Timon Harz
December 18, 2024
Microsoft AI Launches SCBench: A Key Benchmark for Evaluating Long-Context Methods in Large Language Models
SCBench offers a detailed evaluation of long-context LLMs, providing valuable metrics for developers and researchers. Discover how this new benchmark advances the capabilities of AI models in processing extended text.

Long-context LLMs (Large Language Models) enable advanced applications like repository-level code analysis, long-document question-answering, and many-shot in-context learning by supporting extended context windows ranging from 128K to 10M tokens. However, these capabilities introduce challenges in computational efficiency and memory usage during inference. Optimizations focusing on Key-Value (KV) caches have emerged to address these issues, aiming to enhance cache reuse for shared contexts in multi-turn interactions. Techniques such as PagedAttention, RadixAttention, and CacheBlend strive to reduce memory costs and improve cache utilization, but are often evaluated only in single-turn scenarios, overlooking multi-turn use cases.
Efforts to improve long-context inference are aimed at alleviating computational and memory bottlenecks during the pre-filling and decoding stages. Pre-filling optimizations, including sparse attention, linear attention, and prompt compression, aim to simplify the handling of large context windows. Decoding techniques, such as static and dynamic KV compression, cache offloading, and speculative decoding, focus on managing memory constraints efficiently. While these methods improve efficiency, many rely on lossy compression, which can reduce performance in multi-turn applications, where prefix caching is essential. Most conversational benchmarks prioritize single-turn evaluations, leaving a gap in assessing solutions for multi-turn shared contexts.
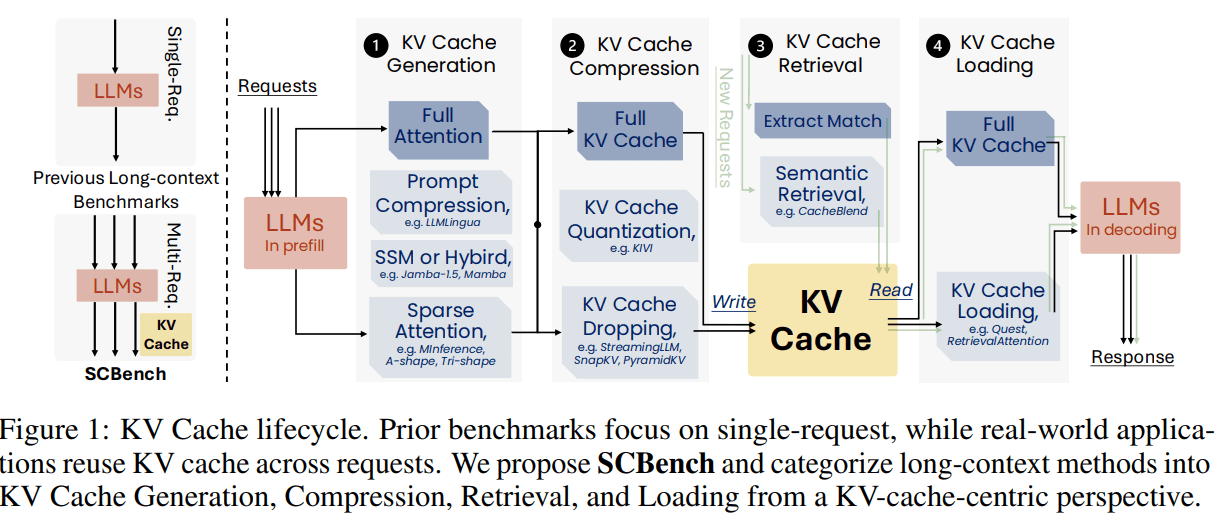
Researchers from Microsoft and the University of Surrey introduced SCBench, a benchmark designed to assess long-context methods in LLMs through a KV cache-centric approach. SCBench evaluates four KV cache stages: generation, compression, retrieval, and loading, across 12 tasks and two shared context modes—multi-turn and multi-request. The benchmark assesses methods like sparse attention, compression, and retrieval on models like Llama-3 and GLM-4. Results show that sub-O(n) memory methods struggle in multi-turn settings, while O(n) memory approaches perform more robustly. SCBench offers insights into sparsity effects, task complexity, and challenges like distribution shifts in long-generation tasks.
The KV-cache-centric framework categorizes long-context methods in LLMs into four stages: generation, compression, retrieval, and loading. Generation includes techniques like sparse attention and prompt compression, while compression involves KV cache dropping and quantization. Retrieval focuses on fetching relevant KV cache blocks to optimize performance, and loading includes dynamically transferring KV data for computation. SCBench evaluates these methods across 12 tasks, such as string and semantic retrieval, multi-tasking, and global processing. The benchmark analyzes performance metrics like accuracy and efficiency, providing insights into algorithm innovations, such as Tri-shape sparse attention, which enhances performance in multi-request tasks.
The researchers evaluated six open-source long-context LLMs, including Llama-3.1, Qwen2.5, GLM-4, Codestal-Mamba, and Jamba, representing a variety of architectures, including Transformer, SSM, and SSM-Attention hybrids. Experiments were conducted using BFloat16 precision on NVIDIA A100 GPUs, leveraging frameworks like HuggingFace, vLLM, and FlashAttention-2. Eight long-context solutions, including sparse attention, KV cache management, and prompt compression, were tested. Results indicated that MInference excelled in retrieval tasks, while A-shape and Tri-shape performed better in multi-turn tasks. KV compression methods and prompt compression produced mixed results, often underperforming in retrieval tasks. SSM-attention hybrids faced difficulties in multi-turn interactions, and gated linear models exhibited poor overall performance.
In conclusion, the study uncovers a significant gap in the evaluation of long-context methods, which have traditionally focused on single-turn interactions while overlooking the multi-turn, shared-context scenarios common in real-world LLM applications. To address this, the SCBench benchmark is introduced, evaluating long-context methods through the lens of the KV cache lifecycle: generation, compression, retrieval, and loading. It spans 12 tasks across two shared-context modes, with a focus on four core capabilities: string retrieval, semantic retrieval, global information processing, and multitasking. By assessing eight long-context methods and six state-of-the-art LLMs, the study shows that sub-O(n) methods struggle in multi-turn contexts, while O(n) approaches perform well, providing critical insights for advancing long-context LLMs and their underlying architectures.
Microsoft AI has introduced SCBench, a comprehensive benchmark designed to evaluate long-context methods in large language models (LLMs). This benchmark focuses on the Key-Value (KV) cache-centric approach, assessing four stages: generation, compression, retrieval, and loading. SCBench evaluates these methods across 12 tasks and two shared context modes—multi-turn and multi-request—using models like Llama-3 and GLM-4. The results indicate that sub-O(n) memory methods face challenges in multi-turn scenarios, while O(n) memory approaches perform robustly. SCBench offers valuable insights into sparsity effects, task complexity, and challenges such as distribution shifts in long-generation scenarios.
Long-context capabilities in large language models (LLMs) are pivotal for advancing artificial intelligence, enabling models to process and comprehend extensive textual information. This proficiency is essential for tasks such as analyzing lengthy documents, engaging in multi-turn conversations, and understanding complex narratives. The significance of these capabilities is underscored by the increasing demand for AI systems that can handle large-scale textual data across various domains.
Traditional LLMs often face limitations due to their fixed context windows, restricting the amount of text they can process at once. This constraint hampers their ability to maintain coherence over long passages and to capture intricate dependencies within the text. To address these challenges, researchers have been developing methods to extend the context length, thereby enhancing the models' performance in tasks that require understanding of extended textual information. For instance, a study titled "Beyond the Limits: A Survey of Techniques to Extend the Context Length in Large Language Models" reviews various approaches, including architectural modifications and training techniques, aimed at improving long-context processing in LLMs.
The ability to process longer contexts is particularly crucial in applications such as legal document analysis, scientific research, and technical support, where understanding the full scope of information is necessary for accurate interpretation and decision-making. Moreover, in conversational AI, maintaining context over multiple interactions is vital for providing coherent and contextually relevant responses. Advancements in long-context processing have led to the development of models like GPT-4, which can handle context windows of up to 32,768 tokens, significantly improving their performance in tasks requiring the understanding of extended textual information.
However, extending context length introduces new challenges, including increased computational demands and the need for more sophisticated training techniques to maintain performance and accuracy. As context length increases, so do the computational resources required for training and inference, necessitating the development of more efficient algorithms and hardware solutions. Additionally, longer contexts can lead to issues such as overfitting and difficulties in generalization, which researchers are actively working to mitigate. For example, the study "Long-Context Language Modeling with Parallel Context Encoding" introduces a framework that extends the context window of LLMs while maintaining efficiency, demonstrating the ongoing efforts to balance performance with computational feasibility.
In summary, the significance of long-context capabilities in LLMs lies in their potential to enhance AI systems' understanding and generation of complex, extended textual information. While challenges remain, ongoing research and development are progressively overcoming these obstacles, paving the way for more advanced and capable AI applications across various fields.
SCBench, short for SharedContextBench, is a comprehensive benchmark developed by researchers at Microsoft and the University of Surrey to evaluate long-context methods in large language models (LLMs). Recognizing the limitations of existing benchmarks that primarily focus on single-turn evaluations, SCBench aims to provide a more realistic assessment by considering the full lifecycle of the key-value (KV) cache in real-world applications. This approach is particularly pertinent as KV cache reuse has become a standard component in LLM inference frameworks, including those developed by OpenAI, Microsoft, Google, and Anthropic.
The benchmark adopts a KV cache-centric framework, categorizing long-context methods into four essential stages: generation, compression, retrieval, and loading. Generation encompasses techniques like sparse attention and prompt compression, which are employed to process input prompts and produce the KV cache used during decoding. Compression involves methods such as KV cache dropping and quantization, aiming to reduce the memory footprint of the KV cache without significantly compromising performance. Retrieval focuses on fetching relevant KV cache blocks from a history pool to optimize performance, thereby eliminating the need to regenerate the KV cache for each new request. Loading pertains to dynamically transferring KV data for computation, ensuring that only the necessary portions of the KV cache are utilized during inference.
SCBench evaluates these methods across 12 tasks, which are organized into four categories of long-context capabilities: string retrieval, semantic retrieval, global information processing, and multi-tasking. Each task is assessed under two shared context modes: multi-turn and multi-request. The multi-turn mode involves caching context within a single session, while the multi-request mode shares context across multiple sessions. This dual-mode evaluation provides a comprehensive analysis of how long-context methods perform in scenarios that closely mimic real-world applications.
The benchmark includes a diverse set of long-context solutions, such as Gated Linear RNNs (Codestal-Mamba), Mamba-Attention hybrids (Jamba-1.5-Mini), and efficient methods like sparse attention, KV cache dropping, quantization, retrieval, loading, and prompt compression. These methods are evaluated on six Transformer-based long-context LLMs: Llama-3.1-8B/70B, Qwen2.5-72B/32B, Llama-3-8B-262K, and GLM-4-9B. The evaluation employs BFloat16 precision on NVIDIA A100 GPUs, utilizing frameworks such as HuggingFace, vLLM, and FlashAttention-2.
The findings from SCBench reveal that methods maintaining O(n) memory with sub-O(n²) pre-filling computation during KV cache generation perform robustly across multiple requests. In contrast, methods with sub-O(n) memory usage exhibit strong performance in single-turn scenarios but experience a decline in accuracy during subsequent requests. Additionally, the benchmark highlights the impact of dynamic sparsity, noting that dynamic sparsity yields more expressive KV caches than static patterns. It also observes that layer-level sparsity in hybrid architectures can reduce memory usage while maintaining strong performance. Furthermore, SCBench identifies attention distribution shift issues in long-generation scenarios, emphasizing the need for methods that can adapt to such challenges.
By providing a detailed and realistic evaluation of long-context methods, SCBench offers valuable insights for researchers and practitioners aiming to develop more efficient and effective LLMs. Its comprehensive approach ensures that the evaluated methods are assessed in conditions that closely resemble their intended real-world applications, thereby facilitating the advancement of AI systems capable of handling complex, extended textual information.
Long-Context Large Language Models
Long-context large language models (LLMs) have emerged as a transformative force in artificial intelligence, significantly enhancing the ability of AI systems to process and comprehend extensive textual information. These models are designed to handle context windows that span thousands to millions of tokens, enabling them to maintain coherence and capture intricate dependencies over long passages of text. This capability is particularly crucial in applications such as repository-level code analysis and long-document question-answering, where understanding the full scope of information is essential for accurate interpretation and decision-making.
In the realm of repository-level code analysis, long-context LLMs have revolutionized the way developers interact with and understand large codebases. Traditional code analysis tools often struggle with the complexity and scale of modern software repositories, leading to challenges in code search, documentation generation, and understanding code functionality. Long-context LLMs address these challenges by processing entire code files or even multiple files simultaneously, allowing for a more holistic understanding of the code's structure and behavior. For instance, the RepoQA benchmark evaluates LLMs on their ability to understand and search through long-context code, demonstrating that these models can effectively handle complex code search tasks across multiple programming languages.
Moreover, these models facilitate the generation of comprehensive documentation and assist in code refactoring by providing insights into code dependencies and potential areas for optimization. By leveraging the extensive context processing capabilities of long-context LLMs, developers can achieve a deeper understanding of codebases, leading to improved software maintenance and development efficiency.
In the domain of long-document question-answering, long-context LLMs have significantly advanced the ability to extract relevant information from extensive documents, such as research papers, legal texts, and technical manuals. Traditional models often face limitations due to their fixed context windows, which restrict the amount of text they can process at once, leading to challenges in maintaining coherence and capturing dependencies over long documents. Long-context LLMs overcome these limitations by processing entire documents, enabling them to understand the context and nuances of the text more effectively.
This capability is particularly valuable in scenarios where users need to extract specific information or summaries from lengthy documents. For example, the LongRAG framework enhances the performance of LLMs in long-context question-answering tasks by integrating retrieval-augmented generation techniques, allowing models to access and process information from large document collections more efficiently.
Furthermore, long-context LLMs are instrumental in tasks such as document classification, sentiment analysis, and information extraction, where understanding the full content of a document is crucial. By processing long documents in their entirety, these models can capture the underlying themes and sentiments, leading to more accurate and contextually relevant outputs.
The advancements in long-context LLMs have also spurred the development of specialized benchmarks and evaluation frameworks to assess their performance in these applications. For instance, the BAMBOO benchmark evaluates the long-context modeling capacities of LLMs across various tasks, including question answering, hallucination detection, text sorting, language modeling, and code completion.
These benchmarks provide valuable insights into the strengths and limitations of long-context LLMs, guiding future research and development efforts.
In summary, long-context LLMs represent a significant advancement in AI, enabling more sophisticated and nuanced understanding of extensive textual information. Their applications in repository-level code analysis and long-document question-answering exemplify their potential to transform various domains by providing deeper insights and enhancing decision-making processes. As research continues to progress, it is anticipated that these models will become increasingly adept at handling complex, long-form content, further expanding their applicability and impact across diverse fields.
Long-context large language models (LLMs) have revolutionized natural language processing by enabling the analysis and generation of extensive textual data. However, their deployment, particularly during inference, presents significant challenges related to computational efficiency and memory usage. These challenges arise from the models' need to process and store large amounts of information, which can lead to increased latency and higher operational costs.
One of the primary issues is the substantial memory consumption associated with storing key-value (KV) pairs during attention mechanisms. As the context length increases, the number of KV pairs grows quadratically, leading to significant memory overhead. This quadratic scaling can make it impractical to deploy such models on hardware with limited memory resources. For instance, caching all KV states across all attention heads consumes substantial memory, posing a significant challenge for efficient deployment.
To address these challenges, researchers have proposed various strategies to optimize memory usage and computational efficiency. One approach involves compressing the context to reduce the amount of information the model needs to process. By identifying and pruning redundancy in the input context, models can operate more efficiently without significantly compromising performance. Experimental results have shown that such methods can lead to a 50% reduction in context cost, resulting in a 36% reduction in inference memory usage and a 32% reduction in inference time, while maintaining comparable performance.
Another strategy focuses on optimizing the attention mechanism itself. Techniques like DuoAttention categorize attention heads into retrieval and streaming types, allowing the model to process long contexts more efficiently. This approach reduces the computational and memory challenges associated with caching all KV states across all attention heads.
Additionally, methods such as Proximal over Distant (POD) aim to improve inference efficiency by optimizing memory and computational complexity. These techniques focus on enhancing the model's ability to handle long contexts without incurring significant computational costs.
Despite these advancements, the deployment of long-context LLMs remains a complex task. The trade-off between maintaining performance and reducing computational demands requires careful consideration. Innovations in hardware, such as specialized accelerators and memory architectures, are also being explored to support the efficient deployment of these models. For example, Nvidia has reported that inferencing generated 40% of its revenues over the past 12 months, highlighting the growing importance of efficient inference capabilities in AI applications.
The Need for Effective Benchmarking
Evaluating large language models (LLMs) has traditionally relied on benchmarks that focus primarily on single-turn interactions. While these benchmarks have been instrumental in assessing certain aspects of LLM performance, they exhibit several limitations that hinder a comprehensive understanding of a model's capabilities.
One significant limitation is the lack of alignment with real-world applications. Single-turn evaluations often fail to capture the complexities inherent in multi-turn interactions, where context and user intent evolve over time. This misalignment can lead to overestimations of a model's effectiveness in practical scenarios. For instance, a model that performs well in single-turn evaluations may struggle in multi-turn dialogues due to its inability to maintain context and adapt to changing user inputs.
Moreover, single-turn benchmarks may not adequately assess a model's reasoning abilities. Tasks that require multi-step reasoning or the integration of information across multiple interactions are often underrepresented. This oversight can result in models that excel in isolated tasks but falter in more complex, real-world applications. Recent studies have highlighted the need for evaluation frameworks that consider the dynamic nature of user interactions and the evolving context within multi-turn dialogues.
Another concern is the potential for data contamination in single-turn benchmarks. Models trained and evaluated on the same datasets may inadvertently memorize specific patterns, leading to inflated performance metrics that do not reflect true generalization capabilities. This issue underscores the importance of diverse and representative evaluation datasets to ensure that performance assessments are indicative of a model's real-world applicability.
Additionally, the static nature of many single-turn benchmarks fails to account for the evolving capabilities of LLMs. As models advance, benchmarks that do not adapt to these changes may become obsolete, failing to challenge newer models and hindering the progression of AI research. This stagnation can impede the development of more robust and versatile models.
To address these limitations, there is a growing emphasis on developing evaluation frameworks that encompass multi-turn interactions and complex reasoning tasks. Benchmarks like MINT (Multi-turn Interaction with Tools) aim to evaluate LLMs' abilities in tasks requiring multiple interactions and the use of external tools, providing a more accurate assessment of a model's performance in real-world scenarios.
In real-world, multi-turn applications, the ability of large language models (LLMs) to effectively manage shared contexts is paramount. Unlike single-turn interactions, multi-turn dialogues require models to maintain and update context over successive exchanges, ensuring coherence and relevance in responses. This capability is crucial in applications such as customer support, virtual assistants, and collaborative tools, where understanding the evolving context of a conversation is essential for providing accurate and helpful information.
Assessing solutions for shared contexts in these applications involves evaluating how well models retain and utilize information from previous interactions. Effective context management enables models to handle follow-up questions, clarify ambiguities, and adapt to changing user inputs, thereby enhancing the overall user experience. For instance, in a customer support scenario, a model that remembers a user's previous inquiries can provide more personalized and efficient assistance.
Recent research has highlighted the importance of context awareness in multi-turn dialogues. Studies have shown that enhancing contextual understanding significantly improves user satisfaction in conversational agents. This involves not only recognizing the immediate context but also understanding the broader conversation history to provide relevant and accurate responses.
Moreover, advancements in contextual retrieval have transformed AI systems by ensuring that even smaller chunks of information maintain relevance and clarity. This method involves adding specific contextual information to text chunks before they are embedded or indexed, preserving their relationship with broader documents. By doing so, contextual retrieval addresses a common issue where individual text chunks lose essential context, which can result in inaccurate or incomplete responses from AI models.
Introducing SCBench
SCBench is a benchmark developed to evaluate long-context methods in large language models (LLMs) through a Key-Value (KV) cache-centric framework. This approach categorizes long-context methods into four stages: generation, compression, retrieval, and loading. Each stage addresses specific aspects of managing and processing extensive contexts within LLMs.
In the generation stage, techniques such as sparse attention and prompt compression are employed to create representations of the input data. Sparse attention mechanisms focus on processing only the most relevant parts of the input, reducing computational complexity and memory usage. Prompt compression involves condensing the input prompts to retain essential information, thereby enhancing efficiency.
The compression stage includes methods like KV cache dropping and quantization. KV cache dropping selectively removes certain key-value pairs from the cache to free up memory, which can be particularly beneficial in resource-constrained environments. Quantization reduces the precision of the stored key-value pairs, decreasing memory requirements while attempting to maintain performance.
Retrieval focuses on fetching relevant KV cache blocks to optimize performance. This stage ensures that the model can access pertinent information from the cache efficiently, facilitating faster and more accurate responses.
The loading stage involves dynamically transferring KV data for computation. This process allows the model to access and utilize the necessary information from the cache as needed, balancing memory usage and computational efficiency.
SCBench evaluates these methods across 12 tasks and two shared context modes: multi-turn and multi-request. This comprehensive assessment provides insights into the performance of various long-context methods in real-world applications. The benchmark analyzes methods like sparse attention, compression, and retrieval on models such as Llama-3 and GLM-4.
By focusing on the KV cache lifecycle, SCBench offers a detailed analysis of how different methods manage and utilize context information. This perspective is crucial for understanding the strengths and limitations of various long-context solutions, guiding future developments in LLM architectures and applications.
SCBench introduces a comprehensive framework for evaluating long-context methods in large language models (LLMs), focusing on the Key-Value (KV) cache lifecycle. This framework is divided into four critical stages: generation, compression, retrieval, and loading. Each stage addresses specific challenges associated with managing and processing extensive contexts within LLMs.
KV Cache Generation
The first stage, KV cache generation, involves processing the input prompt to produce the KV cache used during decoding. This stage is crucial for efficiently handling long-context inputs, as it determines how the model encodes and stores information for subsequent use. Techniques such as sparse attention mechanisms, including A-shape, Tri-shape, and MInference, are employed to reduce the complexity of attention operations, thereby enhancing efficiency. Additionally, prompt compression methods, like LLMLingua-2, are utilized to condense input prompts, retaining essential information while reducing computational overhead.
KV Cache Compression
Following generation, the KV cache compression stage focuses on reducing the memory footprint of the generated cache. This is achieved through methods like KV cache dropping and quantization. KV cache dropping selectively removes certain key-value pairs from the cache to free up memory, which can be particularly beneficial in resource-constrained environments. Quantization reduces the precision of the stored key-value pairs, decreasing memory requirements while attempting to maintain performance.
KV Cache Retrieval
The third stage, KV cache retrieval, involves fetching relevant KV cache blocks to optimize performance. This process ensures that the model can access pertinent information from the cache efficiently, facilitating faster and more accurate responses. Approaches such as semantic retrieval methods, exemplified by CacheBlend, are employed to enhance the retrieval process, enabling the model to access relevant information from the cache more effectively.
KV Cache Loading
The final stage, KV cache loading, entails dynamically transferring KV data for computation. This process allows the model to access and utilize the necessary information from the cache as needed, balancing memory usage and computational efficiency. Techniques like Quest and RetrievalAttention are utilized to load only the necessary portions of the KV cache during each decoding step, thereby saving memory and computational costs.
By systematically evaluating these four stages, SCBench provides a comprehensive analysis of long-context methods, offering insights into their performance across various tasks and scenarios. This approach enables researchers and practitioners to identify strengths and weaknesses in different methods, guiding the development of more efficient and effective long-context solutions for LLMs.
SCBench is a comprehensive benchmark designed to evaluate long-context methods in large language models (LLMs) through a Key-Value (KV) cache-centric framework. It encompasses 12 tasks across two shared context modes—multi-turn and multi-request—assessing four key long-context capabilities: string retrieval, semantic retrieval, global information processing, and multi-tasking.
String Retrieval
String retrieval tasks assess the model's ability to locate and extract specific strings from extensive inputs. These tasks are fundamental for applications requiring precise information retrieval from large datasets. The three tasks in this category are:
Key-Value Retrieval: In this task, the model retrieves a specific key-value pair from a large collection, testing its efficiency in handling large-scale data retrieval.
Prefix-Suffix Retrieval: This task involves finding strings that match a given prefix and suffix within a dictionary, evaluating the model's pattern recognition capabilities.
Multi-Hop Retrieval: Here, the model tracks variable assignments across a long input, requiring it to maintain context over multiple steps to retrieve the correct information.
Semantic Retrieval
Semantic retrieval tasks evaluate the model's understanding of context and its ability to retrieve information based on meaning rather than exact matches. These tasks are crucial for applications like question answering and information extraction. The tasks in this category include:
Code Repository Question Answering (RepoQA): The model answers questions related to functions within a GitHub repository, testing its ability to understand and retrieve relevant code snippets.
English Question Answering (En.QA): This task involves answering general knowledge questions in English, assessing the model's comprehension and retrieval of information.
Chinese Question Answering (Zh.QA): Similar to En.QA, this task requires the model to answer general knowledge questions in Chinese, evaluating its multilingual retrieval capabilities.
English Multi-Choice Questions (En.MultiChoice): The model selects the correct answer from multiple choices, testing its understanding and retrieval of information in a multiple-choice format.
Global Information Processing
Global information processing tasks assess the model's ability to understand and aggregate information from large inputs, which is essential for tasks like summarization and in-context learning. The tasks in this category are:
Math Computation (Math.Find): The model performs mathematical computations within long sequence arrays, testing its ability to process and compute information from extensive data.
Many-Shot In-Context Learning (ICL.ManyShot): This task involves learning from hundreds of examples within the context, evaluating the model's capacity to generalize from large amounts of data.
Document Summarization (En.Sum): The model summarizes a document given multiple documents as input, assessing its ability to condense and synthesize information from extensive sources.
Multi-Tasking
Multi-tasking tasks evaluate the model's ability to handle multiple tasks simultaneously, sharing a long-context input. This capability is vital for applications requiring multitasking and efficient resource utilization. The tasks in this category include:
Mixed Summarization and Needle in a Haystack (Mix.Sum+NIAH): The model performs both summarization and information retrieval tasks, testing its multitasking abilities.
Mixed Repository Question Answering and Key-Value Retrieval (Mix.RepoQA+KV): This task requires the model to handle both code repository question answering and key-value retrieval simultaneously, evaluating its capacity to manage multiple tasks with shared context.
These tasks are evaluated across two shared context modes:
Multi-Turn Mode: In this mode, the model caches context within single sessions, allowing it to maintain continuity and coherence over multiple interactions.
Multi-Request Mode: Here, the model shares context across multiple sessions, enabling it to handle requests that span different interactions, reflecting real-world scenarios where context is retained over time.
By encompassing these diverse tasks and modes, SCBench provides a comprehensive evaluation of long-context methods, offering insights into their performance across various real-world applications.
Evaluation of Long-Context Methods
In the realm of large language models (LLMs), managing long-context inputs is a significant challenge due to the substantial computational and memory demands. To address these challenges, researchers have developed various methods, including sparse attention mechanisms, compression techniques, and retrieval strategies.
Sparse Attention Mechanisms
Sparse attention mechanisms are designed to reduce the computational complexity of processing long sequences by limiting the number of token interactions. Traditional attention mechanisms compute interactions between all pairs of tokens, resulting in quadratic time and space complexity. Sparse attention addresses this by focusing on a subset of tokens, thereby reducing the computational burden.
One notable approach is the Mixture of Attention (MoA) model, which automatically tailors distinct sparse attention configurations to different heads and layers. MoA constructs and navigates a search space of various attention patterns and their scaling rules relative to input sequence lengths. It profiles the model, evaluates potential configurations, and identifies the optimal sparse attention compression plan. This adaptability allows MoA to handle varying input sizes effectively, revealing that some attention heads expand their focus to accommodate longer sequences, while others consistently concentrate on fixed-length local contexts. Experiments have shown that MoA increases the effective context length by 3.9 times with the same average attention span, boosting retrieval accuracy by 1.5 to 7.1 times over the uniform-attention baseline across models like Vicuna-7B, Vicuna-13B, and Llama3-8B. Moreover, MoA narrows the capability gaps between sparse and dense models, reducing the maximum relative performance drop from 9%–36% to within 5% across two long-context understanding benchmarks. Additionally, MoA achieves a 1.2 to 1.4 times GPU memory reduction and boosts decoding throughput by 5.5 to 6.7 times for 7B and 13B dense models on a single GPU, with minimal impact on performance.
Another approach is SeerAttention, which argues that attention sparsity should be learned rather than predefined. SeerAttention introduces a new attention mechanism that learns the sparse patterns during training, allowing the model to adapt its attention distribution based on the input data. This method aims to improve the model's efficiency and performance by focusing on the most relevant parts of the input sequence.
Compression Techniques
Compression techniques aim to reduce the size and complexity of LLMs, making them more efficient for processing long-context inputs. One such method is LoSparse, which combines low-rank approximation and pruning to compress the model. LoSparse approximates a weight matrix by the sum of a low-rank matrix and a sparse matrix, effectively reducing the model's size while maintaining performance. This approach leverages the advantages of both low-rank approximations and pruning, avoiding their individual limitations. Experiments have shown that LoSparse significantly outperforms existing compression methods in natural language understanding, question answering, and natural language generation tasks.
Additionally, the Sparse RAG (Sparse Retrieval-Augmented Generation) framework accelerates inference by selectively attending to highly relevant contexts during decoding. Sparse RAG encodes retrieved documents in parallel, eliminating latency introduced by long-range attention of retrieved documents. Then, it selectively decodes the output by attending only to the most pertinent caches, chosen via prompting LLMs with special control tokens. This sparse mechanism reduces the number of documents loaded during decoding, enhancing inference speed without compromising generation quality.
Retrieval Strategies
Retrieval strategies enhance the model's ability to access and utilize external information, improving performance on tasks requiring knowledge beyond the model's training data. Sparse RAG, as mentioned earlier, is one such strategy that combines retrieval with sparse attention mechanisms to efficiently process long-context inputs. By selectively attending to relevant retrieved documents, Sparse RAG reduces computational overhead and improves response times.
In the evolving landscape of large language models (LLMs), the ability to process and generate long-context inputs is paramount. Models such as Llama-3 and GLM-4 have been at the forefront of this advancement, demonstrating significant strides in handling extended contexts. The introduction of SCBench, a comprehensive benchmark designed to evaluate long-context methods in LLMs, has provided valuable insights into the performance of these models.
SCBench employs a Key-Value (KV) cache-centric framework to assess various long-context methods across four stages: generation, compression, retrieval, and loading. This approach encompasses 12 tasks across two shared context modes—multi-turn and multi-request—evaluating capabilities such as string retrieval, semantic retrieval, global information processing, and multi-tasking. The benchmark analyzes methods like sparse attention, compression, and retrieval on models including Llama-3 and GLM-4. Results highlight that sub-O(n) memory methods struggle in multi-turn scenarios, while O(n) memory approaches perform robustly. SCBench provides insights into sparsity effects, task complexity, and challenges like distribution shifts in long-generation scenarios.
In the evaluation of GLM-4-9B, a model known for its extensive context handling capabilities, SCBench's findings indicate that methods maintaining KV cache at O(n) excel in multi-request scenarios, while sub-O(n) methods perform well in single-turn settings but struggle with complex interactions. These findings underscore the importance of multi-turn, shared-context scenarios in developing and evaluating long-context methods, offering a more realistic assessment of model performance.
The performance of Llama-3, particularly the 70B parameter variant, has also been noteworthy. In code generation tasks, Llama-3-70B has demonstrated superior performance compared to models like GPT-4 Turbo. This achievement highlights Llama-3's proficiency in understanding and generating code, a testament to its advanced contextual processing abilities.
Both Llama-3 and GLM-4 have been evaluated on SCBench, revealing that while these models exhibit strong performance in single-turn interactions, they face challenges in multi-turn scenarios. The KV cache-centric analysis provided by SCBench offers a nuanced understanding of how these models manage long-context inputs across different stages and tasks. This comprehensive evaluation is crucial for identifying areas of improvement and guiding future developments in LLM architectures.
In the realm of large language models (LLMs), effectively managing long-context inputs is crucial for tasks such as long-document question-answering and repository-level code analysis. However, this capability introduces several challenges, notably related to sparsity, task complexity, and distribution shifts, which can significantly impact model performance in long-generation scenarios.
Sparsity and Its Impact
Sparsity refers to the proportion of zero or inactive elements within a model's parameters or activations. In LLMs, introducing sparsity can lead to more efficient computations and reduced memory usage. However, achieving optimal sparsity levels is delicate; excessive sparsity can impair the model's ability to capture complex patterns, while insufficient sparsity may not yield the desired efficiency gains.
Recent studies have explored the effects of sparsity on LLM performance. For instance, research on activation sparsity within decoder-only Transformer-based LLMs has highlighted the importance of balancing sparsity to maintain model flexibility and performance. The study introduced PPL-sparsity, a metric designed to quantify activation sparsity, and found that while sparsity can enhance efficiency, it must be carefully managed to avoid negative impacts on model performance.
Moreover, the concept of dynamic sparsity, where the sparsity pattern adapts during training, has been shown to yield more expressive key-value (KV) caches compared to static patterns. This adaptability allows the model to focus computational resources on the most relevant parts of the input, enhancing efficiency without compromising performance.
Task Complexity
The complexity of the tasks that LLMs are trained on and evaluated against plays a significant role in their performance. Tasks that require understanding and generating long-context information demand models to maintain coherence over extended sequences, posing challenges in both training and inference phases.
For example, in code generation tasks, models must comprehend the structure and logic of code over potentially long spans. Studies have shown that models like Llama-3-70B outperform others, such as GPT-4 Turbo, in these scenarios, indicating that task complexity significantly influences model performance.
Additionally, the introduction of sparse pre-training and dense fine-tuning (SPDF) has been proposed to address task complexity. This approach involves training models with sparse weights during pre-training to reduce computational costs and then fine-tuning them with dense weights to recover performance. Experiments have demonstrated that this method can lead to substantial reductions in training FLOPs without significant accuracy loss on downstream tasks.
Distribution Shifts
Distribution shifts occur when the data encountered during inference differs from the data used during training. In long-generation scenarios, such shifts can lead to performance degradation, as the model may not generalize well to new contexts or domains.
Research has identified that attention distribution shifts are a significant challenge in long-generation tasks. As models generate longer sequences, the distribution of attention across different parts of the input can change, potentially leading to less coherent outputs. Addressing these shifts is crucial for improving model robustness in real-world applications.
To mitigate the effects of distribution shifts, techniques such as sparse fine-tuning have been explored. This method involves fine-tuning models with sparse weights, which has been shown to accelerate inference and reduce memory usage while maintaining performance. Notably, sparse fine-tuning can achieve significant speedups on both CPU and GPU platforms without compromising accuracy.
Implications for Future Research and Applications
SCBench, developed by researchers from Microsoft and the University of Surrey, is a comprehensive benchmark designed to evaluate long-context methods in large language models (LLMs). It employs a Key-Value (KV) cache-centric framework to assess various long-context solutions across four stages: generation, compression, retrieval, and loading. This approach provides a nuanced understanding of how different methods manage long-context inputs, offering valuable insights for the development of more efficient long-context techniques.
The benchmark evaluates methods such as sparse attention, compression, and retrieval on models including Llama-3 and GLM-4. Results highlight that sub-O(n) memory methods struggle in multi-turn scenarios, while O(n) memory approaches perform robustly. SCBench provides insights into sparsity effects, task complexity, and challenges like distribution shifts in long-generation scenarios.
By analyzing these methods across the four stages, SCBench identifies the strengths and weaknesses of each approach in handling long-context inputs. For instance, sparse attention methods may offer computational efficiency but can face challenges in maintaining coherence over extended contexts. Compression techniques might reduce memory usage but could potentially lose critical information, affecting performance. Retrieval methods can enhance efficiency by fetching relevant information but may introduce latency or inaccuracies if not properly managed. Loading strategies that dynamically transfer KV data for computation can optimize performance but require careful management to avoid overhead.
The insights gained from SCBench evaluations are instrumental in guiding the development of more efficient long-context methods. By understanding how different techniques perform across various stages and tasks, researchers and practitioners can make informed decisions about which methods to adopt or further refine. This knowledge is crucial for advancing LLM architectures that can effectively process and generate long-context information, thereby enhancing their applicability in real-world scenarios.
Long-context large language models (LLMs) have significantly advanced the capabilities of artificial intelligence across various domains, including code analysis, document processing, and in-context learning. These models, such as Llama 3, have demonstrated remarkable proficiency in understanding and generating human-like text, enabling more efficient and accurate processing of complex tasks.
Code Analysis
In the realm of code analysis, LLMs have shown considerable promise. A study titled "Large Language Models for Code Analysis: Do LLMs Really Do Their Job?" explores the effectiveness of LLMs in automating code analysis tasks. The research indicates that while LLMs can serve as valuable tools for code analysis, they do have certain limitations. The study emphasizes the need for further refinement to enhance their accuracy and reliability in this domain.
Additionally, the development of frameworks like LangChain has facilitated the integration of LLMs into code analysis applications. LangChain provides a platform for building applications that leverage LLMs for tasks such as code understanding and generation, thereby streamlining the development process and improving code quality.
Document Processing
LLMs have also made significant strides in document processing. Their ability to comprehend and generate human-like text enables them to perform tasks such as summarization, translation, and information extraction with high accuracy. This capability is particularly beneficial in scenarios where large volumes of text need to be processed efficiently.
For instance, LLMs can analyze extensive documents to extract key information, summarize content, and even generate reports, thereby reducing the time and effort required for manual processing. This has applications in various industries, including legal, healthcare, and finance, where document processing is a critical component of daily operations.
In-Context Learning
In-context learning refers to the model's ability to learn and adapt to new tasks based on the context provided within the input, without the need for explicit retraining. LLMs have demonstrated proficiency in in-context learning, enabling them to perform a wide range of tasks by understanding and utilizing the context provided in the input.
A study titled "In-Context Learning with Long-Context Models: An In-Depth Study" examines the behavior of in-context learning at an extreme scale on multiple datasets and models. The research shows that, for many datasets with large label spaces, performance continues to improve with hundreds or thousands of demonstrations, highlighting the potential of LLMs in in-context learning scenarios.
Furthermore, the development of specialized benchmarks like LongICLBench focuses on long in-context learning within the realm of extreme-label classification. This benchmark aims to evaluate the performance of LLMs in handling tasks that require understanding and processing extensive context, thereby advancing the field of in-context learning.
Conclusion
SCBench, developed by researchers from Microsoft and the University of Surrey, is a comprehensive benchmark designed to evaluate long-context methods in large language models (LLMs). It employs a Key-Value (KV) cache-centric framework to assess various long-context solutions across four stages: generation, compression, retrieval, and loading. This approach provides a nuanced understanding of how different methods manage long-context inputs, offering valuable insights for the development of more efficient long-context techniques.
The benchmark evaluates methods such as sparse attention, compression, and retrieval on models including Llama-3 and GLM-4. Results highlight that sub-O(n) memory methods struggle in multi-turn scenarios, while O(n) memory approaches perform robustly. SCBench provides insights into sparsity effects, task complexity, and challenges like distribution shifts in long-generation scenarios.
By analyzing these methods across the four stages, SCBench identifies the strengths and weaknesses of each approach in handling long-context inputs. For instance, sparse attention methods may offer computational efficiency but can face challenges in maintaining coherence over extended contexts. Compression techniques might reduce memory usage but could potentially lose critical information, affecting performance. Retrieval methods can enhance efficiency by fetching relevant information but may introduce latency or inaccuracies if not properly managed. Loading strategies that dynamically transfer KV data for computation can optimize performance but require careful management to avoid overhead.
The insights gained from SCBench evaluations are instrumental in guiding the development of more efficient long-context methods. By understanding how different techniques perform across various stages and tasks, researchers and practitioners can make informed decisions about which methods to adopt or further refine. This knowledge is crucial for advancing LLM architectures that can effectively process and generate long-context information, thereby enhancing their applicability in real-world scenarios.
Comprehensive benchmarking plays a pivotal role in advancing the capabilities of long-context large language models (LLMs). As these models evolve to handle increasingly complex tasks, traditional evaluation methods often fall short in capturing their true potential. This necessitates the development of specialized benchmarks that can rigorously assess the multifaceted abilities of LLMs in processing and generating extended contexts.
One of the primary challenges in evaluating long-context LLMs is the inadequacy of existing benchmarks to measure the quality of long-form text generation. While benchmarks like the "Needle-in-a-Haystack" (NIAH) test effectively assess a model's ability to locate specific information within large text sequences, they do not adequately evaluate the generation of coherent, extended text—a critical aspect for applications such as design proposals and creative writing.
To address this gap, researchers have introduced specialized benchmarks like LongGenBench, which focuses on evaluating LLMs' capacities in generating long-form text. This benchmark is designed to measure how well models can produce coherent and contextually relevant content over extended sequences, thereby providing a more accurate assessment of their long-context generation abilities.
Another significant challenge is the evaluation of LLMs in scenarios that require understanding and processing multiple documents. Traditional benchmarks often focus on single-document tasks, which do not reflect the complexities encountered in real-world applications. To bridge this gap, the Loong benchmark was introduced, aligning with realistic scenarios through extended multi-document question answering (QA). Unlike typical document QA, Loong's test cases require models to consider multiple documents, each relevant to the final answer, thereby providing a more comprehensive evaluation of their long-context understanding.
Furthermore, the LooGLE benchmark was developed to assess LLMs' long-context understanding capabilities. It features documents with over 24,000 tokens and includes newly generated questions spanning varying dependency ranges in diverse domains. Human annotators meticulously crafted over 1,100 high-quality question-answer pairs to ensure precise assessment of LLMs' long dependency capabilities.
These specialized benchmarks are crucial for several reasons. Firstly, they provide a standardized framework for evaluating the performance of LLMs in handling long-context inputs, ensuring consistency and comparability across different models and studies. Secondly, they highlight the strengths and weaknesses of current models, guiding researchers in identifying areas for improvement and directing future development efforts. Lastly, they facilitate the advancement of LLMs by setting clear performance metrics, thereby driving innovation and the development of more efficient and capable models.
In summary, comprehensive benchmarking is essential for advancing long-context LLM capabilities. By providing rigorous and standardized evaluations, specialized benchmarks enable a deeper understanding of model performance, inform the development of more effective models, and drive progress in the field of natural language processing.
Press contact
Timon Harz
oneboardhq@outlook.com
Other posts





Company
About
Blog
Careers
Press
Legal
Privacy
Terms
Security