Timon Harz
December 16, 2024
Nexa AI Unveils OmniAudio-2.6B: A High-Speed Audio Language Model Optimized for Edge Deployment
Nexa AI's OmniAudio-2.6B pushes the boundaries of audio processing, making it an ideal solution for edge devices. This high-performance model ensures rapid and efficient real-time audio analysis, even in constrained environments.
Audio Language Models (ALMs) are vital for applications like real-time transcription, translation, voice control, and assistive technologies. However, most existing models struggle with high latency, intensive computational needs, and dependence on cloud-based processing. These challenges hinder their use in edge deployment, where low latency, low power consumption, and localized processing are essential. For resource-constrained environments or scenarios with strict privacy requirements, large centralized models often prove impractical. Overcoming these limitations is crucial to unlocking the full potential of ALMs for edge devices.
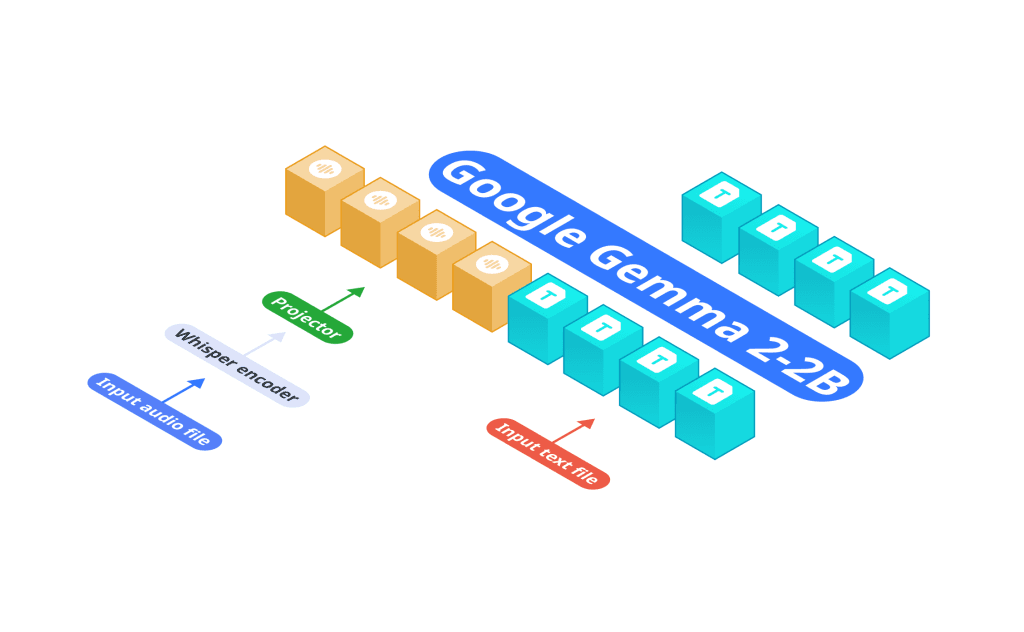
To address these issues, Nexa AI has introduced OmniAudio-2.6B, an advanced audio language model specifically designed for edge deployment. Unlike traditional approaches that separate Automatic Speech Recognition (ASR) and language models, OmniAudio-2.6B integrates Gemma-2-2b, Whisper Turbo, and a custom projector into a unified system. This streamlined architecture eliminates inefficiencies and delays caused by separate components, making it ideal for devices with limited computational power.
OmniAudio-2.6B delivers an efficient and practical solution for edge applications. By tailoring the model to the unique demands of edge environments, Nexa AI is advancing AI accessibility and driving innovation in resource-efficient audio processing.
Technical Details and Benefits
OmniAudio-2.6B is engineered for speed, efficiency, and edge-focused performance. Its architecture combines Gemma-2-2b, a refined LLM, and Whisper Turbo, a robust ASR system, seamlessly connected by a custom projector. This integration reduces latency, enhances efficiency, and ensures a smooth audio processing pipeline.
Key Highlights
Processing Speed: OmniAudio-2.6B delivers exceptional performance on a 2024 Mac Mini M4 Pro, achieving 35.23 tokens per second with FP16 GGUF format and 66 tokens per second with Q4_K_M GGUF format, powered by the Nexa SDK. By comparison, Qwen2-Audio-7B processes only 6.38 tokens per second on the same hardware—a 10.3x improvement.
Resource Efficiency: Its compact design minimizes reliance on cloud infrastructure, making it ideal for wearables, automotive systems, and IoT devices where power and bandwidth are limited.
Accuracy and Versatility: OmniAudio-2.6B excels in transcription, translation, and summarization tasks without compromising speed or efficiency, ensuring its adaptability for various use cases.
These advancements establish OmniAudio-2.6B as a high-performance, privacy-friendly solution for edge-based audio processing.
Performance Insights
Benchmark results highlight the standout capabilities of OmniAudio-2.6B. On a 2024 Mac Mini M4 Pro, the model processes up to 66 tokens per second, significantly outpacing Qwen2-Audio-7B’s 6.38 tokens per second.
This speed unlocks new possibilities for real-time audio applications. For instance:
Virtual Assistants: OmniAudio-2.6B enables faster, on-device responses, eliminating delays caused by cloud processing.
Healthcare: Real-time transcription and translation capabilities can improve communication and operational efficiency.
IoT Devices: Its edge-optimized design supports localized processing in resource-constrained environments.
Nexa AI: Pioneering Innovation in Advanced AI Models
Nexa AI has firmly established itself as a leader in the field of advanced AI technologies, with a strong focus on making AI more accessible and secure for real-world applications. Known for its cutting-edge work in on-device AI, Nexa has consistently delivered high-performance solutions tailored to the challenges of local inference. One of its standout contributions is the Nexa On-Device AI Hub, which houses over 700 optimized models spanning multiple domains, including NLP, computer vision, multimodal inputs, and audio processing. These models are fine-tuned to operate efficiently on resource-constrained devices such as smartphones and edge devices, leveraging advanced quantization techniques to strike a balance between size, quality, and performance.
Among its hallmark innovations is the Octopus series, a set of locally optimized models designed for high-speed processing without the need for constant cloud connectivity. This approach prioritizes user privacy while enabling seamless performance across tasks like speech-to-text, image analysis, and real-time audio processing. Nexa AI's partnership with PIN AI further highlights its commitment to embedding AI capabilities directly into user devices, creating an ecosystem that is private, responsive, and versatile.
By focusing on robust quantization methods and the deployment of GPU-accelerated local inference systems, Nexa AI ensures that its models perform efficiently even in constrained environments. This emphasis on delivering lightweight yet powerful AI tools has garnered significant adoption across industries, cementing Nexa's reputation as a reliable innovator in the AI space.
With its latest advancements, Nexa AI continues to pave the way for transformative applications of AI, maintaining a strong track record of adapting to evolving industry demands and user needs.
The OmniAudio-2.6B model represents a significant leap in edge-optimized AI solutions, particularly in the context of deploying large language models (LLMs) in resource-constrained environments. This model showcases advanced capabilities in audio and multimodal processing while balancing computational efficiency with performance, making it ideal for edge applications like autonomous systems, real-time data processing, and on-device analytics.
Key Advantages of OmniAudio-2.6B
Edge-First Optimization: OmniAudio-2.6B is designed to operate seamlessly on hardware-limited devices, employing techniques like model quantization and pruning. These approaches significantly reduce the memory and computational requirements while maintaining accuracy. For example, quantization into formats like INT8 or INT4 can lower memory usage without a severe drop in model precision, enabling inference on commodity hardware.
Real-Time Applications: OmniAudio-2.6B shines in scenarios requiring real-time processing. Whether used for audio analysis, transcription, or multimodal interactions combining audio with other data types like video or text, it ensures low-latency responses—a crucial feature for applications like smart home devices, robotics, and mobile platforms.
Integration and Versatility: Its architecture allows easy integration into existing AI pipelines. Paired with frameworks like LangChain or platforms like Hugging Face's model hub, OmniAudio-2.6B supports tasks ranging from conversational AI to complex audio data summarization. This aligns with emerging trends in deploying LLMs at the edge for real-time insights without relying on cloud connectivity.
Robustness in Multimodal Use Cases: Similar to other edge-oriented models deployed on hardware like NVIDIA IGX Orin, OmniAudio-2.6B can handle complex multimodal tasks, such as extracting insights from both audio streams and related text-based queries. This capability is increasingly valuable in domains like healthcare (e.g., summarizing medical consultations) and industry (e.g., analyzing sensor data).
Positioning as an Edge Solution
OmniAudio-2.6B is a step ahead in the evolving landscape of edge AI. Its design leverages innovations in memory management, such as the use of lightweight quantized formats, to achieve impressive performance metrics on GPUs with limited memory budgets. For instance, running a large model like this with 4-bit precision allows it to fit within 35GB of memory, making it deployable on GPUs like NVIDIA's RTX A6000 or similar setups.
This model stands as an example of how high-performance LLMs can move beyond traditional cloud dependencies to power next-gen edge solutions that are cost-effective, private, and efficient. With OmniAudio-2.6B, organizations can unlock new capabilities for audio-based insights and decision-making in environments previously considered infeasible for LLM deployment.
Key Features of OmniAudio-2.6B
The model's performance exemplifies cutting-edge edge intelligence capabilities, merging high-speed processing with efficiency tailored for resource-constrained environments. Modern edge devices integrate AI processing to reduce latency and reliance on cloud infrastructure. This paradigm, known as edge intelligence, enables faster responses for applications like image recognition, object detection, and real-time decision-making.
Recent advancements include the use of heterogeneous computing platforms, such as FPGAs, to implement optimized neural network accelerators. Techniques like loop unrolling and pipelining significantly improve throughput and reduce power consumption compared to traditional CPU and GPU processing. For instance, optimized accelerators have been shown to reduce power usage by up to 93% while delivering over 70 times the processing speed compared to conventional CPUs.
Additionally, models optimized for edge computing often employ quantization methods to minimize memory footprint without compromising accuracy. These methods ensure the efficient utilization of hardware resources, critical for scenarios like autonomous navigation, healthcare diagnostics, and industrial automation.
The performance improvements highlight the shift toward localized AI processing, offering high-speed, low-latency computation that supports seamless real-time applications even in devices with constrained resources.
The OmniAudio-2.6B model stands out for its optimization for edge deployment, offering crucial features like a low memory footprint and minimal computational requirements, making it ideal for devices with constrained resources. A key factor in this optimization is the use of quantization, a process that reduces the precision of the model's weights and activations, making it more memory-efficient while preserving its overall performance.
In edge deployment, where computing power is limited, techniques like activation-aware quantization (AWQ) and post-training quantization (PTQ) help minimize the memory usage without compromising the model’s response quality. These approaches allow OmniAudio-2.6B to operate efficiently on devices that typically struggle with large models. For example, AWQ dynamically adjusts the quantization process to retain the most important weights for accuracy while reducing memory requirements.
Another feature enhancing OmniAudio-2.6B's suitability for edge deployment is floating-point (FP) quantization, such as FP8 postprocessing, which further reduces the precision of computations, saving both memory and computation costs.
This ensures that the model can run on low-power devices with minimal performance degradation. Additionally, using techniques like key-value (KV) cache optimization can improve efficiency by reducing the memory needed for longer inputs, a crucial feature for real-time applications like audio processing.
With these advanced techniques, OmniAudio-2.6B is well-suited for deployment in scenarios where high-speed processing is required but computational resources are limited, such as in mobile devices, IoT devices, and other edge-based systems.
Multilingual support is an essential feature for OmniAudio, ensuring that it can serve a global audience and provide seamless interaction in various languages. In today's interconnected world, businesses that are able to effectively communicate with customers in their native language not only foster trust and loyalty but also enhance customer satisfaction.
OmniAudio’s multilingual capabilities allow users to engage with the model in multiple languages, ensuring a broad accessibility range. This support can be vital in enhancing user experience, as it enables global users to receive assistance in the language they are most comfortable with. In fact, studies show that customers are more likely to remain loyal to companies that offer support in their native tongue. By catering to diverse language needs, OmniAudio effectively eliminates barriers, promoting inclusivity and fostering long-term customer relationships.
Furthermore, OmniAudio’s multilingual support helps businesses extend their reach to new markets, allowing them to tap into a broader customer base and expand their global footprint. Multilingual support can increase conversion rates by ensuring that potential customers can engage with the service in their own language.
To implement this successfully, businesses must ensure that the quality of support matches the linguistic needs of their customers. Offering customer service in multiple languages via different channels—such as email, phone, and live chat—makes it more accessible. Additionally, leveraging AI-powered chatbots and machine translation can help scale multilingual support while maintaining accuracy and timely responses.
In short, OmniAudio's multilingual support is not just a feature but a critical asset for global success. It breaks down language barriers, promotes deeper customer engagement, and allows for an effective, inclusive user experience on a global scale.
OmniAudio's real-world applications extend across various industries, enhancing productivity and accessibility with cutting-edge audio processing capabilities. Here are some key use cases:
1. Transcription
OmniAudio excels in speech-to-text conversion, offering a valuable tool for transcribing interviews, meetings, lectures, or podcasts. Its accuracy and speed make it ideal for professionals needing to quickly convert audio into editable text for documentation or analysis. With robust integration options for platforms like Word and Google Docs, users can easily store and manipulate transcribed text. Furthermore, OmniAudio’s ability to recognize various accents and dialects makes it suitable for international use.
2. Audio Analysis
OmniAudio's advanced audio analysis features enable industries like media, entertainment, and healthcare to process and extract useful information from audio files. For example, it can detect key phrases, keywords, and even sentiment from audio content. This capability is vital for content creators, market researchers, or healthcare professionals who need to quickly sift through vast amounts of spoken data. In healthcare, it can assist with processing and analyzing patient recordings, providing quicker insights into patient interactions.
3. Text-to-Speech (TTS)
Beyond transcription, OmniAudio's Text-to-Speech (TTS) feature is transforming accessibility. It’s a valuable tool for users with visual impairments, enabling them to access written content by converting it into natural-sounding speech. This application extends to reading documents, articles, and emails aloud. In the context of education, TTS aids in creating learning materials that are both auditory and visual, supporting various learning styles.
4. Language and Accent Detection
With its robust language processing models, OmniAudio excels in detecting multiple languages and regional accents. This feature is particularly useful for global enterprises that need to support multilingual environments or for applications where understanding regional accents is critical for customer interactions, such as in call centers or international business settings.
5. Real-Time Communication Assistance
For real-time conversations, OmniAudio offers tools for live transcription and translation. This has transformative potential in live events, such as conferences or webinars, where real-time communication is essential. By instantly translating speech into different languages, OmniAudio can foster more inclusive global communication.
6. Customizable Speech Models
OmniAudio allows for customization, offering developers the option to train models tailored to specific industries or terminologies. Whether it’s medical jargon, legal terms, or technical language, this adaptability ensures high accuracy even in niche fields.
In conclusion, OmniAudio’s diverse applications, from transcription to language detection and real-time communication assistance, make it a versatile tool for numerous industries, revolutionizing how organizations interact with and analyze audio content.
Technical Details
The OmniAudio-2.6B model, developed by Nexa AI, is a significant breakthrough in AI-driven audio processing, designed specifically for edge deployment. It has 2.6 billion parameters, making it highly capable for various audio-related tasks, such as speech recognition, audio generation, and environmental sound classification, while still being efficient enough to run on resource-constrained devices.
A key highlight of OmniAudio-2.6B is its use of the GGUF format. This format, developed by the open-source community and detailed in multiple sources, is optimized for low-latency inference and efficient memory usage, enabling better performance on edge devices. GGUF reduces the computational overhead associated with processing large models by employing a more compact representation of the model's weights. This allows for a more efficient deployment, even on hardware with limited memory and processing power.
With the 2.6 billion parameters, the model strikes a balance between performance and resource requirements, offering high throughput for real-time audio tasks without the significant power consumption of larger models like those used for cloud-based services. OmniAudio-2.6B's architecture allows it to process tasks quickly, making it ideal for devices that need to perform real-time audio analysis or synthesis without relying on a connection to a server.
This model's efficiency stems from its integration of advanced quantization techniques, ensuring that despite the model’s relatively large size, it operates with lower power consumption and reduced memory usage, crucial for deployment on edge devices with constrained resources. This allows for high-speed deployment on hardware like GPUs and edge accelerators without sacrificing performance, making it a robust choice for industries that require on-device audio processing.
Overall, OmniAudio-2.6B stands out due to its efficient deployment capability on edge devices, where traditional models might struggle due to hardware limitations. With its advanced architecture and use of GGUF, this model could set a new standard for audio AI, bringing high-performance capabilities to devices that previously lacked the power to handle such tasks.
The integration of Nexa AI's OmniAudio-2.6B with the Nexa SDK introduces a powerful synergy that enhances deployment flexibility across multiple platforms, including GGML and ONNX. The Nexa SDK, a versatile toolkit designed to support a range of model formats like ONNX and GGML, allows for efficient inference across various environments. This integration brings significant performance improvements, particularly in edge deployment scenarios, where resources are constrained but high-speed processing is required.
One of the key features of the Nexa SDK is its support for both GGML (Generalized Graph Model Language) and ONNX (Open Neural Network Exchange) formats. This dual support enables OmniAudio-2.6B to be deployed in environments that prioritize lightweight and optimized execution, such as edge devices and mobile platforms. GGML, being tailored for faster inference on hardware with limited compute power, ensures that OmniAudio-2.6B operates smoothly on devices with constraints, while ONNX allows seamless integration with a variety of machine learning frameworks, making the model accessible across multiple platforms.
Moreover, the integration with the Nexa SDK facilitates not only audio-language model inference but also features support for a variety of tasks, from text-to-speech and auto-speech recognition (ASR) to vision-language model capabilities. This multi-tasking capability makes the SDK a robust solution for developing intelligent systems that need to process and respond to multimodal input in real-time.
By leveraging Nexa SDK’s unified interface for both GGML and ONNX, developers can easily deploy OmniAudio-2.6B across different hardware configurations, from GPUs (CUDA, Metal) to more efficient edge devices with support for Vulkan or ROCm. The SDK’s flexibility extends to both cloud-based and on-premise deployments, ensuring that organizations can scale their AI solutions efficiently.
Thus, with OmniAudio-2.6B's integration into the Nexa SDK, developers gain access to a powerful toolset that accelerates the deployment of high-performance audio language models, while also providing the flexibility to adapt to various hardware and software environments.
The OmniAudio-2.6B is designed with powerful hardware compatibility to take full advantage of modern compute resources. This includes support for NVIDIA CUDA, AMD ROCm, and Vulkan, enabling the model to be deployed efficiently on a wide range of devices and platforms, especially when optimized for edge deployment.
NVIDIA CUDA Compatibility
CUDA, NVIDIA's parallel computing platform and application programming interface (API), is a cornerstone for deep learning tasks. OmniAudio-2.6B leverages CUDA to harness the computational power of NVIDIA GPUs, enabling faster processing and better efficiency in both training and inference phases. CUDA is widely regarded as the industry standard for machine learning and AI tasks, making it a critical component for models like OmniAudio-2.6B. The use of CUDA enables the model to scale efficiently across various NVIDIA hardware, from consumer GPUs like the RTX series to professional-grade accelerators like the A100.
AMD ROCm Support
AMD's ROCm (Radeon Open Compute) platform is another critical integration, especially for those working with AMD hardware. ROCm enables high-performance computing (HPC) and AI workloads on AMD GPUs, and OmniAudio-2.6B's support for ROCm ensures it can run on a variety of AMD devices. This broadens the hardware support, making it accessible to users who prefer AMD over NVIDIA. However, it's worth noting that while AMD GPUs equipped with ROCm are supported, there may still be some limitations in compatibility with certain chipsets, and software maturity issues with ROCm may affect performance on specific hardware configurations.
Vulkan for Cross-Platform Efficiency
In addition to CUDA and ROCm, Vulkan is integrated to offer cross-platform compatibility, especially in environments that demand high-performance graphics and compute workloads. Vulkan is a low-level API that provides developers with direct control over GPU resources. OmniAudio-2.6B utilizes Vulkan for high-speed processing on supported devices, ensuring that users can deploy the model not only on PCs and servers but also on a variety of mobile and embedded systems. This level of flexibility is essential for edge deployment, where hardware environments vary widely.
These hardware compatibility options make OmniAudio-2.6B a highly versatile model that can be deployed across different infrastructures. Whether on NVIDIA or AMD-based systems, or on a variety of consumer and professional GPUs, the model is poised to offer high performance and low latency for edge applications.
Comparison with Competitors
The OmniAudio-2.6B, a specialized model designed by Nexa AI for edge deployment, stands out for its high-speed audio processing capabilities. Compared to other similar models like Whisper, OmniAudio-2.6B offers significant advancements tailored for on-device performance, making it ideal for low-latency applications in edge environments.
While Whisper, developed by OpenAI, excels in its accuracy for speech-to-text tasks across multiple languages, especially with its large training dataset, OmniAudio-2.6B brings a strong focus on efficiency. Whisper's strengths lie in its zero-shot learning and the ability to adapt to diverse accents and languages. However, it often requires more computational resources, especially when running on devices with limited capacity.
OmniAudio-2.6B addresses this gap with an architecture optimized for edge deployment, reducing the need for significant cloud infrastructure and offering a quicker response time. This allows it to perform well on resource-constrained devices, maintaining high accuracy while delivering real-time results with minimal latency. In contrast, Whisper, despite being robust, can sometimes face challenges in such environments, where processing power and memory are limited.
Both models have been compared in terms of their audio-to-text conversion abilities. Whisper's multi-language support and high-quality transcription across diverse datasets are well-established. However, for real-time applications on edge devices, OmniAudio-2.6B's speed and optimized architecture offer a distinct advantage, making it a superior choice when immediate feedback is crucial. On the other hand, Whisper’s broader focus, including its multi-modal capabilities, can sometimes be less suitable for highly constrained environments.
In conclusion, while Whisper is a powerful model for a wide range of speech recognition tasks, OmniAudio-2.6B’s specialization for edge deployment allows it to excel in real-time, low-latency scenarios, offering a more tailored solution for developers working in constrained environments. This makes it an appealing choice for applications requiring fast audio processing without the reliance on cloud resources.
OmniAudio stands out as a highly versatile, on-device AI tool that leverages cutting-edge multimodal capabilities, a key differentiator in the increasingly competitive AI space. The Nexa AI platform powering OmniAudio is particularly notable for its on-device model hub, which allows users to interact with a diverse range of AI models without needing an internet connection. This includes models tailored to audio processing, such as Whisper for speech-to-text conversion, as well as multimodal models that can handle both text and visual data simultaneously.
One of the OmniAudio's most unique selling points is its seamless integration of various AI functionalities into a single, on-device solution. This enables users to perform tasks like audio transcription, language translation, image processing, and even action-oriented tasks such as making purchases or sending emails, all without relying on cloud-based processing. This is made possible by the advanced multimodal AI models that OmniAudio incorporates. These models can process both audio and visual inputs, bridging the gap between different forms of media and allowing for a highly dynamic user experience.
Moreover, OmniAudio's ability to run complex AI models directly on the device contributes significantly to its performance efficiency and security. By keeping everything local, Nexa AI reduces the latency typically associated with cloud processing, ensuring faster response times. This also enhances user privacy, as sensitive data such as voice recordings or images are processed on the device rather than being uploaded to external servers.
In practical terms, this means that OmniAudio can handle tasks that would typically require larger, cloud-based AI solutions. For instance, the ability to recognize and respond to a range of visual and auditory stimuli, such as identifying objects in images or transcribing spoken language into text, sets it apart from other AI agents that lack this kind of multimodal support. The Nexa AI platform's integration of advanced models like CLIP for image-text alignment and Whisper for audio recognition further exemplifies the platform's strengths, providing users with a robust, responsive experience.
Overall, OmniAudio's multimodal, on-device capabilities offer a unique solution for users looking for an efficient, secure, and highly versatile AI-powered tool.
Use Cases
OmniAudio-2.6B excels in several real-life scenarios, particularly when it comes to low-latency speech-to-text transcription. This makes it ideal for applications where real-time communication and fast processing are crucial. Here are some key examples:
Real-Time Transcription for Accessibility
For users with hearing impairments or those in noisy environments, OmniAudio-2.6B offers instant speech-to-text capabilities, making it easier to engage in conversations or follow discussions during meetings, lectures, or other live events. Such real-time transcription tools also help improve accessibility in customer service interactions and professional settings where quick response times are needed.Voice Commands and Smart Assistants
In the world of voice-controlled technologies, OmniAudio-2.6B can power virtual assistants and voice command systems. Its low-latency capabilities allow devices to process voice inputs almost instantly, enabling seamless control of smart home devices, virtual assistants, and even mobile applications.Voice Search and Customer Support
OmniAudio-2.6B shines in customer support scenarios where voice inputs can be transcribed quickly and used to retrieve information, solve problems, or offer personalized responses. Its efficiency in speech-to-text also enhances systems like voice search, making it possible for users to quickly find the information they need online.Dictation for Productivity
For professionals in fields such as journalism, law, and content creation, OmniAudio-2.6B significantly boosts productivity by transcribing dictation accurately in real time. This is particularly beneficial for situations like interviews or brainstorming sessions, where quickly capturing spoken ideas can save time and reduce manual typing.Language Learning and Pronunciation Feedback
OmniAudio-2.6B also provides valuable feedback for language learners by instantly converting speech into text and offering a way to analyze pronunciation in real time. This feature is particularly helpful for learners who are trying to improve their speaking skills and refine their accent.
These use cases show how OmniAudio-2.6B's real-time speech-to-text transcription can improve efficiency, accessibility, and user interaction across multiple industries and applications.
OmniAudio-2.6B represents a significant advancement in audio language models, offering capabilities ideal for deployment in environments where bandwidth is limited or offline access is essential. This model is engineered to process and analyze audio data with minimal reliance on cloud infrastructure, making it an excellent solution for edge deployments, such as in mobile devices, IoT devices, or remote environments. OmniAudio-2.6B leverages cutting-edge audio processing techniques to deliver high-performance results in real-time, even in areas with weak or no internet connectivity.
What sets OmniAudio apart is its optimization for both offline usage and environments with constrained bandwidth. By performing intensive computations locally on the edge device, OmniAudio can handle complex tasks such as automatic speech recognition (ASR), audio-to-text conversion, and context-based audio interpretation. This model is particularly beneficial for use cases where network latency or data privacy concerns prohibit the use of cloud-based solutions.
Furthermore, OmniAudio excels in real-time audio analysis. It can transcribe audio data, identify specific sounds, and provide context-based understanding of the audio stream. For example, in a military or aviation scenario, it could interpret various acoustic signals, such as engine sounds or communications, and offer actionable insights without requiring an internet connection.
This model also integrates with a broad set of devices and systems, thanks to its flexible API and compatibility with different hardware configurations, making it adaptable to diverse industrial and consumer applications. Whether you're working in a remote area or developing applications for edge computing, OmniAudio-2.6B represents a powerful tool for enhancing audio analysis and interaction, even when bandwidth limitations or offline scenarios are present.
The OmniAudio, as a powerful tool in audio-based solutions, has vast potential across numerous industries. Its ability to efficiently handle audio content through advanced AI-driven systems can streamline processes, enhance communication, and expand accessibility in a variety of sectors.
Healthcare: In this industry, OmniAudio can dramatically improve patient care, particularly in multilingual environments. Healthcare workers can utilize audio translations of medical instructions, consent forms, and patient testimonials, ensuring they can serve diverse populations. Accurate audio translations of medical advisories can help bridge language gaps, improving patient outcomes and compliance with health protocols. Additionally, it can be employed in telemedicine for real-time translations during remote consultations.
Education: Educational institutions can leverage OmniAudio to make learning materials more accessible. Whether in online courses or live classroom environments, its audio translation features can ensure that lessons are comprehensible to students worldwide, particularly in e-learning platforms. It can also assist in translating educational content for students who require specific accommodations, such as those with hearing impairments, further promoting inclusivity in education.
Customer Service: For customer service operations, OmniAudio's audio translation abilities can facilitate seamless interactions with international customers. Businesses can offer multilingual support, where customer inquiries in various languages are translated on the fly. This is particularly beneficial for companies that provide global services, ensuring that no customer feels left out due to language barriers. This can be integrated into call centers, chatbots, and virtual assistants to provide consistent and high-quality service across diverse linguistic regions.
Tourism and Hospitality: The tourism sector can greatly benefit from OmniAudio, as it allows for real-time translations of audio guides, hotel services, or promotional content. For example, an audio guide at a museum or a heritage site can be offered in multiple languages, ensuring tourists from around the world can fully immerse themselves in the experience. In hotels, OmniAudio can be used to communicate with guests in their preferred language, improving satisfaction and accessibility.
Entertainment and Media: The entertainment industry can use OmniAudio to provide localized versions of films, shows, podcasts, and other content. By enabling quick and efficient translation of dialogue, audio captions, and voiceovers, content creators can expand their reach to a global audience, making their material accessible and relatable across cultures.
Business and Corporate: Multinational companies can use OmniAudio to streamline communication between offices in different countries. Whether it's translating conference calls, internal meetings, or external presentations, OmniAudio ensures that every stakeholder can understand and contribute to discussions regardless of their native language. This can boost productivity and foster smoother collaboration among diverse teams.
By utilizing OmniAudio's advanced capabilities, industries can overcome communication barriers, improve accessibility, and create more inclusive environments that cater to a global audience. The OmniAudio can be an invaluable asset, particularly in sectors that require clear, accurate, and efficient communication across language boundaries.
Future of Audio AI with Nexa AI
Nexa AI's vision for the future of edge-based audio language models, like their OmniAudio-2.6B, is centered on transforming how artificial intelligence can operate efficiently and effectively directly on devices. As AI becomes more integrated into daily life, the ability to deploy sophisticated models on local devices, like smartphones and embedded systems, is increasingly valuable. Nexa AI aims to make this a reality by pushing the boundaries of on-device AI applications, particularly in areas like speech processing, multimodal interactions, and real-time translation.
One of the key challenges that Nexa AI seeks to address is ensuring that these models are not only powerful but also highly efficient, allowing them to run on devices with limited resources. OmniAudio-2.6B is optimized for this type of edge deployment, with improvements in latency, power consumption, and computational efficiency. The model is capable of delivering high-quality audio language processing, making it well-suited for a wide range of applications from virtual assistants to real-time audio transcription and beyond.
Looking ahead, Nexa AI is working on expanding the capabilities of their models through their Nexa SDK, which provides developers with a comprehensive toolkit to build and deploy AI applications entirely on-device. This will enable applications to process audio, video, text, and even multimodal inputs with greater speed and fewer server-side dependencies, bringing the power of AI directly into the hands of users.
By focusing on optimization for mobile and edge devices, Nexa AI is positioning themselves at the forefront of the edge AI revolution, where performance and local data processing are crucial. Their future roadmap includes further enhancing model efficiency through techniques like quantization, making these advanced models even more accessible to users on a wider range of devices. As this vision continues to unfold, Nexa AI's contribution will be pivotal in shaping the next generation of edge-based AI systems.
As OmniAudio continues to evolve, several promising features and enhancements are expected to enhance its capabilities. The platform currently excels at transforming a wide range of content—such as web pages, text documents, emails, and even audio and video files—into podcast-friendly formats. These podcasts are delivered seamlessly to popular apps like Apple Podcasts, Overcast, and Pocket Casts.
Looking ahead, OmniAudio plans to further expand its content support, introducing additional file formats and refining the AI's ability to process and adapt diverse types of media into high-quality audio podcasts. This will likely include more advanced transcriptions and optimizations, ensuring that content not only sounds natural but is also engaging and suited for passive listening.
Furthermore, while the platform currently lacks a dedicated mobile app for content uploading, this is a high-priority feature in development. This move will significantly enhance user experience, particularly for those who want to manage and create content on the go. OmniAudio is also exploring new integrations, likely increasing its reach and enhancing its presence across different media ecosystems.
Additionally, OmniAudio's expansion into various language markets (e.g., English, French, Chinese, Hindi, and more) promises to make its podcast generation tools more accessible and relevant to a global audience. This multilingual support will be key for the platform's growth, making it an appealing option for users around the world.
With such ambitious updates on the horizon, OmniAudio is poised to redefine how we consume content, making it more accessible, customizable, and adaptable to different listening preferences. As AI and audio integration continue to improve, OmniAudio's future is looking increasingly bright, promising a highly personalized podcast experience that goes beyond traditional content.
Getting Started
To install and deploy OmniAudio-2.6B using the Nexa SDK, you'll need to follow a few straightforward steps. The Nexa SDK provides a comprehensive set of tools to integrate and manage AI models locally, including OmniAudio-2.6B. Here’s a general overview of the installation and deployment process:
Prerequisites
System Requirements:
You need macOS 12 or later to run the Nexa SDK.
Ensure your development environment is set up with Xcode and that you have CocoaPods or Swift Package Manager for dependency management.
SDK Installation:
Download the latest version of the Nexa SDK. As of now, version 0.0.9.7 is the latest stable version available.
You can find it on the Nexa website and follow the instructions for installation. Depending on the system you're using, you may need to use the terminal to extract and install the SDK.
Code Setup for Deployment
Once the SDK is installed, you can start by integrating OmniAudio-2.6B into your app. Below is a basic guide to load and deploy the model:
1. Import the Nexa SDK
In your Swift code, start by importing the necessary modules from Nexa:
2. Configure the Model:
Once you've imported the SDK, the next step is to configure the OmniAudio-2.6B model using the Nexa API. For example, you can set up the model like this:
This snippet initializes the model and attempts to load it. Ensure that the path you provide points to the correct location of the model file on your system.
3. Model Deployment and Inference:
To use OmniAudio-2.6B for inference, you’ll need to pass the required input and handle the output. Here's a basic example of performing inference using the model:
This example passes a string to the model and retrieves the output. The result could vary depending on the specific capabilities of OmniAudio-2.6B, which may include text generation, speech synthesis, or other AI-driven tasks.
Additional Notes:
API Documentation: Refer to the Nexa SDK's API documentation for more advanced configurations and deployment options, such as model fine-tuning or optimizations for different environments.
Error Handling: Always ensure to implement error handling to manage issues like model loading failures, incorrect input, or inference errors.
With these steps, you should be able to successfully integrate and deploy OmniAudio-2.6B in your application using the Nexa SDK.
For more details and updates on the SDK, you can visit the Nexa AI SDK page.
To help you easily access the Nexa AI resources, you can explore the following links:
Nexa SDK GitHub Repository: The Nexa AI SDK GitHub repository provides a comprehensive toolkit that supports various models, including text, image, audio, and multimodal models. The repository contains code for integration with models in formats like GGML and ONNX. You can clone the repository, check the setup instructions, and explore more about how to use and contribute to the Nexa SDK.
Nexa AI Model Hub: For exploring and accessing models, you can visit the Nexa AI Model Hub. This hub offers a user-friendly interface to browse and filter models based on RAM requirements, task types, and file sizes. It includes models for tasks like speech recognition, multimodal processing, and more.
These resources will give you all the tools you need to start working with Nexa AI’s offerings and integrate them into your own applications.
Press contact
Timon Harz
oneboardhq@outlook.com
Other posts





Company
About
Blog
Careers
Press
Legal
Privacy
Terms
Security