Timon Harz
December 20, 2024
Scaling Language Model Evaluation: How BABILong Handles Millions of Tokens for Enhanced Performance
Exploring BABILong: A Benchmark to Test Language Models' Ability to Handle Long Contexts and Complex Reasoning Tasks
Large Language Models (LLMs) and neural architectures have made significant strides, especially in handling longer contexts, which has profound implications for a variety of applications. The ability to process and generate more contextually relevant responses has been enhanced, allowing models to leverage comprehensive information for more accurate outcomes. This improvement has also boosted in-context learning, enabling models to follow complex instructions and utilize a larger set of examples. However, evaluation benchmarks have not kept pace with these advancements. Tools like Longbench and L-Eval still cap at 40,000 tokens, while modern models are now capable of processing hundreds of thousands, or even millions, of tokens, creating a disconnect between model capabilities and the evaluation methods used to assess them.
The evolution of long-context evaluation began with the Long Range Arena (LRA), which handled sequences up to 16,000 tokens but focused on specialized tasks like ListOps and Byte-Level operations. This limitation led to the development of more comprehensive benchmarks such as LongBench, Scrolls, and L-Eval, which tackle diverse tasks like summarization and code completion, supporting token lengths between 3,000 and 60,000. More recent benchmarks, like LongAlign and LongICLBench, focus on in-context learning and instructions. Datasets like InfinityBench, NovelQA, and ChapterBreak have pushed token limits further, supporting up to 636,000 tokens across domains like Wikipedia articles and movie scripts.
Researchers from AIRI, Moscow, and the London Institute for Mathematical Sciences have introduced BABILong, a groundbreaking benchmark designed to evaluate language models’ reasoning abilities across extremely long documents. This framework includes 20 distinct reasoning tasks, such as fact chaining, deduction, and list handling, using books from the PG19 corpus. With the ability to test sequences up to 50 million tokens, BABILong is uniquely suited for evaluating next-gen models. Early tests reveal current models' limitations, utilizing only 10-20% of the available context. While Retrieval-Augmented Generation methods reach 60% accuracy on single-fact questions, models like Mamba and Recurrent Memory Transformers (ARMT) show superior performance, with ARMT handling sequences up to 50 million tokens.
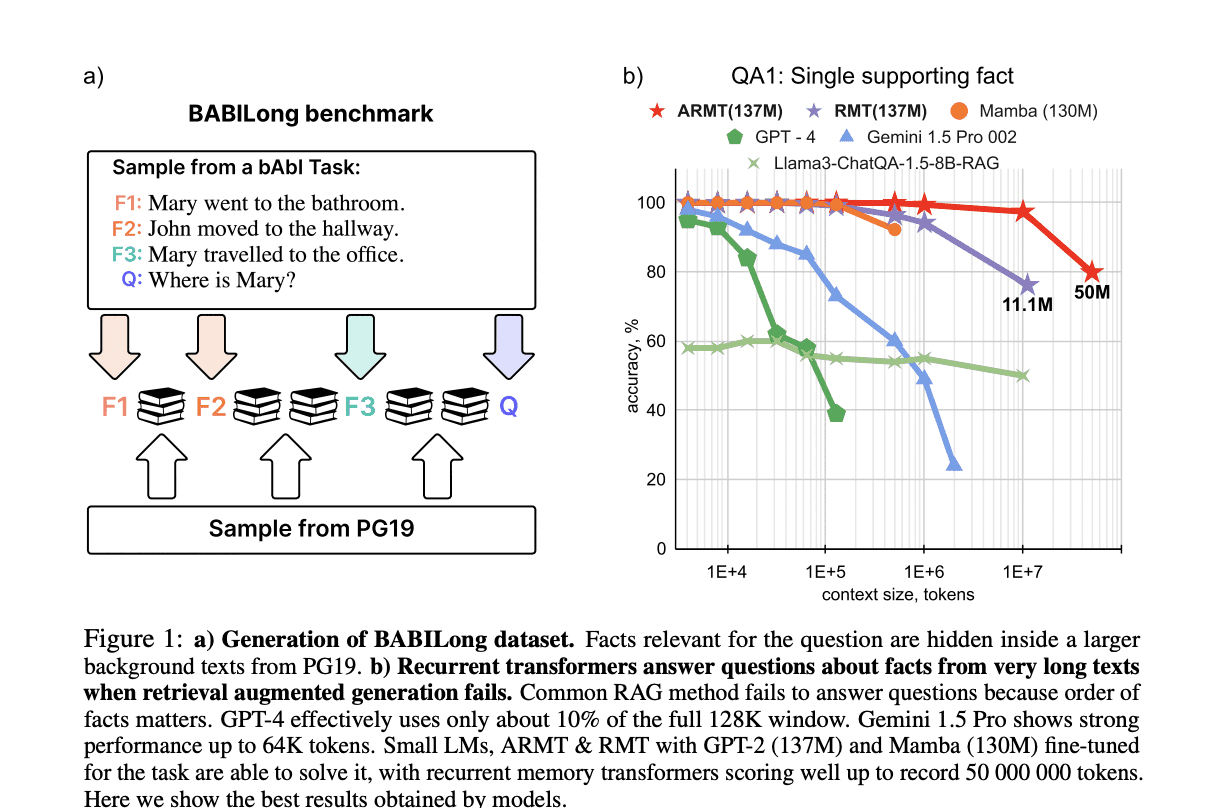
The BABILong benchmark uses a unique approach to assess language models' ability to process extended contexts. By embedding task-specific sentences within irrelevant text from the PG19 dataset, it simulates real-world scenarios where critical information is scattered across long documents. This method allows for unlimited context scaling, enabling the evaluation of models with context windows spanning millions of tokens. Building on the original bAbI tasks, which test basic reasoning through simulated interactions, BABILong evaluates a range of cognitive skills, including spatial reasoning, temporal understanding, and deduction. This synthetic design also safeguards against training data contamination, a common issue in traditional NLP benchmarks.

A thorough analysis of language models' context utilization reveals significant limitations in their ability to handle long sequences. Testing across multiple question-answering tasks shows that most current LLMs effectively use only 10-20% of their advertised context window. Of the 34 models tested, only 23 met the benchmark of 85% accuracy on basic tasks without distractor text. Performance varies widely among architectures, with models like GPT-4 and Llama-3.1-70b maintaining effectiveness up to 16K tokens, while most struggle beyond 4K tokens. Recent advancements show promising improvements, with Qwen-2.5 models leading in the open LLM space. The evaluation also explored alternatives such as Retrieval-Augmented Generation (RAG) and fine-tuned models. While RAG showed limited success, fine-tuned recurrent memory models, especially ARMT, demonstrated exceptional capabilities, processing sequences up to 50 million tokens with consistent performance.
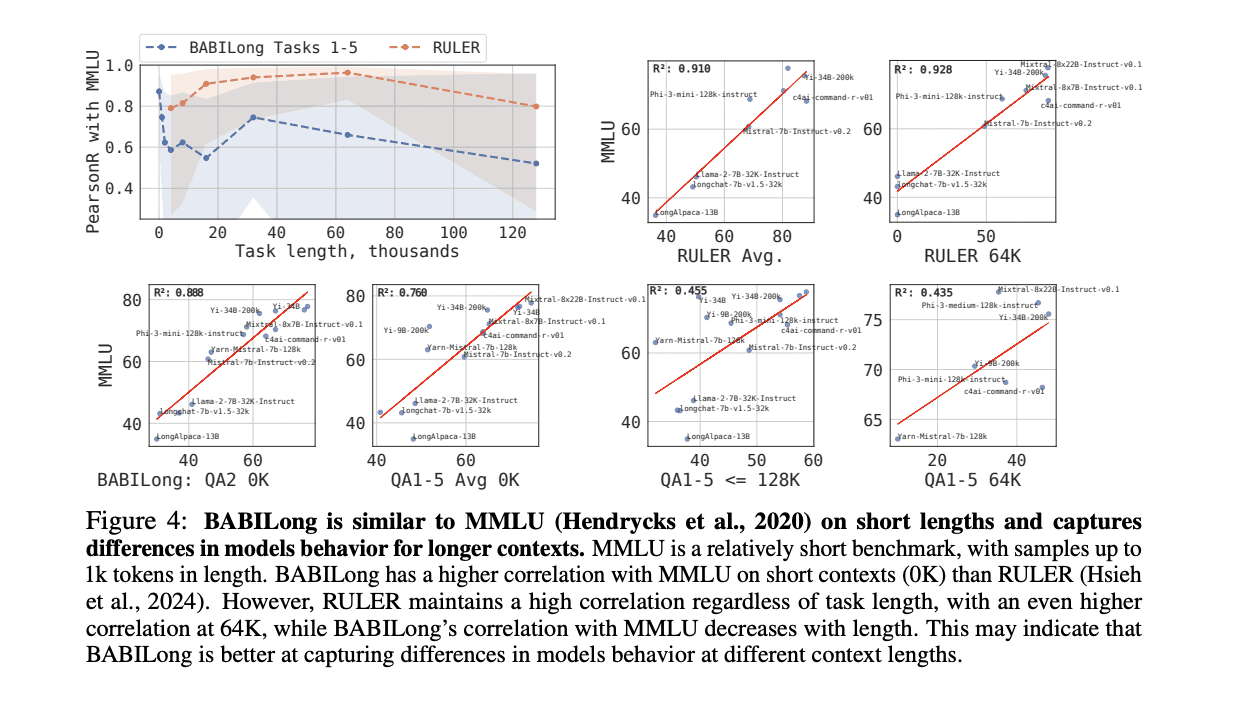
BABILong marks a significant step forward in evaluating the long-context capabilities of language models, offering a unique combination of scalability and diverse reasoning tasks. The benchmark's flexible design supports testing sequences ranging from 0 to 10 million tokens, with precise control over document length and fact placement. Testing revealed that current models, including advanced systems like GPT-4 and Gemini 1.5 Pro, effectively utilize only 5-25% of their input context. While newer models like Llama-3.1 and Qwen-2.5 show improvements, they still face limitations. Fine-tuning experiments highlighted that even smaller models like RMT and ARMT (137M parameters) can handle BABILong tasks effectively, with ARMT notably processing sequences up to 50 million tokens, far exceeding Mamba’s practical limit of 128K tokens.
Press contact
Timon Harz
oneboardhq@outlook.com
Other posts





Company
About
Blog
Careers
Press
Legal
Privacy
Terms
Security