning and Refinement in LLMs
Self-improvement in artificial intelligence (AI) refers to the capability of AI systems to autonomously enhance their performance, adapt to new tasks, and refine their functionalities without explicit human intervention. This concept is particularly pertinent in the context of Large Language Models (LLMs), which are designed to understand and generate human-like text. The ability of LLMs to self-improve holds significant implications for their application across various domains, including natural language processing, machine translation, and content generation.
Traditional AI models often rely on supervised learning, where they are trained on labeled datasets to perform specific tasks. While this approach has yielded impressive results, it is limited by the availability and quality of labeled data. Self-improvement mechanisms enable LLMs to overcome these limitations by allowing them to learn from unlabeled data, thereby enhancing their generalization capabilities and adaptability to new contexts.
Recent research has demonstrated that LLMs can engage in self-improvement through various methodologies. One such approach involves using pre-trained LLMs to generate high-confidence rationale-augmented answers for unlabeled questions. By employing techniques like Chain-of-Thought prompting and self-consistency, these models can fine-tune themselves using the self-generated solutions as target outputs. This process has been shown to improve the general reasoning abilities of LLMs across multiple benchmarks, including GSM8K, DROP, OpenBookQA, and ANLI-A3, without the need for ground truth labels.
Another innovative method for self-improvement in LLMs is the application of reinforcement learning. In this framework, LLMs generate answers to unlabeled questions and evaluate their own responses, assigning scores based on predefined criteria. The model parameters are then updated using reinforcement learning algorithms to maximize these evaluation scores. This self-evaluative process enables LLMs to enhance their performance in tasks such as reasoning, text generation, and machine translation, all without external supervision.
The concept of recursive self-improvement, where an AI system iteratively enhances its own capabilities, has been a topic of interest in AI research. This approach suggests that AI systems could autonomously improve their own functionality, leading to rapid advancements in intelligence. However, the practical implementation of recursive self-improvement in LLMs presents challenges, including ensuring stability, safety, and alignment with human values. Addressing these challenges is crucial to prevent unintended behaviors and to maintain control over the AI's development trajectory.
The potential for self-improvement in LLMs also raises ethical and safety considerations. As AI systems become more capable of autonomous learning and adaptation, it is imperative to establish robust oversight mechanisms to monitor and guide their development. This includes implementing safety measures to prevent harmful behaviors, ensuring transparency in AI decision-making processes, and aligning AI objectives with human values. The rapid advancement of AI technologies necessitates ongoing research and dialogue to address these concerns effectively.
In summary, self-improvement in LLMs represents a significant advancement in AI capabilities, enabling models to autonomously enhance their performance and adapt to new tasks. While this offers promising opportunities for more intelligent and versatile AI systems, it also necessitates careful consideration of ethical, safety, and control measures to ensure that these advancements benefit society as a whole.
In the realm of artificial intelligence (AI), particularly concerning Large Language Models (LLMs), techniques such as reinforcement learning and continuous fine-tuning have emerged as pivotal methodologies for enhancing model performance and adaptability. These approaches enable LLMs to refine their capabilities, align more closely with human preferences, and maintain relevance across diverse tasks and evolving data distributions.
Reinforcement Learning (RL) in Large Language Models
Reinforcement learning is a machine learning paradigm where an agent learns to make decisions by interacting with an environment, receiving feedback in the form of rewards or penalties. In the context of LLMs, RL is employed to fine-tune models based on human feedback, a process known as Reinforcement Learning from Human Feedback (RLHF). This methodology allows LLMs to generate responses that are more aligned with human expectations and preferences.
The RLHF process typically involves several key steps:
Pre-training: The LLM is initially trained on a large corpus of text data to develop a broad understanding of language.
Supervised Fine-tuning: The model is then fine-tuned on a dataset curated with human annotations to guide its responses toward desired outputs.
Reinforcement Learning: The model's outputs are evaluated, and feedback is provided to adjust the model's parameters, enhancing its ability to generate responses that align with human preferences.
This iterative process enables LLMs to improve their performance in tasks such as question-answering, summarization, and content generation, making them more effective and user-friendly.
Continuous Fine-Tuning in Large Language Models
Continuous fine-tuning refers to the ongoing process of updating an LLM's parameters as new data becomes available. This approach is essential for maintaining the model's relevance and performance over time, especially in dynamic environments where language usage and information evolve.
The process of continuous fine-tuning involves:
Data Collection: Gathering new data that reflects current language usage, trends, and information.
Fine-Tuning: Updating the model's parameters using the new data to adapt to recent changes and improve performance on current tasks.
Evaluation: Assessing the model's performance to ensure that the fine-tuning process has led to desired improvements without introducing new issues.
This approach is particularly beneficial for applications requiring up-to-date knowledge, such as news summarization, real-time translation, and customer support systems. By continuously fine-tuning LLMs, developers can ensure that these models remain accurate and effective in the face of evolving language patterns and information.
Integrating Reinforcement Learning and Continuous Fine-Tuning
Combining reinforcement learning with continuous fine-tuning offers a robust framework for developing LLMs that are both adaptable and aligned with human preferences. This integrated approach allows models to learn from human feedback while continuously updating their knowledge base, leading to more accurate and contextually relevant outputs.
For instance, a study titled "Teaching Large Language Models to Reason with Reinforcement Learning" explores the performance of various algorithms that learn from feedback, such as Expert Iteration and Proximal Policy Optimization (PPO), in improving LLM reasoning capabilities. The research investigates both sparse and dense rewards provided to the LLM, highlighting the effectiveness of combining reinforcement learning with continuous fine-tuning in enhancing model performance.
Furthermore, the "Survey on Large Language Model-Enhanced Reinforcement Learning" provides a comprehensive review of existing literature on LLM-enhanced RL, summarizing its characteristics compared to conventional RL methods. This survey clarifies the research scope and directions for future studies, emphasizing the importance of integrating reinforcement learning with continuous fine-tuning to augment LLM capabilities.
Self-improvement in Large Language Models (LLMs) refers to their capacity to autonomously enhance their performance, adapt to new information, correct errors, and refine their outputs over time. This dynamic learning process enables LLMs to evolve beyond their initial training, leading to more accurate and contextually relevant responses.
Adapting to New Information
LLMs are initially trained on extensive datasets, which provide a broad understanding of language and knowledge up to a certain point in time. However, the world is continually changing, introducing new information, concepts, and contexts. To remain relevant, LLMs must adapt to this evolving landscape. Self-improvement mechanisms facilitate this adaptation by allowing models to process and integrate new data, thereby updating their knowledge base. For instance, a study demonstrated that LLMs could self-improve using only unlabeled datasets, enabling them to enhance their reasoning abilities without external inputs.
Correcting Mistakes
Despite their advanced capabilities, LLMs can produce incorrect or nonsensical outputs. Self-improvement enables these models to identify and rectify their mistakes. One approach involves prompting LLMs to provide feedback on their own responses, allowing them to refine their outputs based on this self-assessment. Additionally, research has explored methods where LLMs learn from their past errors to boost reasoning, enhancing their ability to correct mistakes in future tasks.
Refining Outputs Over Time
Continuous refinement of outputs is crucial for tasks requiring high accuracy and relevance. Self-improvement mechanisms enable LLMs to iteratively enhance their responses. For example, the "Sharpening Mechanism" offers a new perspective on self-improvement, where language models evaluate and refine their own generations to achieve higher performance without external feedback.
In summary, self-improvement empowers LLMs to autonomously adapt to new information, correct errors, and refine their outputs, leading to more accurate and contextually relevant responses. This capability is essential for applications requiring up-to-date knowledge and high precision, such as real-time information retrieval, personalized content generation, and complex problem-solving tasks.
Integrating Slow Thinking with LLM Development
In the realm of Large Language Models (LLMs), self-improvement mechanisms such as reinforcement learning (RL) and continuous fine-tuning are pivotal for enhancing model performance, adaptability, and alignment with human preferences. These techniques enable LLMs to autonomously refine their outputs, correct errors, and integrate new information over time.
Reinforcement Learning in LLMs
Reinforcement learning involves training models to make decisions by interacting with an environment and receiving feedback in the form of rewards or penalties. In the context of LLMs, RL is utilized to fine-tune models based on human feedback, a process known as Reinforcement Learning from Human Feedback (RLHF). This approach allows LLMs to generate responses that are more aligned with human expectations and preferences.
A commonly used algorithm in RLHF is Proximal Policy Optimization (PPO), which balances exploration and exploitation to optimize the model's performance. PPO has been effectively applied to fine-tune LLMs, enhancing their ability to generate human-like text.
Continuous Fine-Tuning in LLMs
Continuous fine-tuning refers to the ongoing process of updating an LLM's parameters as new data becomes available. This approach is essential for maintaining the model's relevance and performance over time, especially in dynamic environments where language usage and information evolve.
By continuously fine-tuning LLMs, developers can ensure that these models remain accurate and effective in the face of evolving language patterns and information.
Integrating Reinforcement Learning and Continuous Fine-Tuning
Combining reinforcement learning with continuous fine-tuning offers a robust framework for developing LLMs that are both adaptable and aligned with human preferences. This integrated approach allows models to learn from human feedback while continuously updating their knowledge base, leading to more accurate and contextually relevant outputs.
For instance, a study titled "Teaching Large Language Models to Reason with Reinforcement Learning" explores the performance of various algorithms that learn from feedback, such as Expert Iteration and Proximal Policy Optimization (PPO), in improving LLM reasoning capabilities. The research investigates both sparse and dense rewards provided to the LLM, highlighting the effectiveness of combining reinforcement learning with continuous fine-tuning in enhancing model performance.
Furthermore, the "Survey on Large Language Model-Enhanced Reinforcement Learning" provides a comprehensive review of existing literature on LLM-enhanced RL, summarizing its characteristics compared to conventional RL methods. This survey clarifies the research scope and directions for future studies, emphasizing the importance of integrating reinforcement learning with continuous fine-tuning to augment LLM capabilities.
Code Example: Fine-Tuning an LLM with PPO
To illustrate the application of reinforcement learning in fine-tuning LLMs, consider the following Python code snippet using the Hugging Face Transformers library and the PPO algorithm:
In this example, we load a pre-trained GPT-2 model and tokenizer, configure the PPO algorithm, and fine-tune the model on the provided training data. This process allows the model to learn from human feedback and adapt its responses accordingly.
In summary, reinforcement learning and continuous fine-tuning are critical techniques in the development of Large Language Models. By leveraging these methodologies, AI systems can achieve higher performance, better alignment with human preferences, and greater adaptability to new tasks and data distributions. The ongoing research and application of these techniques continue to drive advancements in AI, leading to more intelligent and versatile models capable of addressing a wide range of challenges.
In the development and deployment of artificial intelligence (AI) systems, the concept of "slow thinking"—a deliberate, reflective, and methodical approach to decision-making—holds significant ethical implications. This approach contrasts with "fast thinking," which is rapid, intuitive, and often subconscious. Integrating slow thinking into AI design and operation can enhance ethical considerations, particularly concerning responsibility in decision-making.
AI systems, especially those employing machine learning algorithms, are increasingly involved in complex decision-making processes across various sectors, including healthcare, finance, and criminal justice. The ethical concerns associated with AI decision-making are multifaceted. One primary concern is the potential for AI to perpetuate or even exacerbate existing biases present in training data. If an AI system is trained on biased data, it may produce biased outcomes, leading to unfair treatment of certain groups. This issue underscores the necessity for careful and thoughtful consideration during the design and training phases of AI development.
Another ethical consideration is the transparency of AI decision-making processes. Many AI models, particularly deep learning algorithms, operate as "black boxes," making it challenging to understand how they arrive at specific decisions. This lack of transparency can erode trust among users and stakeholders, as individuals may be hesitant to accept decisions made by systems they do not fully comprehend. Implementing slow thinking principles can aid in developing more interpretable AI models, thereby enhancing transparency and trust.
The delegation of decision-making to AI systems also raises questions about accountability. When an AI system makes a decision that leads to harm or injustice, determining who is responsible—the developers, the users, or the AI itself—can be complex. Ethical frameworks that incorporate slow thinking advocate for clear accountability structures, ensuring that human oversight remains integral to AI operations. This approach aligns with the perspective that human judgment should not be entirely replaced by AI, as highlighted by Michael Sandel, who emphasizes the importance of human judgment in the face of new technologies.
Moreover, the integration of slow thinking into AI development can mitigate the risk of over-reliance on AI systems. Excessive dependence on AI for decision-making may diminish individuals' critical thinking skills and their ability to make independent judgments. By promoting a more thoughtful and deliberate approach to AI integration, slow thinking encourages users to maintain active engagement and critical evaluation of AI outputs. This balance is crucial in preventing the erosion of human agency and ensuring that AI serves as a tool that complements human decision-making rather than replacing it.
Incorporating slow thinking into AI ethics also involves addressing the potential for AI to influence human behavior subtly. AI systems can be designed to nudge individuals toward certain behaviors or decisions, raising ethical concerns about manipulation and autonomy. A slow thinking approach advocates for transparency in AI design and the implementation of safeguards to prevent undue influence, ensuring that AI systems support informed and autonomous decision-making. This perspective aligns with discussions on the ethical use of AI, emphasizing the need for measured and deliberate thinking in AI applications.
To illustrate the application of slow thinking principles in AI development, consider the following Python code snippet, which demonstrates a methodical approach to training a machine learning model with an emphasis on ethical considerations:
In this example, the code follows a structured and thoughtful process:
Data Loading and Preprocessing: The dataset is loaded, and missing values are addressed, ensuring data quality.
Feature Selection: Relevant features are identified, and the target variable is separated, promoting transparency in the modeling process.
Data Splitting: The data is divided into training and testing sets to evaluate the model's performance objectively.
Standardization: Features are standardized to ensure fair treatment of all variables, reducing bias.
Model Training and Evaluation: A logistic regression model is trained and evaluated, with performance metrics provided to assess accuracy and fairness.
This methodical approach exemplifies how slow thinking principles can be applied in AI development to promote ethical practices, transparency, and accountability.
In conclusion, integrating slow thinking into AI development and deployment is essential for addressing ethical concerns related to responsibility in decision-making. By adopting a deliberate and reflective approach, stakeholders can ensure that AI systems are designed and operated in ways that are fair, transparent, and aligned with human values. This integration fosters trust and accountability, which are crucial for the responsible advancement of AI technologies.
Conclusion
Integrating the principles of "slow thinking" into artificial intelligence (AI) development offers a pathway to creating more robust, ethical, and effective AI systems. Slow thinking, characterized by deliberate, reflective, and methodical decision-making, contrasts with the rapid, intuitive processes of "fast thinking." Applying this approach to AI can lead to several key benefits:
Enhanced Reasoning and Problem-Solving
By adopting slow thinking, AI systems can engage in more thorough analysis, leading to deeper insights and more thoughtful decision-making. This methodical approach allows AI to tackle complex problems with greater accuracy and reliability. For instance, Google's experimental AI model, Gemini 2.0 Flash Thinking, demonstrates this capability by outlining its thought process when answering complex questions, thereby enhancing its reasoning abilities.
Improved Transparency and Trust
Slow thinking in AI development promotes transparency, as AI systems can articulate their reasoning processes. This transparency builds trust among users and stakeholders, as they can understand how decisions are made. OpenAI's o1 model exemplifies this by providing visibility into its thought process, allowing users to comprehend the reasoning behind its responses.
Ethical Decision-Making
Integrating slow thinking into AI encourages ethical considerations in decision-making. By reflecting on potential outcomes and consequences, AI systems can make decisions that align with human values and ethical standards. This approach helps mitigate biases and ensures that AI actions are justifiable and responsible. The concept of "long thinking" in AI, as discussed by Jensen Huang, CEO of Nvidia, highlights the importance of deliberate reasoning in achieving ethical AI behavior.
Adaptability and Continuous Improvement
Slow thinking enables AI systems to adapt to new information, correct mistakes, and refine their outputs over time. This adaptability is crucial for AI to remain effective in dynamic environments. Techniques such as reinforcement learning and continuous fine-tuning exemplify this principle. For example, in reinforcement learning, an AI agent learns optimal behaviors through trial and error, adjusting its actions based on feedback to improve performance.
Code Example: Reinforcement Learning for Adaptive Behavior
Below is a Python code example demonstrating a simple reinforcement learning setup using Q-learning, a fundamental algorithm in this domain:
In this example, the AI agent learns to navigate through states by balancing exploration (trying new actions) and exploitation (choosing actions that have previously yielded high rewards). This balance is crucial for the agent to adapt and improve its behavior over time.
Balancing Exploration and Exploitation
A critical aspect of slow thinking in AI is the balance between exploration and exploitation. Exploration involves trying new actions to discover their effects, while exploitation focuses on utilizing known actions that yield high rewards. Striking the right balance ensures that AI systems can adapt to new situations and refine their behavior, leading to more robust and effective performance. Research indicates that incorporating both fast and slow thinking processes can enhance AI agents' efficiency and adaptability.
In summary, applying slow thinking principles to AI development fosters enhanced reasoning, improved transparency, ethical decision-making, adaptability, and a balanced approach to exploration and exploitation. These elements collectively contribute to building more robust AI systems capable of thoughtful, responsible, and effective performance.
Integrating the principles of "slow thinking" into the development of Large Language Models (LLMs) holds significant promise for advancing AI systems toward greater intelligence and adaptability. Slow thinking, as delineated by Daniel Kahneman in his seminal work "Thinking, Fast and Slow," involves deliberate, reflective, and methodical decision-making processes. Applying these principles to LLMs can enhance their reasoning capabilities, ethical decision-making, and adaptability to new information.
Recent discussions in the AI community underscore the necessity of evolving AI models to incorporate more sophisticated reasoning processes. Ilya Sutskever, co-founder of OpenAI, has highlighted the impending shift from traditional pre-training methods to models that emphasize "agentic" reasoning. He suggests that future AI systems will need to transition from mere pattern recognition to step-by-step processing, akin to human thinking, to achieve more robust and adaptable behaviors.
This evolution aligns with the concept of slow thinking, which emphasizes careful deliberation and logical reasoning. By integrating slow thinking principles, LLMs can move beyond rapid, intuitive responses to more thoughtful and contextually appropriate outputs. This shift could lead to AI systems that not only generate human-like text but also understand and reason about the content they produce, thereby enhancing their utility and reliability.
Moreover, the integration of slow thinking into LLMs can address current limitations observed in AI systems, such as the tendency to produce erroneous or unverified information—a phenomenon known as "hallucination." By adopting a more methodical approach to information processing, LLMs can improve the accuracy and reliability of their outputs, thereby increasing user trust and satisfaction.
To illustrate the potential of combining slow thinking with LLMs, consider the following Python code snippet that demonstrates a simple implementation of a deliberative reasoning process within an AI system:
In this example, the DeliberativeAI class simulates a slow thinking process by retrieving relevant information from a knowledge base and deliberating over it to form a reasoned response. This approach contrasts with fast, heuristic-based methods by emphasizing careful consideration and logical reasoning.
Looking ahead, the integration of slow thinking principles into LLMs could lead to AI systems that are not only more intelligent and adaptable but also more ethical and transparent. By emulating human-like deliberative processes, LLMs can better understand context, recognize nuances, and make decisions that align with human values and ethical standards. This advancement could have profound implications across various domains, including healthcare, education, and customer service, where thoughtful and context-aware AI interactions are crucial.
In summary, the future potential of combining slow thinking principles with LLMs lies in creating AI systems that are more intelligent, adaptable, and ethically aligned. By moving beyond rapid, intuitive responses to more deliberate and reasoned processes, LLMs can better serve human needs and contribute positively to society.
As we stand on the precipice of a new era in artificial intelligence (AI), the integration of "slow thinking" principles into Large Language Models (LLMs) presents a compelling avenue for advancing AI systems toward greater intelligence, adaptability, and ethical alignment. This approach emphasizes deliberate, reflective, and methodical decision-making processes, contrasting with the rapid, intuitive responses characteristic of "fast thinking." By embedding these principles into AI development, we can foster systems that not only generate human-like text but also understand and reason about the content they produce, thereby enhancing their utility and reliability.
Recent discussions in the AI community underscore the necessity of evolving AI models to incorporate more sophisticated reasoning processes. Ilya Sutskever, co-founder and former chief scientist of OpenAI, highlighted significant shifts in AI development, predicting the end of the pre-training phase due to the depletion of novel data sources. He suggests that future AI models will need to focus on being "agentic" and capable of reasoning, transitioning from pattern recognition to step-by-step processing akin to human thinking. This evolution aligns with the concept of slow thinking, which emphasizes careful deliberation and logical reasoning. By integrating slow thinking principles, LLMs can move beyond rapid, intuitive responses to more thoughtful and contextually appropriate outputs. This shift could lead to AI systems that are not only more intelligent and adaptable but also more ethical and transparent. By emulating human-like deliberative processes, LLMs can better understand context, recognize nuances, and make decisions that align with human values and ethical standards. This advancement could have profound implications across various domains, including healthcare, education, and customer service, where thoughtful and context-aware AI interactions are crucial.
However, as we advance, it is imperative to address the ethical considerations inherent in AI development. Ensuring fairness and mitigating bias are paramount, as AI systems trained on biased data can perpetuate and amplify societal inequalities. Transparency and accountability are also critical, as understanding how AI systems make decisions is essential for trust and responsible deployment. Moreover, the potential for AI to automate research and development processes raises concerns about the pace of technological progress and the need for appropriate oversight. Ethical considerations in AI include bias and discrimination, transparency and accountability, creativity and ownership, social manipulation, and the role of human judgment in decision-making. Addressing these challenges requires a concerted effort from researchers, policymakers, and society at large to ensure that AI technologies are developed and deployed responsibly.
In conclusion, the future of AI research and development hinges on our ability to integrate slow thinking principles into LLMs, fostering systems that are intelligent, adaptable, and ethically aligned. This endeavor requires a balanced approach, combining technological innovation with ethical considerations, to ensure that AI serves humanity's best interests. As we continue to explore the potential of AI, let us remain vigilant stewards of this powerful technology, guiding its development toward outcomes that are beneficial, fair, and just for all.
Press contact
Timon Harz
oneboardhq@outlook.com
Other posts





Company
About
Blog
Careers
Press
Legal
Privacy
Terms
Security