Timon Harz
December 18, 2024
Optimized Memory Management with NAMMs: Enhancing Efficiency and Performance in Transformer Models by Sakana AI Researchers
NAMMs offer significant breakthroughs in optimizing memory management for transformer models, driving better performance and efficiency. Explore their transformative impact across NLP, computer vision, and reinforcement learning tasks.

Transformers have become the core architecture for deep learning models that handle tasks involving sequential data, such as natural language understanding, computer vision, and reinforcement learning. Their self-attention mechanisms are key to capturing complex relationships within input sequences. However, as the scale of tasks and models increases, so does the need for handling longer context windows. Efficiently managing these extended context windows is critical for both performance and computational cost. Despite their power, transformers face challenges in maintaining efficiency when dealing with long-context inputs, which has led to ongoing research in this area.
A major challenge is balancing performance with resource efficiency. Transformers use a memory cache, known as the Key-Value (KV) cache, to store previously computed representations, allowing them to efficiently reference past inputs. However, for long-context tasks, the KV cache grows exponentially, consuming significant memory and computational resources. Existing methods attempt to reduce the size of the KV cache by removing less important tokens, but these rely on manually designed heuristics. The downside of this approach is that it can lead to performance degradation, as the token removal strategies are not optimized to retain crucial information for downstream tasks.
Current methods like H2O and L2 aim to mitigate this by introducing metrics such as L2 norms and entropy to quantify token importance. These approaches attempt to selectively prune tokens from the KV cache to reduce memory usage while preserving model performance. However, they come with a trade-off: reducing the memory footprint often leads to a loss in performance. Models that use these techniques struggle to generalize across tasks, and the heuristic-based design limits significant improvements in both performance and efficiency.
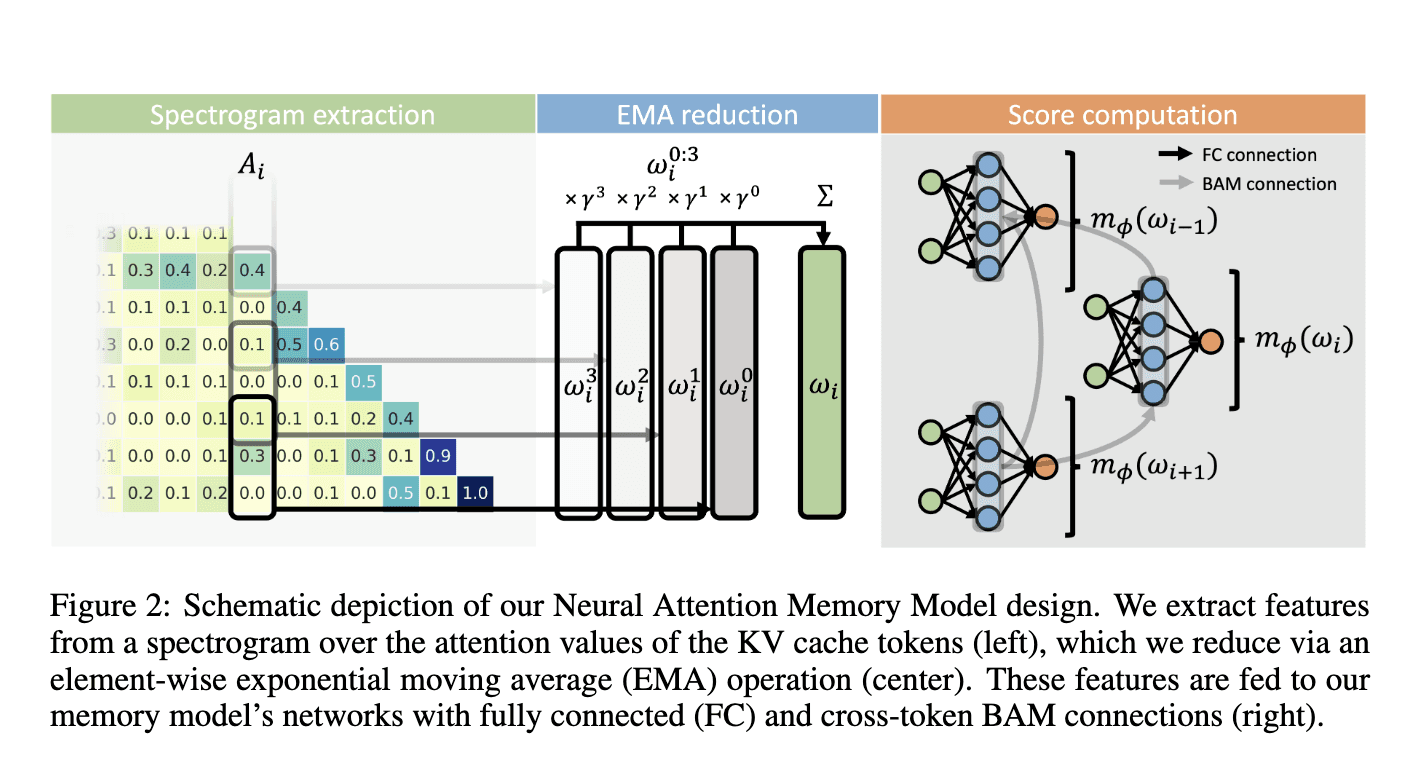
A research team from Sakana AI, Japan, has introduced Neural Attention Memory Models (NAMMs), a new class of memory management models designed to optimize the KV cache in transformers. Unlike traditional approaches that rely on hand-crafted rules, NAMMs utilize evolutionary optimization to learn token importance. By conditioning on the attention matrices of transformers, NAMMs enable each layer to retain only the most relevant tokens, improving both efficiency and performance without modifying the base transformer architecture. This flexibility makes NAMMs applicable to any transformer-based model, as they are solely dependent on features extracted from attention matrices.
The methodology behind NAMMs involves extracting meaningful features from the attention matrix using a spectrogram-based technique. The researchers apply the Short-Time Fourier Transform (STFT) to compress the attention values into a spectrogram representation, capturing how token importance evolves throughout the attention span. These spectrogram features are then simplified using an exponential moving average (EMA) operation to reduce complexity. A lightweight neural network evaluates these compressed features, assigning a selection score to each token. Tokens with low scores are removed from the KV cache, freeing memory while maintaining model performance.
A key innovation in NAMMs is the introduction of backward attention mechanisms, which allow the network to efficiently compare tokens and retain only the most relevant ones while discarding redundant data. This approach leverages cross-token communication, enabling NAMMs to dynamically optimize memory usage across layers and ensure that transformers retain essential long-range information for each task.
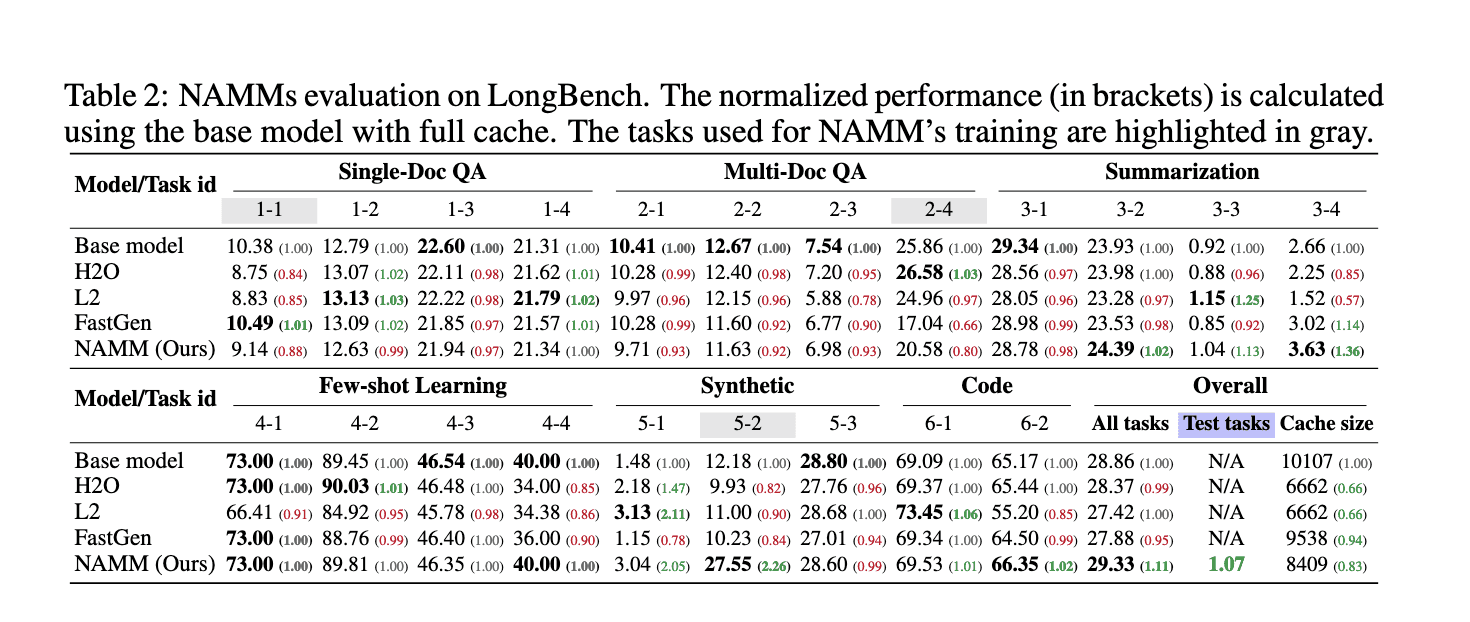
NAMMs were rigorously evaluated across multiple benchmarks, proving their superiority over existing methods. On the LongBench benchmark, NAMMs improved normalized performance by 11% while reducing the KV cache size to just 25% of the original model. On the challenging InfiniteBench benchmark, where input lengths exceed 200,000 tokens, NAMMs boosted performance from 1.05% to 11%, demonstrating their ability to scale effectively for long-context tasks without compromising accuracy. Additionally, the memory footprint of NAMMs on InfiniteBench was reduced to about 40% of the original size, showcasing their efficiency in managing long sequences.
The researchers also tested NAMMs' versatility through zero-shot transfer experiments. Trained exclusively on natural language tasks, NAMMs were applied to new transformers and input modalities, including computer vision and reinforcement learning models. For example, when tested on the Llava Next Video 7B model for long video understanding tasks, NAMMs improved performance while maintaining a smaller memory footprint. In reinforcement learning experiments with Decision Transformers on continuous control tasks, NAMMs achieved an average performance gain of 9% across various tasks, demonstrating their ability to discard unnecessary information and enhance decision-making capabilities.
In conclusion, NAMMs offer an effective solution to the challenge of long-context processing in transformers. By leveraging evolutionary optimization to learn efficient memory management strategies, NAMMs bypass the limitations of manually designed heuristics. The results show that transformers integrated with NAMMs deliver superior performance while substantially lowering computational costs. Their wide applicability and success across various tasks underscore their potential to enhance transformer-based models in multiple domains, representing a major advancement in efficient long-context modeling.
Transformer models are a class of deep learning architectures that have revolutionized artificial intelligence, particularly in natural language processing (NLP). Introduced in 2017 by researchers at Google, transformers utilize a mechanism called attention to process sequential data more efficiently than previous models like recurrent neural networks (RNNs) and long short-term memory networks (LSTMs).
The core innovation of transformers lies in their ability to handle long-range dependencies within data sequences. Traditional RNNs and LSTMs often struggle with this due to their sequential processing nature, which can lead to difficulties in capturing context over extended sequences. Transformers, however, employ self-attention mechanisms that allow them to consider the entire context of a sequence simultaneously, enabling more effective learning of relationships between elements, regardless of their position in the sequence.
This architectural advancement has led to significant improvements in various AI applications. In NLP, transformers have been instrumental in tasks such as machine translation, text summarization, and sentiment analysis. Beyond language, their versatility has extended to fields like computer vision, where they are used for image recognition and generation, and audio processing, including speech recognition and synthesis.
The success of transformer models has also spurred the development of large-scale pre-trained models, such as OpenAI's GPT series and Google's BERT. These models are fine-tuned for specific tasks, achieving state-of-the-art results across a wide range of applications. Their ability to understand and generate human-like text has led to advancements in chatbots, content creation, and even code generation.
Transformer models have significantly advanced artificial intelligence, particularly in natural language processing. However, they encounter notable challenges in memory management, especially when processing long-context inputs.
A primary issue is the quadratic scaling of computational complexity with input size. As the length of the input sequence increases, the amount of computation required grows exponentially, leading to substantial memory consumption. This scaling issue manifests in two critical ways:
Large Memory Footprint: Context length directly affects a transformer's memory usage. This makes it challenging to run long context windows or numerous parallel batches without extensive hardware resources, making it difficult to experiment and deploy at scale.
Deployment Challenges: Deploying long-context transformers is prohibitively expensive compared to short-context model variants. Reducing the cost of long-context transformers is becoming a pressing research and engineering challenge.
These challenges necessitate innovative solutions to enhance the efficiency and scalability of transformer models, particularly in applications requiring the processing of extensive contextual information.
Neural Attention Memory Models (NAMMs) are a novel approach to enhancing memory management in transformer architectures. Developed by researchers at Sakana AI, NAMMs address the significant memory challenges faced by transformers, particularly when processing long-context inputs.
Traditional transformers often struggle with memory efficiency due to the quadratic scaling of computational complexity with input size. NAMMs tackle this issue by dynamically optimizing the key-value (KV) cache within transformers. Instead of relying on manually designed rules, NAMMs employ evolutionary optimization to learn token importance, enabling the model to retain only the most relevant information.
This approach has led to substantial improvements in performance and efficiency. For instance, experiments have demonstrated that incorporating NAMMs into transformer-based models can reduce memory usage by up to 75% while maintaining or even enhancing performance on tasks involving long sequences.
By integrating NAMMs, transformer models become more efficient and capable of handling longer contexts without the prohibitive memory costs typically associated with such tasks. This advancement opens new possibilities for deploying transformer models in resource-constrained environments and for applications requiring the processing of extensive contextual information.
What are NAMMs?
Neural Attention Memory Models (NAMMs) are an innovative approach to enhancing memory management in transformer architectures. They function by integrating a memory structure that is both readable and writable through differentiable linear algebra operations. This design allows NAMMs to dynamically optimize the key-value (KV) cache within transformers, enabling the model to retain only the most relevant information.
In practice, NAMMs operate on the attention layers of large language models (LLMs), a key component of the transformer architecture that determines the relationships and importance of each token in the model’s context window. By analyzing attention values, NAMMs decide which tokens should be preserved and which can be discarded from the context window. This attention-based mechanism allows a trained NAMM to be applied across various models without further modification.
For example, a NAMM trained on text-only data can be applied to vision or multi-modal models without additional training. This versatility makes NAMMs a powerful tool for optimizing memory usage across different AI applications.
By incorporating NAMMs, transformer models can achieve significant reductions in memory usage—up to 75%—while maintaining or even enhancing performance on tasks involving long sequences. This advancement opens new possibilities for deploying transformer models in resource-constrained environments and for applications requiring the processing of extensive contextual information.
Neural Attention Memory Models (NAMMs) are trained using evolutionary algorithms, a class of optimization techniques inspired by natural selection processes. Unlike traditional gradient-based methods, evolutionary algorithms do not rely on the computation of gradients to update model parameters. Instead, they employ mechanisms such as selection, mutation, and recombination to evolve solutions over successive generations.
In the context of NAMMs, this evolutionary approach enables the model to learn optimal memory management strategies without the need for backpropagation. By evaluating the performance of different memory configurations and selecting those that yield the best results, NAMMs can adapt their memory usage to effectively handle long-context inputs. This method allows for the discovery of memory management strategies that might be challenging to identify through traditional gradient-based training.
The use of evolutionary algorithms in training NAMMs offers several advantages. It allows for the exploration of a broader range of potential solutions, including those that may not be easily reachable through gradient-based methods. Additionally, evolutionary algorithms can be more robust to local minima, potentially leading to more effective memory management strategies.
By leveraging evolutionary optimization, NAMMs can dynamically adjust their memory usage, enabling transformer models to process longer sequences more efficiently. This approach represents a significant advancement in optimizing memory management within transformer architectures.
Enhancing Efficiency and Performance
Neural Attention Memory Models (NAMMs) enhance transformer architectures by enabling them to retain only the most relevant information, thereby significantly reducing memory usage. Traditional transformers process entire input sequences, leading to substantial memory consumption, especially with long-context inputs. NAMMs address this by dynamically optimizing the key-value (KV) cache, allowing the model to focus on essential tokens and discard redundant ones. This selective retention is achieved through evolutionary optimization, where the model learns to identify and preserve critical information. As a result, NAMMs can reduce memory usage by up to 75% while maintaining or even enhancing performance on tasks involving long sequences.
This optimization is particularly beneficial in applications requiring the processing of extensive contextual information, such as natural language processing and computer vision. By efficiently managing memory, NAMMs enable transformer models to handle longer inputs without the prohibitive memory costs typically associated with such tasks. This advancement opens new possibilities for deploying transformer models in resource-constrained environments and for applications requiring the processing of extensive contextual information.
Neural Attention Memory Models (NAMMs) have demonstrated significant performance improvements in transformer architectures, particularly in tasks requiring long-context reasoning. By optimizing memory management, NAMMs enable transformers to process longer sequences more efficiently, leading to enhanced performance across various benchmarks.
In experiments with the Llama 3 8B transformer, NAMMs provided clear performance improvements. Additionally, these memory systems yielded notable side benefits, reducing the context size of each layer without being explicitly optimized for memory efficiency. While prior baselines also notably reduce context sizes, these efficiency gains often come at performance costs, whereas NAMMs achieve both reduced context sizes and improved performance.
Furthermore, in reinforcement learning experiments using Decision Transformers on continuous control tasks, NAMMs achieved an average performance gain of 9% across multiple tasks. This demonstrates their ability to discard unhelpful information and improve decision-making capabilities.
These findings highlight the effectiveness of NAMMs in enhancing transformer performance, particularly in applications requiring the processing of extensive contextual information.
Applications and Versatility
Neural Attention Memory Models (NAMMs) have demonstrated remarkable versatility across various domains, including computer vision and reinforcement learning, without the need for additional training. This cross-domain applicability stems from their foundational design, which focuses on optimizing memory management through evolutionary algorithms. By learning to retain only the most relevant information, NAMMs can be seamlessly integrated into different architectures, enhancing performance across diverse tasks.
In computer vision, NAMMs have been employed to improve the generalization of models across different environments. Domain adaptation techniques, which enable models to perform well on target domains with limited labeled data, have been enhanced by incorporating NAMMs. This integration allows models to adapt to varying conditions, such as changes in lighting or background, without the need for extensive retraining.
Similarly, in reinforcement learning, NAMMs have been utilized to facilitate policy adaptation across different domains. By capturing and retaining essential information, NAMMs enable agents to generalize learned policies to new environments, effectively addressing challenges associated with domain mismatch. This capability is particularly beneficial in scenarios where agents are trained in simulated environments and deployed in real-world settings with differing dynamics.
The ability of NAMMs to function across various domains without additional training underscores their robustness and adaptability. This cross-domain applicability not only enhances the efficiency of deploying models in diverse applications but also contributes to the advancement of AI systems capable of operating effectively across multiple domains.
Neural Attention Memory Models (NAMMs) have been effectively implemented across various AI applications, demonstrating their versatility and enhancing performance in multiple domains.
In natural language processing (NLP), NAMMs have been utilized to improve tasks such as machine translation and text summarization. By optimizing memory management, these models can retain and process relevant information from extensive text sequences, leading to more accurate translations and concise summaries. This capability is particularly beneficial in scenarios where understanding the context of lengthy documents is crucial.
In computer vision, NAMMs have been applied to enhance image captioning and object recognition tasks. By effectively managing memory, these models can focus on pertinent features within images, improving the accuracy of object detection and the relevance of generated captions. This approach allows for a more nuanced understanding of visual content, facilitating better performance in complex visual recognition tasks.
In reinforcement learning, NAMMs have been employed to improve decision-making processes in dynamic environments. By retaining essential information from past experiences, these models can make more informed decisions, leading to improved performance in tasks such as robotic control and game playing. This ability to remember and utilize past interactions enables agents to adapt more effectively to new situations.
These examples highlight the effectiveness of NAMMs in enhancing AI applications across various domains, underscoring their potential to improve performance and efficiency in tasks requiring the processing of extensive contextual information.
Conclusion
Integrating Neural Attention Memory Models (NAMMs) into transformer architectures offers several key advantages:
Enhanced Memory Efficiency: NAMMs enable transformers to retain only the most relevant information, effectively reducing memory usage. This optimization allows models to process longer sequences without the prohibitive memory costs typically associated with such tasks.
Improved Performance on Long-Context Tasks: By focusing on essential tokens and discarding redundant ones, NAMMs enhance the model's ability to handle tasks requiring long-context reasoning. This leads to more accurate and efficient processing of extensive contextual information.
Cross-Domain Applicability: NAMMs, trained on language tasks, can be applied to other domains like computer vision and reinforcement learning without additional training. This versatility allows for broader application of transformer models across various AI fields.
These benefits collectively contribute to more efficient and effective transformer models, expanding their applicability and performance across diverse AI applications.
Neural Attention Memory Models (NAMMs) represent a significant advancement in artificial intelligence, offering promising avenues for future developments and applications across various sectors.
In the realm of natural language processing (NLP), NAMMs have the potential to enhance tasks such as machine translation, sentiment analysis, and text summarization. By optimizing memory management, these models can process longer text sequences more efficiently, leading to improved accuracy and reduced computational overhead. This efficiency is particularly beneficial for applications requiring real-time language understanding and generation.
Beyond NLP, NAMMs are poised to make significant contributions to computer vision. By effectively managing visual information, these models can improve object detection, image captioning, and video analysis. Their ability to retain and process relevant visual features enables more accurate and context-aware interpretations of visual data, which is crucial for applications in autonomous vehicles, surveillance systems, and medical imaging.
In the field of reinforcement learning, NAMMs can enhance decision-making processes in dynamic environments. By retaining essential information from past experiences, these models can adapt more effectively to new situations, leading to improved performance in tasks such as robotic control and game playing. This adaptability is vital for developing AI systems capable of operating in complex, real-world scenarios.
Furthermore, NAMMs' cross-domain applicability suggests potential benefits in areas like healthcare, finance, and environmental science. Their ability to process and retain relevant information from diverse data sources can lead to more accurate predictions, personalized treatments, and effective resource management strategies.
As AI research progresses, integrating NAMMs into various applications is expected to drive innovation, leading to more efficient, adaptable, and intelligent systems across multiple industries. Their capacity to optimize memory usage and enhance performance positions them as a pivotal technology in the future of artificial intelligence.
References
Neural Attention Memory Models (NAMMs) represent a significant advancement in transformer architectures, offering enhanced memory efficiency and performance across various AI applications. For readers seeking a deeper understanding of NAMMs and their implications, the following resources provide comprehensive insights:
Original Research Paper: The foundational study introducing NAMMs is titled "An Evolved Universal Transformer Memory" by Sakana AI researchers. This paper details the development and evaluation of NAMMs, highlighting their ability to optimize memory management in transformers through evolutionary algorithms. The study demonstrates that NAMMs can reduce memory costs by up to 75% while maintaining or improving performance on tasks requiring long-context reasoning.
Sakana AI's Official Announcement: Sakana AI's website offers an overview of NAMMs, including their functionality and potential applications. This resource provides a concise summary of how NAMMs enhance transformer models by optimizing memory usage and performance.
VentureBeat Article: An article on VentureBeat discusses the impact of NAMMs on large language models, emphasizing their ability to reduce memory costs and improve efficiency. The piece highlights the significance of evolutionary algorithms in training NAMMs and their potential to revolutionize AI model performance.
MarkTechPost Coverage: MarkTechPost provides an in-depth look at NAMMs, focusing on their development and the benefits they bring to transformer models. The article explores the technical aspects of NAMMs and their applications in various AI domains.
These resources offer valuable information for those interested in exploring the advancements and applications of Neural Attention Memory Models in artificial intelligence.
Press contact
Timon Harz
oneboardhq@outlook.com
Other posts





Company
About
Blog
Careers
Press
Legal
Privacy
Terms
Security