Timon Harz
December 16, 2024
Microsoft AI Research Unveils OLA-VLM: Enhancing Multimodal Large Language Models with a Vision-Centric Approach
Microsoft's OLA-VLM combines the power of vision and language for enhanced AI interactions. Discover how this multimodal model is setting new standards in AI development and practical applications.

Multimodal large language models (MLLMs) are advancing quickly, allowing machines to interpret both textual and visual data simultaneously. These models have significant applications in areas like image analysis, visual question answering, and multimodal reasoning. By combining vision and language, MLLMs are enhancing artificial intelligence's ability to understand and interact with the world in a more holistic way.
However, these models still face considerable challenges. A key limitation is their dependence on natural language supervision for training, which often leads to subpar visual representations. Although increasing the size of datasets and computational resources has led to some improvements, more focused optimization is needed for better visual understanding. Balancing computational efficiency with improved performance remains a challenge.
To train MLLMs, current methods typically use visual encoders to extract features from images, combining them with natural language data. Some strategies involve multiple encoders or cross-attention mechanisms to refine understanding. However, these techniques require substantial data and computational power, making them less scalable and practical. This inefficiency highlights the need for more effective optimization strategies for visual comprehension in MLLMs
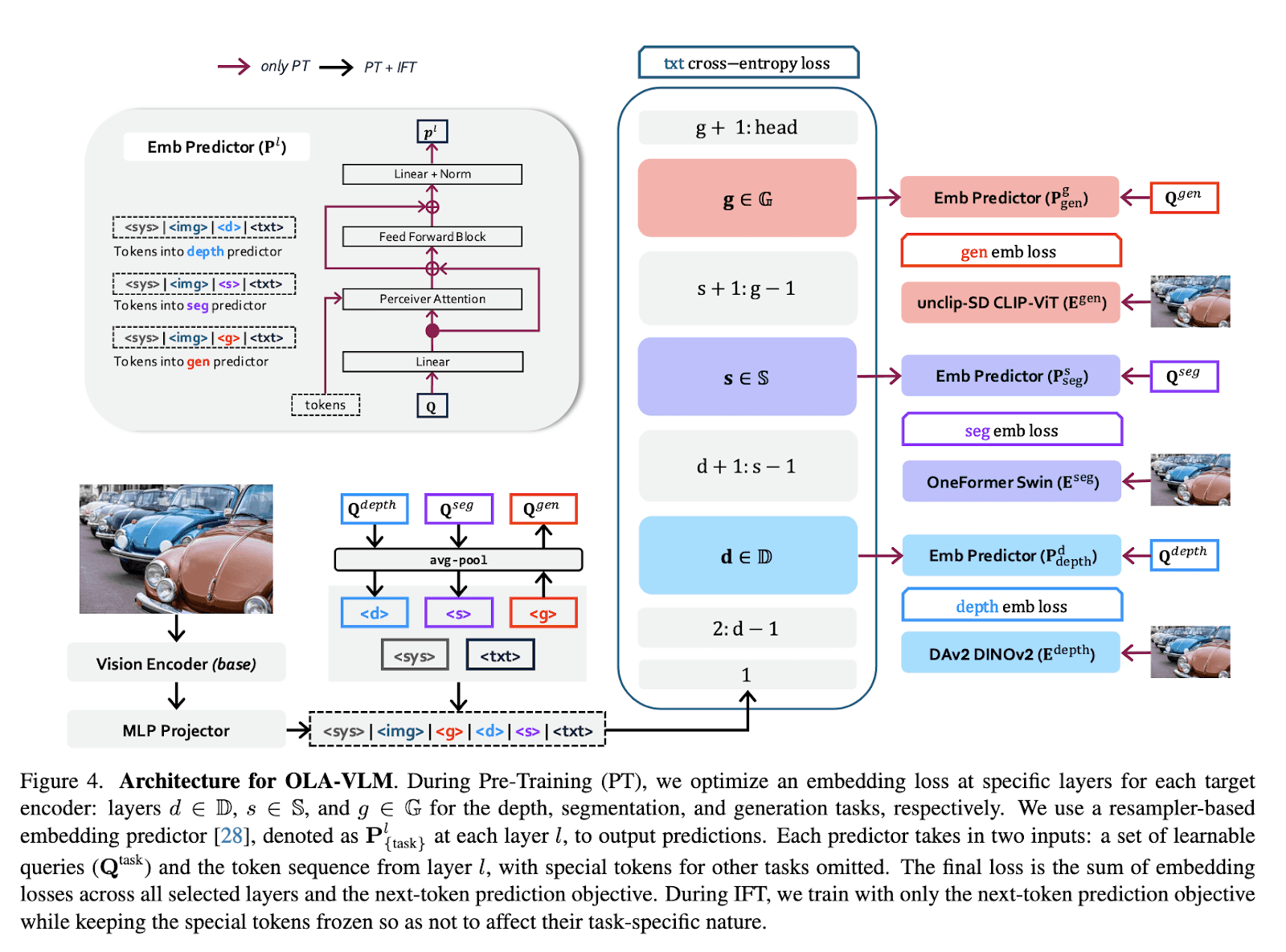
Researchers at SHI Labs at Georgia Tech and Microsoft Research have introduced a groundbreaking method known as OLA-VLM to address key challenges in multimodal large language models (MLLMs). This innovative approach enhances MLLMs by distilling auxiliary visual data into the hidden layers of the model during pretraining. Rather than adding complexity to visual encoders, OLA-VLM optimizes embeddings to better align visual and textual information. By embedding this optimization into intermediate layers of the language model, the approach improves visual reasoning without increasing the computational load during inference.
The OLA-VLM method incorporates embedding loss functions to refine representations derived from specialized visual encoders trained in tasks like image segmentation, depth estimation, and image generation. These distilled features are integrated into the language model via predictive embedding optimization techniques. Additionally, task-specific tokens are added to the input sequence, allowing the model to seamlessly incorporate visual information. This design ensures that visual features enrich the MLLM’s internal representations while preserving the primary objective of next-token prediction, ultimately creating a model with stronger, vision-centric capabilities.
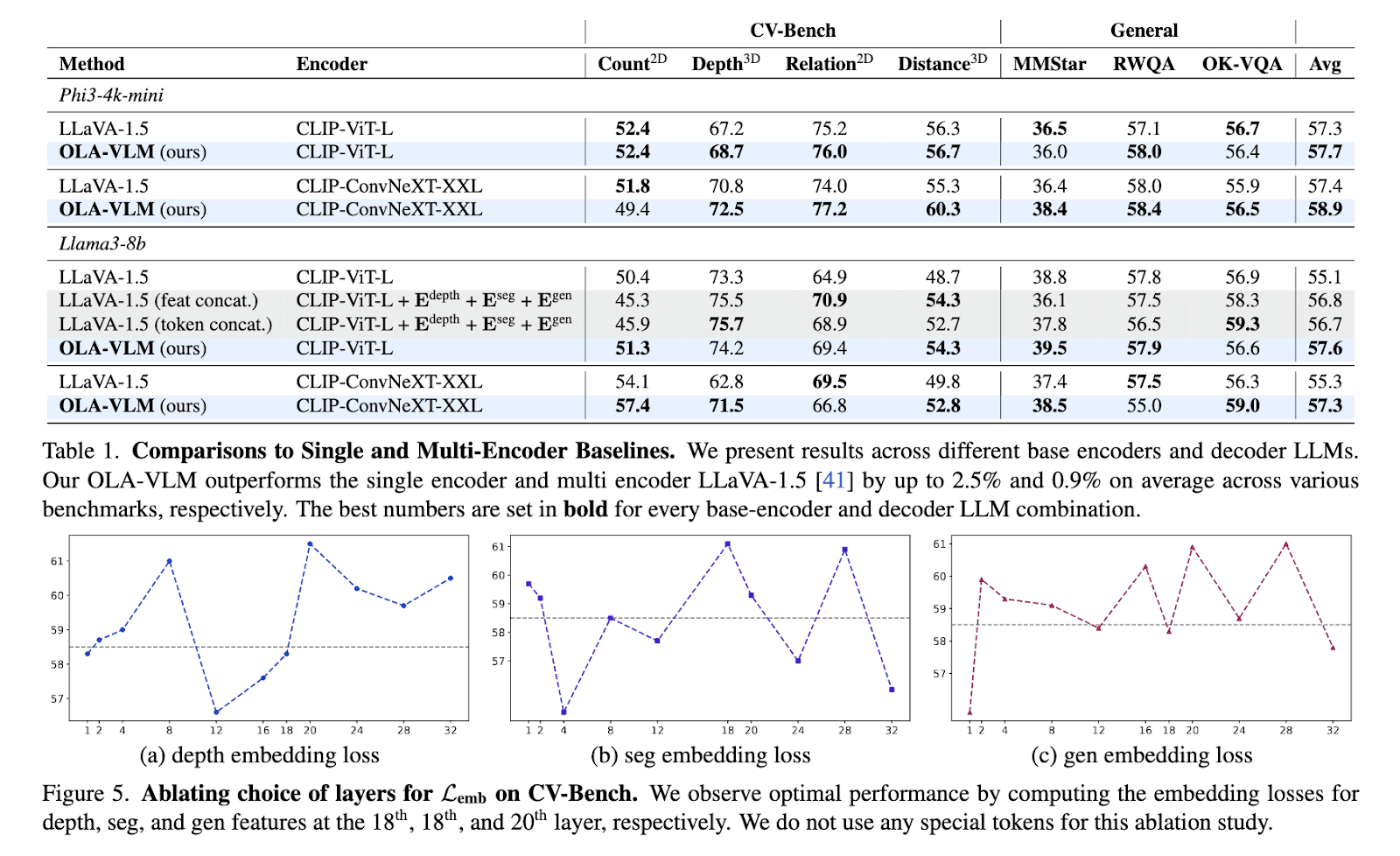
The OLA-VLM model was rigorously evaluated across various benchmarks, demonstrating significant improvements compared to existing single- and multi-encoder models. On CV-Bench, a vision-centric benchmark suite, OLA-VLM outperformed the LLaVA-1.5 baseline, showing an impressive 8.7% improvement in depth estimation tasks, achieving an accuracy of 77.8%. In segmentation tasks, it achieved a mean Intersection over Union (mIoU) score of 45.4%, surpassing the baseline’s score of 39.3%. The model consistently excelled in 2D and 3D vision tasks, with an average improvement of up to 2.5% on benchmarks like distance and relation reasoning. Notably, OLA-VLM achieved these gains using only a single visual encoder during inference, making it far more efficient than systems that rely on multiple encoders.
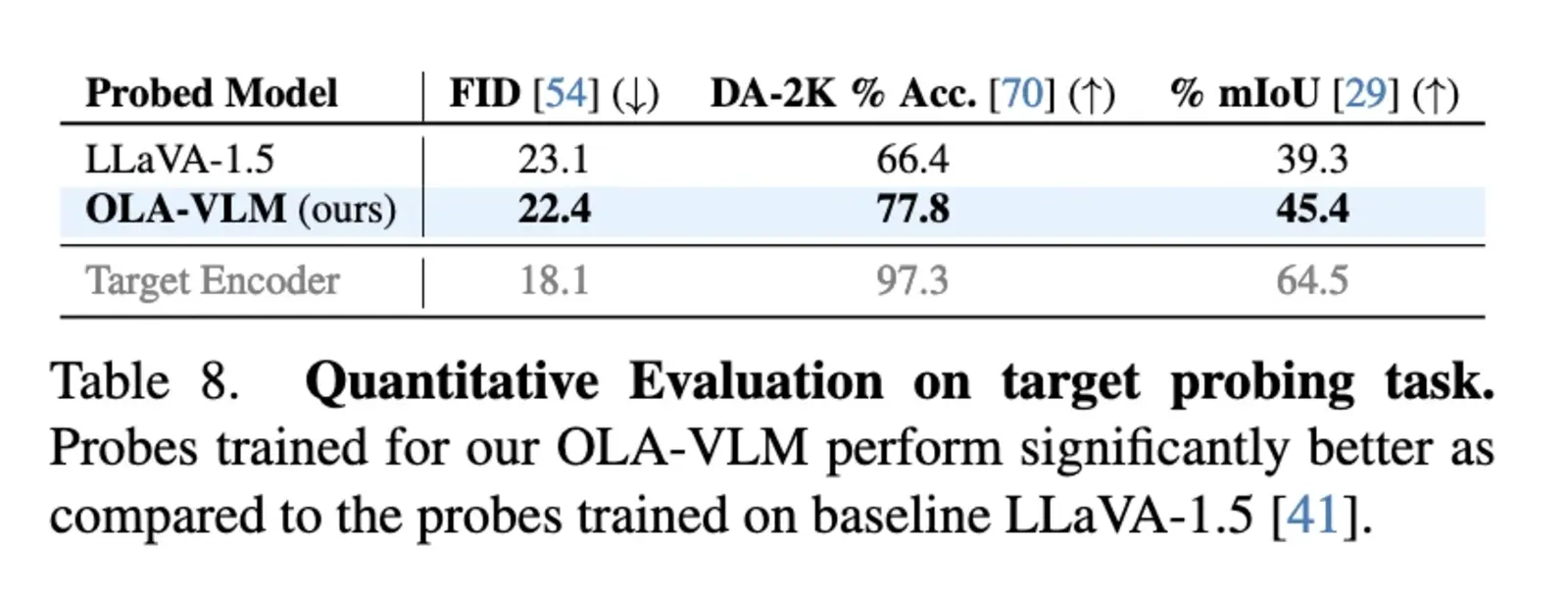
Further validation came from probing experiments that analyzed the representations learned by OLA-VLM. These experiments revealed superior visual feature alignment within the intermediate layers of the model. This alignment significantly boosted the model’s downstream performance in various tasks. Researchers found that incorporating task-specific tokens during training helped optimize features for depth estimation, segmentation, and image generation tasks. The results emphasized the effectiveness of predictive embedding optimization, showcasing how it can balance high-quality visual understanding with computational efficiency, making OLA-VLM a highly efficient and capable model.
OLA-VLM sets a new benchmark for integrating visual information into multimodal large language models (MLLMs) by focusing on embedding optimization during pretraining. This innovative approach addresses gaps in current training methods by introducing a vision-centric strategy that significantly enhances the quality of visual representations. By refining performance on vision-language tasks, OLA-VLM achieves these advancements with fewer computational resources compared to traditional methods. The research demonstrates how targeted optimization during pretraining can lead to substantial improvements in multimodal model performance, offering a more efficient and scalable solution for AI systems.
In conclusion, the work by SHI Labs and Microsoft Research marks a major milestone in multimodal AI development. By optimizing visual representations within MLLMs, OLA-VLM bridges critical gaps in both performance and efficiency. This approach highlights the effectiveness of embedding optimization in addressing vision-language alignment challenges, paving the way for future multimodal systems that are more robust and scalable
Multimodal large language models (MLLMs) represent a leap forward in artificial intelligence by integrating multiple types of data—such as text, images, and even video—into a unified framework. These models are designed to understand and generate content that spans different modalities, making them a significant advancement over traditional, unimodal models that operate on a single data type. The power of MLLMs lies in their ability to perform tasks that require a cross-modal understanding, such as generating images from text, answering questions based on visual content, and even providing insights from mixed media sources.
Microsoft has been at the forefront of developing these models, continually refining them to better interpret and reason with data from a variety of sensory inputs. Their efforts have culminated in advancements like the VCoder, a vision-centric approach aimed at enhancing the object perception abilities of MLLMs. This vision-centric enhancement allows models to not only recognize visual data but to understand complex aspects such as depth and segmentation in images. Microsoft's ongoing work focuses on integrating these capabilities into their multimodal systems to enhance tasks like visual question answering, image captioning, and even more sophisticated visual reasoning.
One notable area of research for Microsoft is the use of the COCO Segmentation Text (COST) dataset, which combines segmentation data with textual information to train MLLMs to better perceive and understand objects within images. This enhances their ability to respond to detailed prompts like "How many cars are in this image?" or "Describe the scene in this photo" with greater accuracy. By developing models that can handle both the perception and reasoning aspects of visual content, Microsoft aims to push the boundaries of what AI can achieve in multimodal understanding.
In this exciting field, the integration of vision and language opens up a host of possibilities, from improving accessibility through better image captions to revolutionizing creative industries by enabling AI to generate complex multimedia content. As Microsoft continues to enhance its multimodal models with a vision-centric approach, the future of AI is becoming increasingly capable of more human-like understanding and interaction across diverse types of media.
What is OLA-VLM?
OLA-VLM (Optimized Large-scale Vision and Language Model) is a cutting-edge advancement in the integration of vision and language models, leveraging an optimized approach to enhance how multimodal models handle both visual and textual data. At its core, OLA-VLM focuses on improving how models process and understand the relationship between images and language by leveraging vast amounts of image-text data for training. This allows it to perform tasks that require a deep understanding of both modalities simultaneously, such as image captioning, visual question answering, and even visual reasoning.
What sets OLA-VLM apart from other multimodal models is its unique emphasis on vision-centric learning, where the model's vision component is deeply integrated with the linguistic capabilities. Rather than treating images and text as separate entities to be merged later, OLA-VLM processes the two in a deeply fused way that allows for richer contextual understanding. This includes not only interpreting objects and scenes in images but also linking these visual elements to corresponding semantic understanding in language, enabling it to perform complex tasks like zero-shot semantic segmentation and image generation from textual prompts.
A key feature of OLA-VLM is its ability to scale and adapt to various applications. It achieves this by utilizing pre-trained models, such as CLIP, that can perform tasks like open-vocabulary object detection and semantic segmentation with minimal additional training. The model’s capability to work with diverse data, ranging from simple object recognition to complex scene understanding, makes it particularly powerful in a wide range of practical scenarios.
Moreover, OLA-VLM takes advantage of cutting-edge advances in spatial reasoning, allowing it to better understand not just the visual content but the spatial relationships within it. This is essential for tasks that require the model to infer details about the layout or positioning of objects in an image, such as determining the relative positions of objects based on a given question.
In summary, OLA-VLM represents a major leap forward in the field of multimodal AI, with its ability to seamlessly merge vision and language capabilities in a way that enhances both fields' performance. Through its advanced training techniques and innovative architecture, OLA-VLM opens up new possibilities for applications that require deep understanding of both the visual and linguistic worlds.
The OLA-VLM (Omni-Lingual and Vision-Language Model), recently unveiled by Microsoft AI Research, introduces a vision-centric approach that enhances the capabilities of multimodal large language models (LLMs). At the core of this model is its ability to simultaneously process both text and visual inputs, allowing for richer, more integrated understanding of content. This dual-input framework allows OLA-VLM to effectively align visual and linguistic information, providing a more nuanced interpretation of multimodal data.
A major innovation in the OLA-VLM model is its advanced vision encoder, which is designed to capture a wider array of visual concepts. This vision-centric feature surpasses traditional models by offering a deeper integration of visual and textual cues. For instance, it can interpret not just the objects present in an image, but also their relationships, attributes, and the broader context in which they appear. This capability is powered by improvements in visual representation learning, as seen in recent vision-language models like VinVL, which has demonstrated significant advances in encoding both objects and their attributes more comprehensively.
Moreover, OLA-VLM leverages a sophisticated fusion mechanism between the vision encoder and the language model, enabling it to process and integrate complex multimodal inputs with greater efficiency. This fusion ensures that visual features are not only detected but are also effectively utilized alongside textual data, opening the door to more accurate and context-aware language generation. Such a vision-centric approach is particularly beneficial in scenarios that require deep understanding of both visual and textual data, such as image captioning, video description, and even interactive multimodal dialogues.
In practice, this enhanced integration translates to better performance across a variety of tasks. For example, the model excels in tasks like image captioning and visual question answering by interpreting complex visual scenarios with a more intuitive, text-aware lens. This integration allows for a fluid, more human-like interaction with multimodal data, elevating the utility of vision-language models for practical applications, ranging from accessibility tools to content creation and search.
As we continue to see advancements in multimodal AI, the vision-centric approach of OLA-VLM sets a promising precedent for future models that aim to break the barriers between visual and textual comprehension, paving the way for more intuitive, cross-modal interactions.
The Role of Vision in Multimodal Models
A vision-centric approach in multimodal large language models (LLMs), such as those in Microsoft's OLA-VLM, is a game-changer for tasks that require both language and visual understanding. This strategy is particularly impactful in areas like image captioning, visual question answering (VQA), and video analysis, where models need to bridge the gap between textual and visual data. By integrating visual comprehension into these LLMs, the models can analyze and generate text that reflects visual scenes more effectively.
In tasks like image captioning, vision-language models can provide detailed, context-aware descriptions of visual content. These models process the image and automatically generate captions that not only describe the objects but also interpret their relationships, actions, and contexts. For instance, in remote sensing (RS) imagery, models can generate captions that explain not just the visible objects but also interpret their significance in terms of geographical features or environmental factors.
Video analysis benefits from this vision-centric approach by enabling models to understand both the static images and the dynamic elements within videos. This means the model can analyze actions, recognize objects over time, and even predict outcomes based on visual cues. For example, OLA-VLM’s ability to analyze and generate captions for video content would allow for more precise tracking of objects and actions throughout the video timeline, offering deeper insights into the scenes it processes.
The integration of vision-centric capabilities also enhances the model's ability to answer complex visual questions. In VQA, the model can analyze an image and then provide accurate, context-driven answers to natural language queries. This capability is powered by deep learning techniques that align the visual data with textual representations, allowing for more accurate responses compared to traditional models that only process text.
Moreover, the advancement of these models has implications for various domains, from healthcare and autonomous driving to entertainment and social media. By incorporating multimodal information processing, OLA-VLM and similar models can create more comprehensive systems that understand and interpret the world in a way closer to human cognition, where language and vision are intricately linked. As these models evolve, the potential to revolutionize how machines assist with tasks like content creation, customer service, and educational tools becomes increasingly tangible.
In conclusion, a vision-centric approach enhances the performance of multimodal models by enabling them to better understand, process, and generate responses based on both visual and textual inputs. This dual capacity is particularly useful in applications that require a comprehensive understanding of the environment, making models like OLA-VLM increasingly essential for complex, real-world tasks.
The OLA-VLM's vision-centric approach holds significant potential in reshaping various industries, especially healthcare, entertainment, and education. By integrating multimodal AI capabilities, this model could vastly improve the efficiency and accuracy of diagnostics and personalized treatments in healthcare.
In healthcare, for example, OLA-VLM's ability to combine visual data with language models could transform medical imaging processes, such as radiology. Models that understand both the image content and the clinical context could assist in generating reports from X-rays, MRIs, and other diagnostic images. This technology could also support the development of advanced tools for detecting conditions like cancer or Alzheimer’s disease by recognizing subtle visual patterns that might go unnoticed by human doctors. Additionally, its integration into patient care systems could provide real-time feedback, improving decision-making for healthcare professionals.
In the entertainment industry, OLA-VLM's capabilities could revolutionize content creation and consumer interaction. By understanding both text and visual content, AI can assist in generating more immersive and personalized experiences. For example, in gaming, AI could help create more dynamic, story-driven experiences, where the AI understands both the visual world and the narrative to adjust the storyline in real-time based on the player’s actions. In film and media production, AI could automate certain tasks, like video editing or scene generation, by comprehending both the script and raw visual content, potentially reducing production time.
For education, OLA-VLM could redefine personalized learning. By understanding both textual and visual learning materials, it could provide tailored educational experiences that adapt to individual students' needs. Imagine a system that can interpret complex scientific diagrams and explain them in simpler terms, or an AI tutor that adjusts its teaching approach based on how well a student grasps certain concepts. This type of technology could make learning more engaging and accessible, particularly for students who struggle with traditional educational methods.
These advancements also raise crucial ethical and privacy considerations. As AI becomes increasingly capable of analyzing personal health data, visual content, and educational progress, ensuring the security of this information will be paramount. Moreover, as AI takes on more roles in these industries, ensuring that the technology is accessible, transparent, and free from bias will be essential to ensure its fair use.
As OLA-VLM continues to evolve, its impact on these sectors could be transformative, paving the way for more intelligent, efficient, and personalized AI applications. However, its integration into critical fields like healthcare and education will require careful, interdisciplinary efforts to maximize benefits while minimizing potential risks.
Technical Insights and Innovations
The OLA-VLM (Optical Language Assistant Vision-Language Model) introduced by Microsoft Research marks a significant leap in the development of multimodal large language models (LLMs). At its core, OLA-VLM innovatively merges the capabilities of both vision and language processing, creating a model capable of deep understanding across a wide variety of multimodal inputs. Its architecture represents a sophisticated fusion of vision-centric methodologies with language understanding, bringing notable advancements in model efficiency, accuracy, and scalability.
Key Components and Design Philosophy
OLA-VLM is built upon the foundation of traditional multimodal models, but its design brings a fresh vision-centric approach to the table. Unlike its predecessors, which rely heavily on sequential integration of image and text inputs, OLA-VLM leverages a unified architecture where both vision and language are processed in tandem rather than separately. This approach reduces the inefficiencies often observed in older models, which require complex, disjointed steps to combine visual and linguistic inputs for downstream tasks such as image captioning, visual question answering (VQA), and multimodal reasoning.
In practical terms, OLA-VLM utilizes advanced vision encoders alongside robust language backbones, ensuring that the model can both interpret and generate outputs that reflect a seamless integration of visual and textual information. The vision encoder, which has been optimized for greater sensitivity to visual details, works hand-in-hand with the language model to refine the output quality and ensure a holistic understanding of the content.
A defining aspect of OLA-VLM's architecture is its scalability. Microsoft's team has engineered the model to handle large, diverse datasets, integrating multiple forms of data, including images, text, and even video, without compromising the model's performance. This scalability ensures that OLA-VLM can be fine-tuned across various domains, from everyday image captioning to more complex visual reasoning tasks, all while maintaining a high level of accuracy.
Efficiency and Accuracy Breakthroughs
One of the standout features of OLA-VLM is its breakthrough in model efficiency. By introducing novel optimizations in its training and inference pipelines, the model achieves a significantly lower computational cost compared to earlier multimodal models. This optimization has profound implications, particularly for real-time applications, where processing speed and resource consumption are critical.
The efficiency improvements stem from two main strategies: smarter data handling and enhanced modularity. OLA-VLM is designed to be more efficient in how it processes image data, allowing for faster processing of higher-resolution images while maintaining robust performance across a range of tasks. Furthermore, it introduces a modular design that enables more efficient fine-tuning. This modularity allows the model to adapt to specific needs without requiring a complete retraining from scratch.
On the accuracy front, OLA-VLM sets a new benchmark for visual reasoning tasks. Thanks to its integrated approach, which combines the visual and linguistic inputs earlier in the process, the model excels in tasks requiring deep understanding of complex visual scenes. Tasks like object detection, scene interpretation, and even abstract visual reasoning are handled with a level of precision that surpasses older multimodal systems, which often struggled with such nuanced tasks.
In comparison to other state-of-the-art multimodal systems, such as Google's Gemini or OpenAI's GPT-4, OLA-VLM shows competitive advantages in visual reasoning and multimodal coherence, where its ability to synchronize image and language understanding offers more accurate and contextually relevant responses. By focusing on a vision-centric architecture, Microsoft has made strides in improving the interpretability and efficiency of multimodal LLMs without sacrificing the richness of the generated outputs.
Applications and Future Directions
With its groundbreaking architecture, OLA-VLM opens new possibilities for a wide range of applications, from intelligent personal assistants and content generation to more advanced fields like autonomous systems and healthcare. By combining the power of vision and language in a unified model, OLA-VLM has the potential to dramatically enhance systems that rely on deep visual and textual understanding, such as virtual assistants that can seamlessly process and respond to both images and written content in a conversational manner.
Looking to the future, Microsoft aims to refine the model's ability to handle even more complex multimodal tasks, pushing the boundaries of what can be achieved with AI. With ongoing improvements in both training techniques and computational power, the potential for OLA-VLM to power next-generation AI applications seems boundless.
In conclusion, OLA-VLM is not just a technical achievement but a vision for the future of AI, one where language and vision are no longer separate domains but are intricately intertwined to create smarter, more intuitive models. This vision-centric approach promises to usher in a new era of multimodal AI, where efficiency, accuracy, and scalability are at the forefront of innovation.
The development of OLA-VLM, Microsoft's innovative multimodal language model, faced several unique challenges in its quest to integrate visual and linguistic processing into a single unified system. Below are some of the key hurdles and how Microsoft addressed them in the creation of this advanced AI model.
1. Combining Vision and Language:
The most significant challenge in developing OLA-VLM was ensuring that both vision and language components were effectively integrated. This required the model to not only understand images and texts but also learn how to correlate the two in a meaningful way. Traditional models often struggled with handling these modalities separately, but the OLA-VLM aimed to bridge this gap by incorporating sophisticated techniques like contrastive learning and multi-modal fusion. These approaches helped the model refine its ability to match visual cues with language-based descriptions, enabling it to generate more coherent and contextually appropriate outputs.
2. Dataset Bias and Generalization:
One of the ongoing issues with multimodal models is the presence of dataset bias. Given that OLA-VLM was trained on large-scale image-text datasets, the model could potentially inherit biases from these sources, leading to skewed or inaccurate interpretations of visual information. To combat this, Microsoft focused on creating more diverse and representative training datasets. Moreover, by incorporating techniques like knowledge distillation, the model was able to learn from broader data sources, reducing the likelihood of memorizing specific patterns and improving its ability to generalize across various inputs.
3. Evaluation and Interpretability:
Evaluating multimodal models like OLA-VLM presents unique challenges. The traditional evaluation metrics often fall short when applied to visual language models, as they fail to account for the nuanced interpretations of images or the varying linguistic responses that could apply to the same visual input. In response, Microsoft explored new evaluation strategies that focused on multimodal understanding, looking at both the visual context and the linguistic output simultaneously. Additionally, improving the interpretability of the model was a critical concern, as the "black-box" nature of deep learning models can undermine trust. By focusing on making the inner workings of OLA-VLM more transparent, Microsoft aimed to make the model more understandable and reliable for real-world applications.
4. Compositional Generalization:
A significant hurdle in the development of OLA-VLM was ensuring that the model could handle compositional generalization—an area where many earlier models struggled. This refers to the model’s ability to understand and generate responses for novel combinations of known concepts, such as recognizing unusual objects or new scenarios. Microsoft addressed this challenge by integrating more complex architectures and training methodologies that allowed OLA-VLM to better adapt to unexpected combinations and rare configurations, improving its versatility and robustness.
5. Scalability and Efficiency:
Given the complexity of training multimodal models, another obstacle was ensuring scalability without sacrificing performance. OLA-VLM required vast computational resources, and Microsoft had to innovate in terms of model optimization. Techniques like parameter-efficient fine-tuning (PEFT) were employed to ensure that the model could be fine-tuned for specific tasks without overloading the system’s memory or computational capacity. This made OLA-VLM more efficient, allowing it to handle larger datasets and more complex tasks with a smaller footprint.
In summary, while the development of OLA-VLM was fraught with challenges—ranging from data bias to compositional generalization—Microsoft's innovative approaches have resulted in a powerful multimodal model. By improving both the model’s internal mechanisms and the methods used to evaluate and fine-tune it, Microsoft has created a tool that can better understand and interact with the world through both images and language.
Practical Applications of OLA-VLM
The OLA-VLM model, developed by Microsoft, presents a significant advancement in multimodal AI by focusing on integrating vision with language processing. This opens up various exciting real-world applications across industries, harnessing the power of visual and textual data to enhance existing systems and create new capabilities. Here are a few examples of how OLA-VLM could revolutionize different sectors:
Improved Content Recommendation Systems: By understanding both images and text, OLA-VLM can enhance recommendation algorithms. For instance, e-commerce platforms could offer highly personalized shopping experiences, suggesting products based on visual cues (such as a user’s preference for a specific style or color) combined with textual data (like past reviews or purchase history). This fusion of data leads to more accurate and effective suggestions, enhancing user engagement and sales.
Advancement of Virtual Assistants: Multimodal models like OLA-VLM enable virtual assistants to interpret and respond to both visual and spoken cues. For example, a virtual assistant could analyze images sent by a user to provide context-aware assistance. This could include identifying objects in a photo, interpreting a scene, or even performing actions based on visual inputs. By understanding the combination of voice commands and visual data, assistants become much more intuitive and capable, improving user experience across home automation, customer service, and personal productivity.
Enhancing Automated Video Editing Tools: OLA-VLM’s multimodal capabilities are particularly beneficial in automating tasks such as video editing, where both visual content and accompanying text are critical. For example, the model can automatically generate captions for video content, identify key scenes or objects, and even recommend edits based on the analysis of the video’s visual and textual content. This can significantly speed up video production workflows, especially in industries like marketing, entertainment, and education.
Visual Assistance for the Impaired: One of the most impactful applications of OLA-VLM is its potential to assist those with visual impairments. The model can generate detailed descriptions of images or videos, helping users understand visual content through text. This functionality can be integrated into accessibility tools to help visually impaired individuals navigate digital content more effectively.
Automatic Content Moderation: With its ability to process both visual and textual data, OLA-VLM can be used in content moderation to automatically detect inappropriate or harmful content in images and videos. This is especially useful in social media platforms, online communities, and e-commerce websites, where real-time content filtering is crucial to maintaining a safe environment.
These applications demonstrate the versatility and potential of OLA-VLM to transform industries by leveraging the combined power of vision and language understanding, making systems smarter and more efficient. The ability to process and integrate these different data types could lead to more seamless, intuitive, and automated solutions across various fields.
Future Prospects and Impact
The future of vision-centric multimodal models holds immense potential, transforming industries by creating AI systems that seamlessly integrate text and visual data to enhance understanding and decision-making. As these models advance, we anticipate major shifts across a variety of fields, with AI becoming more versatile and capable of understanding not only language but also images, videos, and other sensory data. The growing sophistication of such models, like Microsoft's OLA-VLM and similar projects, may empower AI to analyze visual contexts, generate text based on image interpretation, and even facilitate cross-modal tasks with minimal input.
In terms of practical applications, industries such as healthcare, retail, education, and entertainment could see major advancements. For instance, in healthcare, vision-centric models could assist with diagnostic imaging, recognizing patterns and anomalies in medical scans and correlating them with patient data to propose treatments. In retail, AI could revolutionize customer service by analyzing images of customer behavior or inventory and responding with personalized recommendations.
However, these advances come with significant ethical challenges. As AI systems become increasingly autonomous in handling and interpreting visual data, questions surrounding data privacy, consent, and transparency will intensify. Models like OLA-VLM may inadvertently reinforce biases present in training data, leading to discriminatory or inaccurate predictions, especially when applied to sensitive sectors. Furthermore, the possibility of deepfakes and misinformation escalates as AI can create hyper-realistic media. Ensuring fairness, transparency, and accountability in such systems will be crucial, particularly as these models gain the ability to influence public opinion or even assist in decision-making processes.
The ethical landscape will require continuous oversight, with AI developers and researchers focusing on building robust models that are interpretable, aligned with ethical guidelines, and designed to minimize harm. Increasing collaboration between AI scientists and policymakers will be essential in managing the complex implications of these technologies, particularly as their applications expand into critical areas like law enforcement or governance.
The future could also see breakthroughs in AI safety and interpretability, ensuring that these systems align with human values while maintaining the capability to perform complex multimodal tasks. Research initiatives are already exploring interpretability methods, allowing humans to trace decisions back through AI systems to ensure compliance with ethical standards. Moreover, ethical frameworks may evolve alongside these technologies, balancing innovation with human-centered design to mitigate risks and maximize the benefits of multimodal AI.
Conclusion
OLA-VLM (OpenAI's Vision Language Model) is a cutting-edge development from Microsoft that merges the capabilities of large language models with vision. This integration is poised to redefine AI’s role in understanding both text and images in a unified system, opening up new possibilities for both industries and everyday users.
At the core of OLA-VLM is the vision-centric architecture, which enhances multimodal reasoning. While traditional AI models primarily excel in either text or vision, OLA-VLM enables seamless cross-communication between these domains, offering improved accuracy in tasks such as image description, visual question answering, and even interpreting complex visual data. For example, OLA-VLM can analyze an image and generate detailed captions that contextualize the image in relation to the surrounding environment, providing a richer understanding of the visual content.
Beyond simple image recognition, OLA-VLM is equipped with advanced capabilities for processing more nuanced visual information. This includes interpreting images to generate actionable insights, such as recognizing safety hazards, understanding intricate diagrams, or even navigating real-world scenarios through visual cues. These features position OLA-VLM as a powerful tool not only for developers but also for real-world applications, from smart cities and robotics to autonomous vehicles and healthcare monitoring systems.
Furthermore, the model’s design allows it to function in various environments, including edge devices, making it more accessible and versatile. This feature ensures that the technology can work in environments with limited connectivity, providing real-time analysis even in remote areas. Such capabilities are especially beneficial for industries like manufacturing, logistics, and agriculture, where real-time, reliable insights are crucial.
The release of OLA-VLM reflects a broader trend in AI development: the push toward more integrated and holistic AI systems that bridge the gap between vision, language, and decision-making. As multimodal AI continues to evolve, it will likely play an essential role in how businesses and individuals interact with and interpret both digital and physical worlds. This could range from enhancing accessibility features for visually impaired users to automating complex workflows across industries.
In summary, OLA-VLM is a groundbreaking model that not only enhances multimodal AI's ability to process and understand both images and text but also sets the stage for future AI innovations. Its potential to change how AI interacts with our world is immense, as it paves the way for smarter, more intuitive systems that can reason over both text and visual data with a high degree of precision and efficiency.
The ongoing advancements in multimodal AI, particularly in models that combine vision and language capabilities, are reshaping how we interact with and use AI across industries. Microsoft's pioneering work in this area, such as their development of LLaVA (Large Language and Vision Assistant), offers a glimpse into the future of AI systems that not only understand but can also engage in dynamic, real-time interactions involving images, text, and other data types.
As these multimodal systems evolve, they bring about new possibilities for applications ranging from general-purpose assistants to highly specialized tools in fields like healthcare and education. However, with such rapid growth comes the need for careful consideration of their broader implications. The integration of vision and language models—especially ones that leverage the power of large language models (LLMs)—opens up exciting potential but also raises important questions regarding ethics, accessibility, and reliability.
Researchers are now focusing on creating unified vision models that move beyond the capabilities of traditional image recognition or text-based analysis. This shift represents a fundamental leap in AI's versatility, aiming to make these systems more adaptable and capable of handling a broader range of tasks with greater efficiency. Open-ended multimodal assistants, like the ones Microsoft is developing, could soon play pivotal roles in sectors such as education, healthcare, and customer service, providing new avenues for innovation and problem-solving.
Yet, while the promise of such systems is immense, it's crucial to stay updated on the latest developments and research in multimodal AI to fully grasp the scope of what these advancements mean for society. From enhancing productivity to transforming industries, the future of multimodal AI is not only about creating smarter systems but also about ensuring these systems are designed ethically and used responsibly. By keeping an eye on projects like LLaVA and similar technologies, we can better prepare for the challenges and opportunities that lie ahead in this exciting field.
Press contact
Timon Harz
oneboardhq@outlook.com
Other posts





Company
About
Blog
Careers
Press
Legal
Privacy
Terms
Security