Timon Harz
December 16, 2024
Meta AI Introduces Large Concept Models (LCMs): Advancing Beyond Token-based Language Modeling for Semantic Understanding
Explore how Meta's Large Concept Models revolutionize language processing by focusing on concepts over tokens, enhancing coherence, semantic understanding, and multimodal AI capabilities.

Large Language Models (LLMs) have made significant strides in natural language processing (NLP), facilitating tasks like text generation, summarization, and question-answering. Despite their success, LLMs face limitations due to their token-based processing, where each word is predicted sequentially. This method, while effective for certain tasks, does not align with the way humans communicate, often operating at a higher level of abstraction involving complete sentences or ideas. Furthermore, token-level models struggle with tasks that require long-context comprehension and may generate inconsistent outputs.
In addition, scaling these models for multilingual and multimodal tasks is both computationally expensive and data-intensive. To overcome these challenges, researchers at Meta AI have introduced Large Concept Models (LCMs), a new approach that promises to address these limitations by moving beyond the constraints of token-level processing.
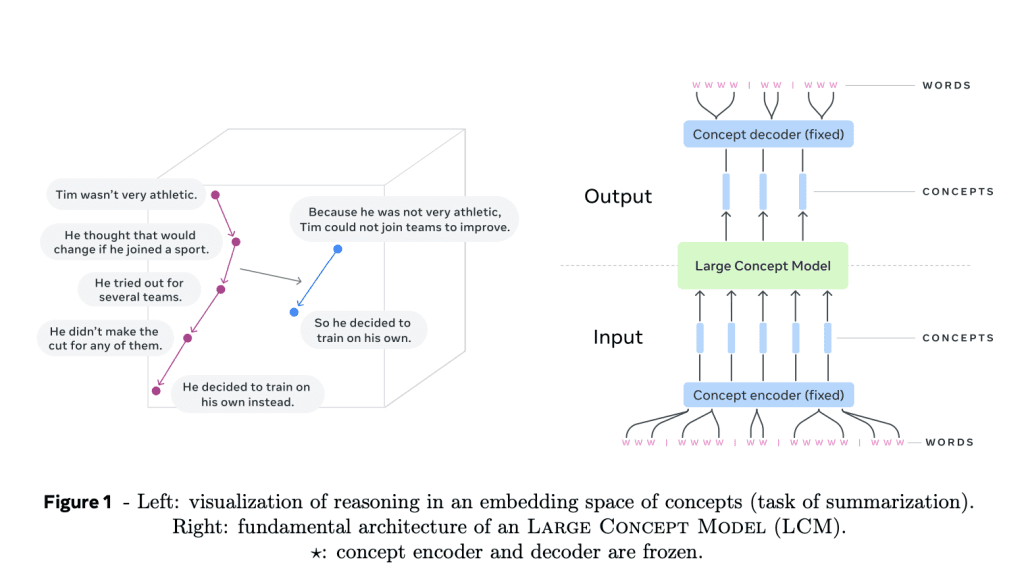
Large Concept Models (LCMs)
Meta AI's Large Concept Models (LCMs) mark a departure from traditional Large Language Model (LLM) architectures by introducing two key innovations:
High-dimensional Embedding Space Modeling: LCMs operate in a high-dimensional embedding space rather than processing discrete tokens. This space, known as SONAR, represents abstract semantic units—referred to as "concepts"—which are equivalent to full sentences or utterances. SONAR is designed to be both language- and modality-agnostic, supporting more than 200 languages and various modalities, including text and speech. This allows the model to process and generate content across languages and formats seamlessly.
Language- and Modality-Agnostic Modeling: Unlike traditional models, which are restricted to specific languages or modalities, LCMs work at a purely semantic level. This allows the model to easily transition between languages and modalities, offering enhanced zero-shot generalization across diverse applications. The core components of LCMs include concept encoders and decoders, which map sentences into SONAR’s embedding space and translate embeddings back into natural language or other modalities. The modular nature of these components means they remain fixed, simplifying the extension of LCMs to new languages or modalities without requiring the entire model to be retrained.
Technical Details and Benefits of Large Concept Models (LCMs)
Meta AI's Large Concept Models (LCMs) introduce several innovative features that enhance language modeling capabilities:
Hierarchical Architecture: LCMs utilize a hierarchical structure that mimics human cognitive processes. This design not only improves the coherence of long-form content but also allows for localized edits without disrupting the broader context. By structuring information in a more human-like way, LCMs can generate more contextually relevant and coherent outputs.
Diffusion-based Generation: Diffusion models were identified as the most effective approach for LCMs, offering a unique method for predicting the next SONAR embedding based on previous embeddings. Two distinct architectural approaches were explored:
One-Tower: In this approach, a single Transformer decoder is responsible for both encoding the context and performing denoising tasks.
Two-Tower: This model separates the context encoding and denoising processes into two distinct components, optimizing each task individually for better performance.
Scalability and Efficiency: By operating at the concept level rather than token-level, LCMs reduce sequence length, addressing the quadratic complexity of traditional Transformer models. This results in more efficient processing, especially for tasks requiring long-context understanding, enabling faster and more scalable performance.
Zero-shot Generalization: LCMs demonstrate exceptional zero-shot generalization. By leveraging SONAR’s vast multilingual and multimodal capabilities, LCMs perform well on languages and modalities they have never encountered before. This flexibility allows them to adapt easily to new and unseen data types without requiring extensive retraining.
Search and Stopping Criteria: LCMs employ a search algorithm that includes a stopping criterion based on proximity to an “end of document” concept. This ensures coherent and complete generation without the need for fine-tuning, streamlining the model’s functionality for real-world applications.

Insights from Experimental Results
Meta AI's experimental results demonstrate the strong potential of Large Concept Models (LCMs). In particular, a diffusion-based Two-Tower LCM with 7 billion parameters delivered competitive performance across several key tasks, including summarization. Some notable findings from these experiments include:
Multilingual Summarization: LCMs significantly outperformed baseline models in zero-shot summarization across multiple languages, underscoring their adaptability and ability to handle a variety of linguistic contexts without needing retraining.
Summary Expansion Task: A novel evaluation task revealed LCMs’ capability to generate expanded summaries that maintain coherence and consistency, showcasing the model's ability to understand and articulate complex ideas across different summary lengths.
Efficiency and Accuracy: LCMs were more efficient than traditional token-based models in processing shorter sequences while still maintaining high accuracy. Key performance metrics, including mutual information and contrastive accuracy, showed substantial improvements, highlighting LCMs' ability to generate high-quality outputs with greater computational efficiency.
Meta AI's Large Concept Models offer a promising advancement over traditional token-based models. By utilizing high-dimensional concept embeddings and language-agnostic processing, LCMs overcome several limitations of earlier models. Their hierarchical architecture improves coherence, efficiency, and scalability, while their strong zero-shot generalization ability allows for broad applicability across multiple languages and modalities. As research into LCMs continues, they have the potential to redefine the scope of language models, paving the way for more adaptable and scalable AI systems in the future.
The evolution of AI language models has significantly advanced over recent years, shifting from simple text generation systems to highly sophisticated tools capable of deep semantic understanding. Early models like rule-based systems or simple neural networks could only process and output text based on predefined patterns. However, the introduction of more complex architectures, such as transformers, marked a key turning point. Transformers, especially models like BERT and GPT, demonstrated an ability to understand the context and relationships between words, enabling machines to generate more coherent and contextually relevant text.
Today, large language models (LLMs) like GPT-4 and Meta’s LLAMA model have expanded these capabilities further. These models can not only generate human-like responses but also understand subtleties in language, such as tone, sentiment, and intent. With continuous improvements, LLMs have become integral in a wide range of applications, including chatbots, writing assistants, customer support, and more.
The focus has also shifted towards fine-tuning these models for specific tasks, enhancing their ability to perform highly specialized functions. The trend now is toward even more powerful and refined models that understand language more deeply, beyond just token-based processing, paving the way for a new era of semantic comprehension in AI.
Meta's advancements in large concept models (LCMs) are making significant strides in addressing the limitations of traditional token-based models. While token-based models process information one token at a time, LCMs can process entire sequences of tokens simultaneously, allowing them to better capture long-term dependencies and context across larger chunks of text. This shift enables more coherent and contextually accurate outputs for complex tasks, such as summarization or generative tasks.
Additionally, LCMs leverage multi-token prediction, which enhances the model's ability to process and generate multiple tokens at once. This approach offers faster inference times and improved performance, especially in large models. For instance, in code generation tasks, models with multi-token prediction have shown to outperform next-token models significantly, both in terms of solving problems and speed.
These advancements not only optimize model efficiency but also open new possibilities for applications in areas like software development, content creation, and education. The ability to handle larger, more complex datasets with greater speed and accuracy is positioning LCMs as a major breakthrough in AI development, surpassing the traditional limitations of token-based models.
The Limitations of Token-based Models
Traditional token-based language models process text by breaking it down into smaller units called tokens. These tokens are often words or subword components, which are then converted into numerical representations, typically through embedding techniques. This transformation enables the model to understand the semantic meaning behind the tokens and process them in the context of the surrounding text. The model's architecture, like the Transformer, leverages self-attention mechanisms to capture relationships between tokens, even those that are far apart in the sequence, which allows for coherent text generation.
However, token-based models face several challenges that limit their performance, especially when dealing with longer or more complex texts. One major limitation is handling the loss of context over long sequences. Since these models operate on fixed-length sequences, they can struggle to retain the broader context of lengthy documents, which leads to a loss of coherence and relevance in generated content. Additionally, token-based models can experience difficulty when encountering out-of-vocabulary tokens—words or subwords that weren't present in the model's training data. This problem can reduce the model's accuracy and hinder its ability to generate contextually appropriate text.
The computational complexity of processing long sequences of tokens also poses a significant issue. As text grows longer, the need for greater computational resources increases, which can limit the scalability and real-time application of these models. Some solutions to these problems include using subword tokenization techniques, such as Byte-Pair Encoding (BPE), which break rare words into more manageable subword units. Additionally, context-aware models and advancements in architectures like Sparse Transformers aim to mitigate these limitations by retaining context more efficiently.
Despite these innovations, token-based processing still faces fundamental challenges when it comes to capturing deep semantic understanding, particularly for very long texts. This is where Meta's introduction of Large Concept Models (LCMs) comes into play, pushing beyond the token-based approach to offer more nuanced and coherent semantic comprehension.
Token-based language models, despite their groundbreaking advancements in natural language processing (NLP), still face challenges that hinder their ability to perform nuanced tasks, particularly when it comes to maintaining deep contextual awareness over long sequences.
A primary limitation stems from the token window, the span of text that a model can process in a single pass. Tokens are chunks of text (often parts of words or individual words) that models break down into numerical representations. These token windows are usually fixed in size, meaning that the model is unable to remember more than a set number of tokens at a time. For instance, while newer models may support windows of up to 32,000 tokens or more, they still struggle to retain context beyond this window.
This constraint becomes particularly evident in tasks requiring long-term coherence, like document summarization or answering specific questions based on large bodies of text. When dealing with texts that exceed the model's token capacity, earlier parts of the input might be truncated or ignored, resulting in a loss of important context. This can lead to errors or omissions, especially when the model needs to connect the dots between distant pieces of information.
Moreover, token-based models often have difficulty with fine-grained semantic understanding. For example, while they excel at generating grammatically correct and contextually plausible text, they can struggle with tasks that require a nuanced interpretation of meaning or understanding implied information. This is because they rely heavily on patterns within their training data, which sometimes leads to over-generalization or superficial engagement with complex or ambiguous content.
As a result, models can provide answers that are technically accurate but miss deeper, subtle nuances—such as irony, metaphor, or rare language constructs—that human users often expect in advanced conversational or reasoning tasks. The reliance on context windows further complicates this, as the model might lose track of critical information necessary for these subtleties.
Recent innovations, such as context-aware models and dynamic tokenization, aim to address these issues by providing better means for retaining context and improving semantic understanding over longer text sequences. These efforts point toward future advancements that could lead to models capable of handling more intricate tasks with greater precision, offering a more seamless and human-like interaction.
What Are Large Concept Models (LCMs)?
Meta's introduction of Large Concept Models (LCMs) represents a significant shift in how AI models understand and process language. Traditional token-based models, such as the widely-used transformers, process language by breaking text down into smaller units (tokens) and predicting the next token in sequence. While highly effective at tasks like machine translation and text generation, this token-based approach sometimes struggles with capturing deeper semantic relationships across larger text spans.
LCMs aim to overcome these limitations by focusing on processing semantic meaning beyond the token level. Instead of merely predicting individual tokens, LCMs work on identifying and modeling concepts as abstract units of meaning. This shift allows them to understand how these concepts relate to one another, thus enabling the model to grasp deeper contextual information within a broader scope of text. By focusing on the structure of ideas, rather than just word sequences, LCMs can more effectively handle complex tasks that require nuanced understanding, like abstract reasoning and long-form comprehension.
Moreover, LCMs leverage advancements in multi-token prediction. By training the model to predict sequences of tokens simultaneously, rather than one at a time, LCMs can better capture long-term dependencies and patterns within the data. This approach also leads to faster inference, as the model processes larger chunks of data at once, thus making it more efficient for real-world applications.
The move towards concept-based models marks a departure from traditional token-focused training, making it possible to integrate more sophisticated levels of abstraction. As a result, LCMs can be applied to areas requiring detailed semantic analysis, such as summarization, question answering, and more complex conversational agents, offering a clearer and more intuitive understanding of human language.
Meta AI’s approach with Large Concept Models (LCMs) represents a significant shift from traditional token-based language models. LCMs are designed to handle much longer contexts, extending the model’s understanding beyond the limitations of fixed-length context windows. This ability to process lengthy sequences of data enables a deeper, more nuanced understanding of text, making these models better equipped to capture complex semantic relationships across extended content.
Traditional language models are often constrained by a context window, which limits their ability to maintain coherence over long passages or handle dependencies that span large sections of text. For instance, as a text exceeds the model’s context window, crucial information from earlier in the text can be discarded, which severely affects performance. Meta AI’s LCMs address this challenge by enhancing the model's memory and context management, enabling it to maintain the integrity of its understanding across longer documents. This allows for more accurate semantic analysis, where the model can track the progression of ideas and arguments that may unfold over hundreds or even thousands of tokens.
The key to LCMs' capability is their ability to manage semantic relationships over extended contexts, something that traditional models struggle with when tasked with longer or more intricate documents. Research, such as the LooGLE benchmark, has shown that even large models with expanded context windows often fail to capture these long-term dependencies effectively. Meta AI's LCMs, however, leverage advanced mechanisms like attention sinks, which prioritize the most relevant context for maintaining coherence and capturing long-range dependencies.
This shift to handling larger contexts is not just about pushing the limits of the context window; it's about fundamentally rethinking how language models engage with the semantic structures of text. By allowing models to retain and build on prior information throughout the entire document, LCMs promise to improve everything from document summarization to complex question-answering tasks, where the relationships between parts of the text are crucial for accurate understanding.
As Meta AI continues to refine these models, we can expect even more breakthroughs in semantic comprehension, unlocking capabilities that were once seen as out of reach for traditional token-based systems.
Key Features of Meta's LCMs
Meta's Large Concept Models (LCMs) stand out primarily for their ability to handle incredibly long context windows—up to 32,768 tokens. This breakthrough capability goes beyond traditional token-based models, offering an advanced form of semantic understanding that drastically improves how models process and retain information. Context length has been a significant limitation for many large language models (LLMs), with earlier models often unable to retain all relevant data in a conversation or a document due to their constrained context window. Meta’s LCMs, however, can handle much larger chunks of data, making them better suited for complex, multi-turn conversations, long documents, or intricate tasks that require deep knowledge retention over extended periods.
The advantages of these extended context windows are evident in various applications. For example, LCMs can now process entire research papers, detailed reports, or complex datasets in a single pass, without losing important nuances. This enhanced capability allows for more accurate reasoning, better contextual understanding, and a richer interpretation of information. In comparison to traditional models, which might lose track of crucial details when the token limit is reached, Meta's approach ensures that every bit of input remains relevant throughout the entire process. This is particularly beneficial for tasks like summarization, document analysis, and even code generation, where maintaining context over a long span is essential.
Moreover, the ability to manage such large windows doesn't just improve performance in technical tasks but also in natural conversations. LCMs can maintain the flow of dialogue over extended interactions, better mimicking the continuity of human discourse. This makes them ideal for applications like virtual assistants, chatbots, or even interactive storytelling, where preserving earlier parts of the conversation or narrative is crucial for coherence.
Overall, Meta’s extension to 32,768 tokens marks a significant leap forward in the capacity of AI systems to process and understand large volumes of information, making them far more capable of handling complex real-world scenarios with depth and accuracy.
Improved Semantic Understanding with Meta AI's Large Concept Models (LCMs)
Meta's introduction of Large Concept Models (LCMs) marks a significant leap forward in AI's capacity for semantic understanding, distinguishing itself from traditional token-based language models. While token-based models excel at handling sequences of words and their relationships based on statistical patterns, LCMs take this a step further by emphasizing deeper comprehension of text. Instead of merely focusing on the individual tokens or words within a sentence, LCMs aim to grasp the broader, underlying meanings and concepts that drive communication.
At the core of token-based models like GPT-3, each word is reduced to a token—a discrete unit that often lacks the richness of the word's full meaning in context. These models typically work by learning the probability distribution of sequences of tokens. While they are highly effective in many tasks, they can struggle with tasks that require deep comprehension or nuanced contextual understanding.
LCMs, on the other hand, are designed to move beyond token-level analysis by understanding the context and the concepts that each word or phrase represents. This shift allows LCMs to grasp the "big picture" and connect ideas that are semantically related, even if they aren't directly adjacent in the text. For example, in tasks that require interpretation of abstract concepts or nuanced relationships, LCMs can identify these themes even when they are spread across large sections of text. This leads to more accurate and meaningful responses in complex scenarios.
The semantic depth of LCMs is further enhanced by their ability to handle multi-layered inputs, such as combining information from external sources or learning from expert models dynamically. This capability allows LCMs to go beyond rote word matching, ensuring that the underlying concepts of the text are properly understood and interpreted in a way that aligns with human-like reasoning. In practical terms, LCMs can support more advanced AI applications, such as complex decision-making, creative content generation, and more sophisticated conversational agents.
As LCMs evolve, their ability to incorporate domain-specific knowledge and adapt to different contexts will likely push the boundaries of semantic understanding, paving the way for more intuitive and human-like AI interactions. This represents a crucial step in the transition from basic language modeling to truly intelligent systems capable of nuanced reasoning and contextual comprehension.
Meta has been refining positional encoding to improve the handling of long-contexts, which has traditionally been a challenge in transformer models. The key challenge with long-context models is maintaining the relevance and accuracy of information as the length of the input increases, as most models have been designed with a limited attention span. Meta's enhancements, particularly with LLaMA models, address this limitation by improving how positional information is encoded and scaled for long sequences.
One significant advancement is Meta's introduction of Middle-Focused Positional Encoding. This approach adjusts the way the model attends to different parts of the input sequence, with a particular focus on the "middle" of the sequence. This is crucial because, in longer contexts, important information can be "lost" as the model struggles to manage vast input sizes. By emphasizing the central portion of the input, this method ensures that the model pays more attention to the middle sections of the context, which often contain the most relevant information.
The approach has been dubbed CREAM (Continuity-Relativity Indexing with Gaussian Middle), and it efficiently extends the context window of pre-trained models. It works by manipulating positional encoding through interpolation and a truncated Gaussian distribution. The focus on the middle of the context not only optimizes memory usage but also prevents the "Lost-in-the-Middle" problem, where crucial details from the center of the input would otherwise be ignored as the context grows.
These improvements make Meta's long-context models highly scalable, allowing for target context lengths as large as 256k tokens. The fine-tuning process needed for this extension is minimal, focusing only on the pre-trained context window, thus maintaining computational efficiency. This technique has shown promising results across both base and chat versions of LLaMA, making it a competitive choice in the race for better handling long-form inputs in natural language processing tasks.
Impact on Natural Language Processing
Meta's introduction of Large Concept Models (LCMs) signals an exciting leap forward in AI, particularly in enhancing complex tasks like content summarization, sentiment analysis, and dialogue systems. LCMs are designed to understand and process semantics in a way that traditional token-based language models couldn't, paving the way for AI systems with better context awareness, nuanced interpretations, and broader generalization capabilities.
In content summarization, LCMs can significantly improve performance by grasping the core concepts of a text, making them more adept at delivering concise and coherent summaries. Unlike previous models, which may focus on extracting surface-level information, LCMs aim to understand the deeper meaning of the content. This allows them to provide more accurate and contextually relevant summaries, even when the original text contains complex structures or subtle nuances.
For sentiment analysis, the ability of LCMs to interpret the underlying context of a statement greatly enhances their accuracy. They can detect not only overt emotions like happiness or sadness but also more complex sentiments such as sarcasm, irony, or shifts in tone within the same document. This makes LCMs especially valuable for applications like social media monitoring, customer feedback analysis, and brand sentiment tracking, where understanding the intricacies of human emotion is essential. They also enable the detection of fine-grained sentiment, helping businesses and researchers derive actionable insights from large datasets with far greater precision.
In dialogue systems, LCMs excel by offering a more fluid and context-aware conversational flow. While traditional language models often rely on token-based predictions that can result in disjointed or contextually inappropriate responses, LCMs bring a deeper understanding of the dialogue's intent, tone, and purpose. This makes them ideal for applications such as customer support bots, virtual assistants, and interactive AI systems, where maintaining a natural and coherent conversation is crucial. The ability to tailor responses based on ongoing context allows these systems to better serve users, leading to improved user experiences and more meaningful interactions.
These advancements highlight the broader implications of LCMs for AI applications. By moving beyond token-based models, LCMs offer enhanced capabilities in tasks that require deep semantic understanding. As LCMs continue to evolve, they promise to redefine how AI systems process and respond to human language, driving significant improvements across a range of industries and use cases.
Meta's introduction of Large Concept Models (LCMs) represents a key advancement in AI by moving beyond traditional token-based language modeling. These models aim to handle more sophisticated semantic understanding by organizing vast amounts of information into more complex structures. This shift has profound implications for improving AI's ability to comprehend, process, and generate content based on more meaningful concepts rather than isolated tokens.
In research, LCMs can enable deeper understanding across various domains by making models better at grasping the relationships between abstract concepts. This will be particularly useful in fields like medical research, where AI could more effectively connect complex biological data with existing knowledge to propose new insights. Additionally, LCMs are poised to enhance content generation, particularly for tasks requiring nuanced context, such as drafting academic papers, creating personalized marketing content, or even generating more sophisticated storytelling in media.
Real-world applications could see LCMs revolutionizing industries by providing more precise and context-aware AI systems. For example, in healthcare, they could assist in interpreting intricate medical records and aiding in more accurate diagnoses. Similarly, in autonomous vehicles, LCMs could improve AI’s ability to understand dynamic environments by connecting observed patterns with real-world concepts, facilitating safer navigation. The improved reasoning and contextual understanding offered by these models could also drive advancements in AI-based customer support systems, content recommendation engines, and even fraud detection.
Ultimately, by leveraging LCMs, Meta's AI systems will be able to handle more complex, real-world tasks that demand a higher level of understanding, opening the door to better AI applications that can handle ambiguity, nuance, and the deep semantic layers that characterize human knowledge.
Meta’s Approach to Data Curation
Meta's development of Large Concept Models (LCMs) underscores a strategic emphasis on data quality over sheer dataset size, a principle that has been pivotal to their success. This approach recognizes that the efficacy of AI models is significantly enhanced by the relevance and accuracy of the training data, rather than merely the volume.
Data Curation and Quality Assurance
Meta's AI research division has implemented rigorous data curation processes to ensure that the datasets used for training LCMs are of the highest quality. This involves meticulous selection and preprocessing of data to eliminate noise and redundancy, thereby enhancing the model's ability to learn meaningful patterns and relationships. By focusing on high-quality datasets, Meta ensures that LCMs are trained on information that is both accurate and representative of the complexities of human language and knowledge.
Advantages of Prioritizing Data Quality
Enhanced Model Performance: High-quality data enables LCMs to achieve superior performance across various tasks, including language understanding, generation, and reasoning. The models can make more accurate predictions and generate more coherent outputs when trained on datasets that accurately reflect the nuances of human language.
Efficient Training Processes: Focusing on data quality reduces the computational resources required for training. High-quality datasets lead to faster convergence during training, as the model can learn from clear and relevant examples without being distracted by irrelevant or incorrect data points.
Mitigation of Bias and Ethical Concerns: Careful data selection helps in identifying and mitigating biases present in the training data. By ensuring that the datasets are balanced and representative, Meta aims to develop LCMs that produce fair and unbiased outcomes, addressing ethical concerns associated with AI deployment.
Implementation Strategies
Data Annotation and Labeling: Meta employs advanced data annotation techniques to accurately label training data, ensuring that the models receive precise information during the learning process. This meticulous labeling is crucial for tasks that require a deep understanding of context and semantics.
Collaborations and Open Datasets: In collaboration with academic institutions and other organizations, Meta contributes to the creation and dissemination of high-quality open datasets. For instance, initiatives like the release of public domain books for AI training provide valuable resources for the research community, promoting transparency and collective advancement in AI development.
Challenges and Considerations
While prioritizing data quality offers significant advantages, it also presents challenges:
Resource Intensiveness: The process of curating and annotating high-quality datasets is resource-intensive, requiring substantial human and computational effort. However, the long-term benefits in model performance and reliability justify these investments.
Dynamic Nature of Data: Language and information are constantly evolving, necessitating continuous updates and maintenance of datasets to ensure they remain relevant and accurate. Meta addresses this by implementing ongoing data review and updating mechanisms.
Meta's development of Large Concept Models (LCMs) marks a significant departure from traditional AI methodologies, emphasizing data quality over sheer quantity. This strategic shift addresses inherent limitations in earlier models and paves the way for more robust AI systems capable of effectively handling diverse data types.
Traditional AI Approaches: Quantity Over Quality
Historically, AI development has often prioritized the accumulation of vast datasets, operating under the assumption that larger data volumes inherently lead to better model performance. This approach, while yielding certain successes, has encountered notable challenges:
Diminishing Returns: As datasets expand, the incremental benefits to model performance tend to decrease. Beyond a certain threshold, adding more data does not proportionally enhance accuracy or generalization capabilities.
Data Redundancy and Noise: Larger datasets often contain repetitive or irrelevant information, which can obscure meaningful patterns and impede the learning process. This noise necessitates additional computational resources for data cleaning and preprocessing.
Computational Constraints: Processing and storing massive datasets demand substantial computational power and infrastructure, leading to increased costs and potential environmental impacts.
Meta's Quality-Centric Approach with LCMs
In contrast, Meta's LCMs prioritize the curation of high-quality, diverse, and representative datasets. This methodology offers several advantages:
Enhanced Learning Efficiency: High-quality data enables models to learn more effectively, capturing complex patterns and relationships without the interference of noise. This leads to improved performance even with comparatively smaller datasets.
Improved Generalization: Focusing on data quality ensures that models are exposed to a wide range of scenarios and variations, enhancing their ability to generalize across different contexts and reducing the risk of overfitting.
Ethical AI Development: Careful data selection helps mitigate biases, promoting fairness and inclusivity in AI applications. This is crucial for developing AI systems that are trustworthy and socially responsible.
Robustness Across Diverse Data Types
By emphasizing data quality, LCMs are better equipped to handle various data types, including text, images, and multimodal inputs. This versatility is achieved through:
Modality-Agnostic Processing: LCMs are designed to process different data modalities within a unified framework, enabling seamless integration and interpretation of diverse information sources.
Hierarchical Representations: LCMs utilize hierarchical architectures to capture both high-level concepts and fine-grained details, facilitating a deeper understanding of complex data structures.
Implications for Future AI Development
Meta's quality-focused approach challenges the traditional paradigm of data quantity, highlighting the importance of thoughtful data curation in AI development. This paradigm shift has several implications:
Resource Optimization: Investing in data quality can reduce the need for extensive computational resources, making AI development more sustainable and accessible.
Accelerated Innovation: High-quality datasets enable faster training and iteration cycles, accelerating the development of advanced AI models and applications.
Enhanced Collaboration: Sharing curated, high-quality datasets fosters collaboration within the AI community, promoting transparency and collective progress.
In summary, Meta's emphasis on data quality over quantity represents a transformative approach in AI development. By addressing the limitations of traditional methods, LCMs offer a pathway to more robust, efficient, and ethical AI systems capable of effectively handling diverse data types and complex real-world challenges.
Practical Applications and Future Prospects
Meta's development of Large Concept Models (LCMs) signifies a transformative advancement in artificial intelligence, with the potential to revolutionize various sectors by enhancing AI capabilities in understanding and processing complex information.
AI Research
In the realm of AI research, LCMs are poised to drive significant progress by enabling more sophisticated modeling of human cognition and language. Their ability to process and integrate vast amounts of data across different modalities allows researchers to develop AI systems that can reason, plan, and learn in ways that closely mirror human thought processes. This advancement opens new avenues for exploring complex problems, such as natural language understanding, machine reasoning, and the development of more intuitive human-computer interactions.
User-Facing Applications
For user-facing applications, LCMs can enhance personalization and user engagement. By comprehending nuanced user inputs and maintaining context over extended interactions, these models can power more responsive virtual assistants, provide tailored content recommendations, and facilitate more natural conversational agents. This leads to improved user satisfaction and more intuitive interfaces across various platforms, from customer service chatbots to personalized educational tools.
Healthcare
In healthcare, LCMs have the potential to transform patient care and medical research. Their advanced processing capabilities can assist in diagnosing complex conditions by analyzing diverse data sources, including medical literature, patient records, and diagnostic images. This comprehensive analysis supports healthcare professionals in making informed decisions, leading to more accurate diagnoses and personalized treatment plans. Additionally, LCMs can streamline administrative tasks, such as managing patient information and coordinating care, thereby improving operational efficiency within healthcare facilities.
Education
In the educational sector, LCMs can facilitate personalized learning experiences by adapting educational content to individual student needs. They can analyze a student's learning style, strengths, and areas for improvement to provide customized resources and feedback. Furthermore, LCMs can assist educators in developing more effective teaching strategies by analyzing educational data and identifying trends that inform curriculum development. This personalized approach has the potential to enhance student engagement and improve learning outcomes.
Customer Service
In customer service, LCMs can enhance the efficiency and effectiveness of interactions between businesses and customers. By understanding and processing complex customer queries, these models can provide accurate and contextually appropriate responses, reducing the need for human intervention in routine inquiries. This leads to faster resolution times and improved customer satisfaction. Moreover, LCMs can analyze customer interactions to identify common issues and inform the development of better products and services.
Meta's commitment to advancing artificial intelligence is exemplified by its development of Large Concept Models (LCMs) and the open-source release of sophisticated language models like Llama 3.1. This approach not only accelerates AI research but also democratizes access to cutting-edge technologies, fostering innovation across various sectors.
Meta's Open-Source Initiatives
Meta has a history of open-sourcing its AI models, with the Llama series being a prominent example. The latest iteration, Llama 3.1, includes models with up to 405 billion parameters, making it the largest open-source AI system to date. These models are designed to support a broad range of use cases, from research to practical applications, and are available for fine-tuning and deployment by developers worldwide.
Democratizing Access to AI
By releasing these models openly, Meta enables researchers, developers, and organizations to leverage advanced AI capabilities without the need for extensive computational resources. This democratization facilitates:
Innovation: Developers can build upon Meta's models to create new applications, driving progress in AI technologies.
Collaboration: Open access encourages collaboration within the AI community, leading to shared advancements and collective problem-solving.
Education: Academic institutions can utilize these models for educational purposes, training the next generation of AI researchers and practitioners.
Advancements in Long-Context Language Models
Meta's research into long-context language models addresses the challenge of processing extended sequences of text, enabling models to maintain coherence and context over longer passages. This capability is crucial for applications such as document summarization, long-form content generation, and complex conversational agents. Meta's models support context windows of up to 32,768 tokens, outperforming existing open-source models in this regard.
Implications for the AI Community
Meta's open-source strategy has several siions:
Accelerated Research: Researchers can access state-of-the-art models without the barriers of proprietary restrictions, expediting experimental processes and discoveries.
Resource Accessibility: Organizations with limited resources can implement advanced AI solutions, promoting inclusivity and diversity in AI development.
Ethical AI Development: Open access allows for broader scrutiny and ethical considerations, ensuring that AI systems are developed responsibly and transparently.
Conclusion
Meta's development of Large Concept Models (LCMs) represents a significant advancement in the field of artificial intelligence, moving beyond traditional token-based language modeling to a more nuanced understanding of language and semantics.
Traditional Token-Based Models
Traditional language models operate by breaking down text into smaller units known as tokens, which can be as small as individual characters or as large as entire words. These models predict the next token in a sequence based on the preceding ones, enabling them to generate coherent text and perform various language-related tasks. However, this token-based approach has inherent limitations:
Limited Contextual Understanding: Token-based models often struggle to maintain coherence over long passages of text, as their context window is typically limited. This constraint can lead to challenges in tasks that require understanding and generating long-form content.
Surface-Level Semantics: Focusing on individual tokens may cause models to miss deeper semantic relationships, resulting in outputs that are syntactically correct but semantically shallow or inconsistent.
Handling Ambiguity: Tokens can be ambiguous, especially in languages with rich morphology or homonyms, making it difficult for models to accurately capture the intended meaning without extensive context.
Introduction to Large Concept Models (LCMs)
To address these limitations, Meta has introduced Large Concept Models, which aim to process language at a higher level of abstraction by focusing on entire sentences or concepts rather than individual tokens. This approach involves:
Semantic Embeddings: LCMs convert entire sentences into high-dimensional vectors, capturing the underlying meaning and context. This method allows the model to understand and generate text based on semantic content rather than just syntactic structures.
Extended Context Windows: LCMs are designed to handle longer contexts, with the ability to process up to 32,768 tokens. This capability enables the model to maintain coherence and context over extended passages, improving performance in tasks like document summarization and long-form content generation.
Hierarchical Architecture: By utilizing a hierarchical structure, LCMs can process information at multiple levels of granularity, from individual sentences to entire documents, enhancing their ability to capture complex semantic relationships.
Advantages of LCMs
The shift to concept-based modeling offers several significant benefits:
Improved Coherence: By understanding and generating text at the sentence or concept level, LCMs can produce more coherent and contextually appropriate outputs, especially in tasks involving long-form content.
Enhanced Semantic Understanding: LCMs' focus on semantic content allows them to grasp deeper meanings and relationships within the text, leading to more accurate and relevant responses in complex tasks.
Multimodal Integration: The modality-agnostic nature of LCMs enables them to process and integrate information from various sources, such as text, images, and audio, facilitating more comprehensive understanding and generation capabilities.
Implications for AI Applications
The advancements brought by LCMs have far-reaching implications across various AI applications:
Content Summarization: LCMs can generate more accurate and coherent summaries of lengthy documents by effectively processing extended contexts and capturing the essential semantic content.
Sentiment Analysis: By understanding the deeper meaning of text, LCMs can perform sentiment analysis with greater accuracy, even in cases involving nuanced or context-dependent sentiments.
Dialogue Systems: LCMs enhance the performance of conversational agents by maintaining context over longer interactions and generating responses that are both contextually appropriate and semantically rich.
Meta's Commitment to Open Research
Meta's ongoing research and commitment to open-sourcing advancements in AI, such as the release of models like Llama 3, play a crucial role in democratizing access to cutting-edge technologies. This openness fosters collaboration and innovation within the AI community, enabling researchers and developers worldwide to build upon these advancements and contribute to the field's rapid evolution.
Meta's Large Concept Models represent a transformative leap in language modeling, moving beyond the constraints of token-based approaches to a more sophisticated understanding of language and semantics. By focusing on entire concepts and extending context capabilities, LCMs address the limitations of traditional models, paving the way for more advanced and versatile AI applications across various domains.
Meta's development of Large Concept Models (LCMs) signifies a transformative shift in artificial intelligence, moving beyond traditional token-based language modeling to a more nuanced understanding of language and semantics. LCMs process language at a higher level of abstraction, focusing on entire sentences or concepts rather than individual tokens. This approach enhances coherence, semantic understanding, and the ability to handle longer contexts, with the capacity to process up to 32,768 tokens.
By leveraging high-dimensional concept embeddings and modality-agnostic processing, LCMs address key limitations of existing approaches. Their hierarchical architecture enhances coherence and efficiency, while their strong zero-shot generalization expands their applicability to diverse languages and modalities.
Meta's commitment to open research and collaboration is evident in its open-source strategy, which has several significant implications:
Accelerated Research: Researchers can access state-of-the-art models without the barriers of proprietary restrictions, expediting experimental processes and discoveries.
Resource Accessibility: Organizations with limited resources can implement advanced AI solutions, promoting inclusivity and diversity in AI development.
Ethical AI Development: Open access allows for broader scrutiny and ethical considerations, ensuring that AI systems are developed responsibly and transparently.
Meta's ongoing research and commitment to open-sourcing advancements in AI, such as the release of models like Llama 3, play a crucial role in democratizing access to cutting-edge technologies. This openness fosters collaboration and innovation within the AI community, enabling researchers and developers worldwide to build upon these advancements and contribute to the field's rapid evolution.
The advancements brought by LCMs have far-reaching implications across various AI applications:
Content Summarization: LCMs can generate more accurate and coherent summaries of lengthy documents by effectively processing extended contexts and capturing the essential semantic content.
Sentiment Analysis: By understanding the deeper meaning of text, LCMs can perform sentiment analysis with greater accuracy, even in cases involving nuanced or context-dependent sentiments.
Dialogue Systems: LCMs enhance the performance of conversational agents by maintaining context over longer interactions and generating responses that are both contextually appropriate and semantically rich.
As Meta continues to push the boundaries of AI research, the future holds exciting possibilities for Large Concept Models. Their potential applications span various industries, including healthcare, education, and customer service, where a deeper understanding of language and context is crucial.
Press contact
Timon Harz
oneboardhq@outlook.com
Other posts





Company
About
Blog
Careers
Press
Legal
Privacy
Terms
Security