Timon Harz
December 12, 2024
Meet GRAPE: A Plug-and-Play Algorithm for Generalizing Robot Policies with Preference Alignment
From Imitation to Generalization: The Next Leap in Robotic Learning How GRAPE Aligns Preferences to Revolutionize Vision-Language-Action Models

The field of robotic manipulation has been revolutionized by the advent of vision-language-action (VLA) models, which have shown remarkable potential in performing complex tasks across varied environments. However, these models face significant challenges in generalizing to new situations, such as unfamiliar objects, environments, and contexts.
At the core of these challenges lies the limitations of current training methods, particularly supervised fine-tuning (SFT). This approach, which mainly relies on behavioral imitation and successful action rollouts, prevents models from fully grasping task objectives and understanding potential failure points. As a result, these models often struggle to adapt to subtle variations or unexpected scenarios, emphasizing the need for more advanced training techniques.
Prior research in robotic learning has largely focused on hierarchical planning methods, with models like Code as Policies and EmbodiedGPT leveraging large language models and vision-language models to generate high-level action plans. These strategies typically use large language models to produce action sequences, which are then followed by low-level controllers to address local trajectory issues. However, these approaches face significant challenges in terms of skill adaptability and generalization for everyday robotic manipulation tasks.
VLA models have explored two primary strategies for action planning: action space discretization and diffusion models. The discretization method, exemplified by OpenVLA, divides action spaces into discrete tokens while maintaining autoregressive language decoding. Diffusion models, on the other hand, generate action sequences through multiple denoising steps rather than single-step actions. Despite these different approaches, both still rely on supervised training using successful action rollouts, which limits their ability to generalize to novel manipulation tasks.
Researchers from UNC Chapel-Hill, the University of Washington, and the University of Chicago have introduced GRAPE (Generalizing Robot Policy via Preference Alignment), a groundbreaking method designed to overcome key limitations in VLA model training. GRAPE features a powerful trajectory-wise preference optimization (TPO) technique that aligns robotic policies by implicitly modeling rewards from both successful and unsuccessful trial sequences. This approach enhances generalizability across a wide range of manipulation tasks, moving beyond traditional training methods.
At the heart of GRAPE is an advanced decomposition strategy that breaks down complex tasks into independent stages. This method provides exceptional flexibility by leveraging a large vision model to identify critical keypoints for each stage, linking them to spatial-temporal constraints. These adaptable constraints enable alignment with diverse manipulation goals, such as task completion, safety in robot interactions, and operational cost-efficiency, representing a major step forward in the development of robotic policies.
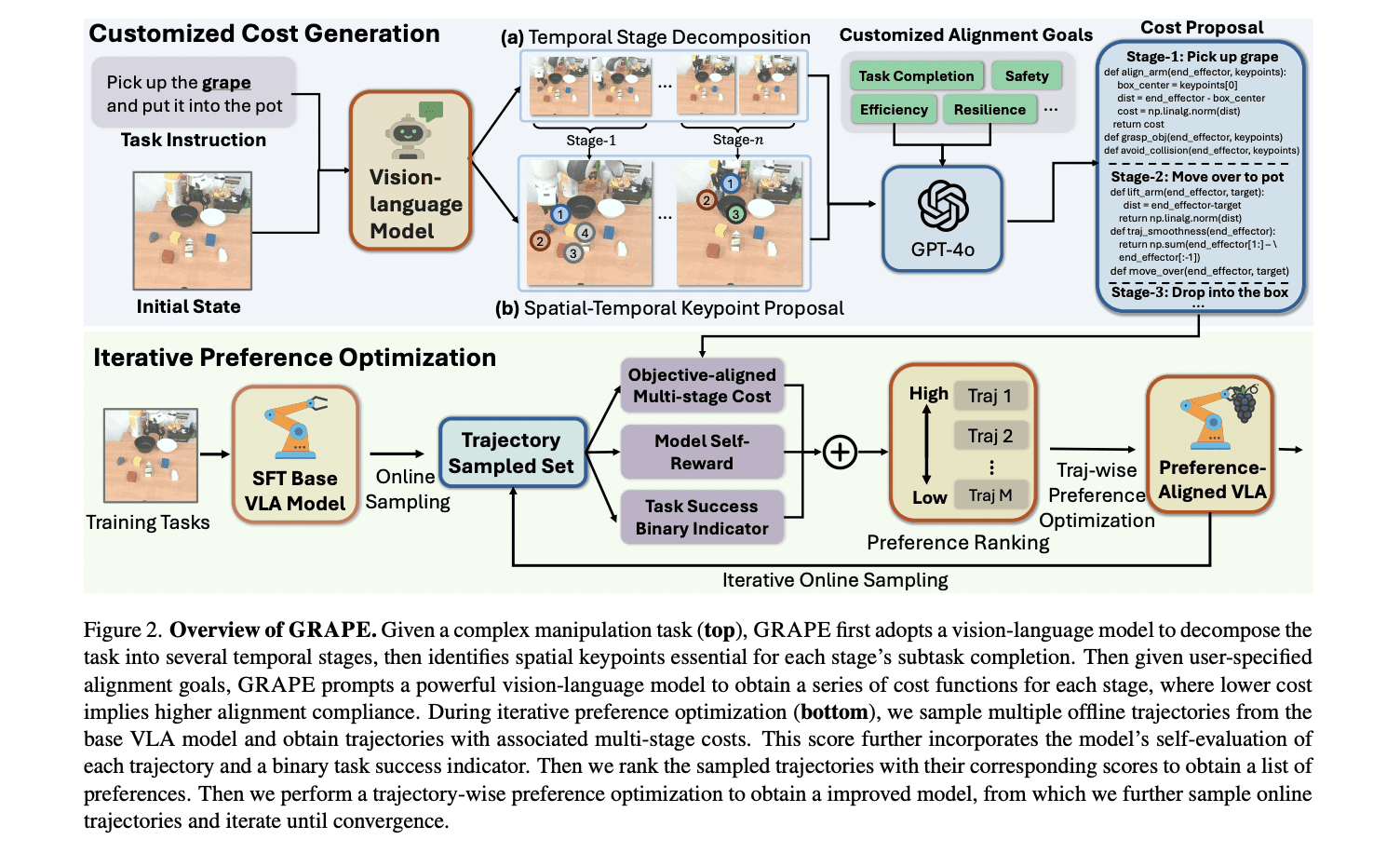
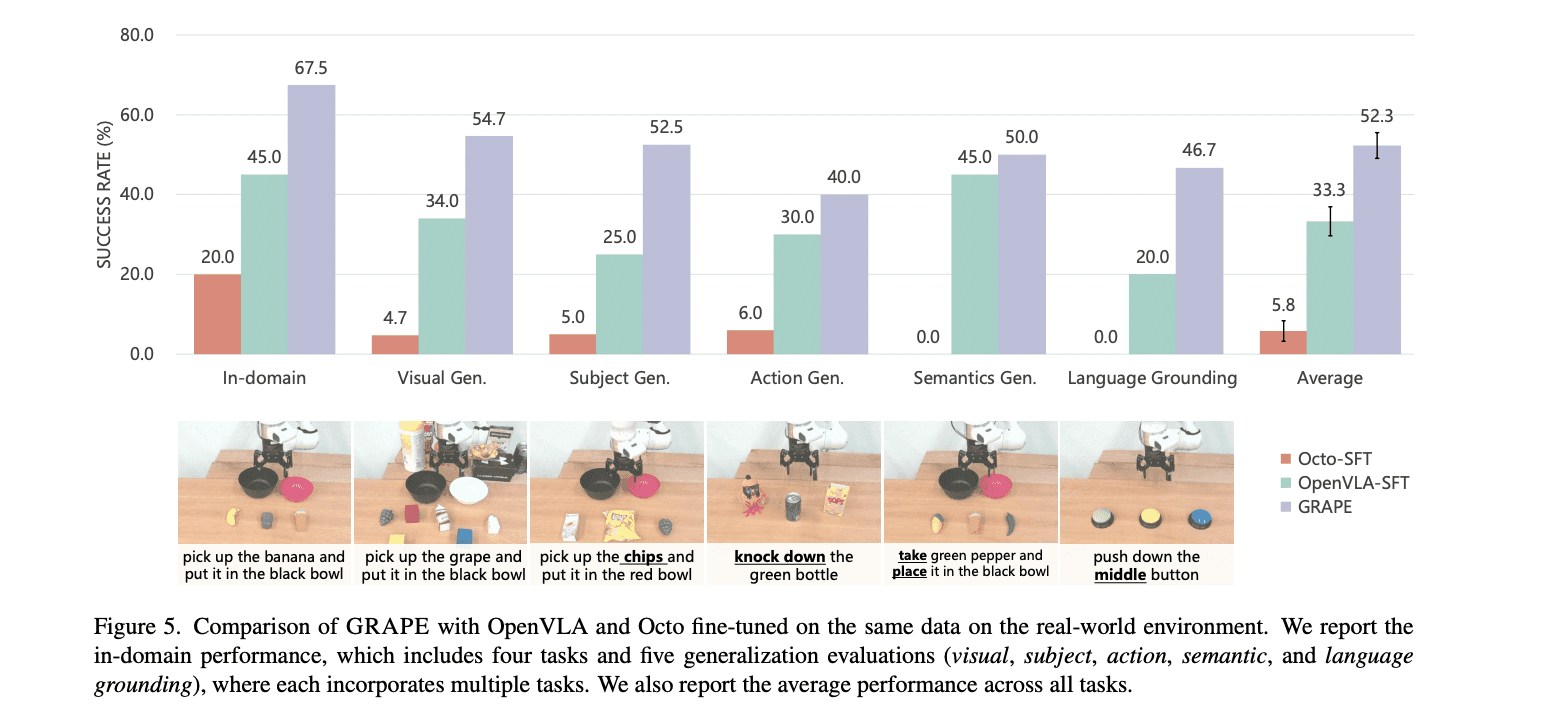
The research team carried out extensive evaluations of GRAPE in both simulated and real-world robotic environments to assess its performance and generalizability. In simulation environments such as Simpler-Env and LIBERO, GRAPE outperformed existing models like Octo-SFT and OpenVLA-SFT by substantial margins. In Simpler-Env, GRAPE improved performance by an average of 24.48% and 13.57%, respectively, across various generalization factors, including subject, physical, and semantic domains.
Real-world testing further confirmed GRAPE’s effectiveness, with the model demonstrating remarkable adaptability across different task scenarios. In in-domain tasks, GRAPE achieved a 67.5% success rate, marking a significant 22.5% improvement over OpenVLA-SFT and far surpassing Octo-SFT. Notably, GRAPE excelled in more challenging generalization tasks, delivering superior performance across visual, action, and language grounding scenarios, with a total average success rate of 52.3% — a 19% increase over existing models.
This research presents GRAPE as a groundbreaking solution to the key challenges facing VLA models, especially their limited generalizability and adaptability in manipulation tasks. Through its novel trajectory-level policy alignment approach, GRAPE excels at learning from both successful and unsuccessful trial sequences. The method provides exceptional flexibility in aligning robotic policies with a range of objectives, including safety, efficiency, and task completion, using innovative spatiotemporal constraint mechanisms. Experimental results confirm GRAPE’s significant advancements, demonstrating substantial improvements in performance across both familiar and unseen task environments.
In the field of robot learning, existing models face several significant challenges. One key issue is limited adaptability to unseen tasks. Traditional models often rely on supervised learning methods like behavior cloning, where robots are trained on a fixed set of demonstration data. While this approach works well for tasks similar to those in the training set, it struggles with generalizing to novel situations or tasks not covered during training.
Another major obstacle is the dependency on expert demonstrations. For robots to perform well, they often need a large volume of high-quality demonstrations. These demonstrations may be costly or impractical to obtain, especially in complex or dynamic environments. Without diverse, expert-level data, the model may fail to learn generalizable policies, limiting its real-world effectiveness.
Moreover, bias due to distribution shifts presents a significant challenge. Models trained on data collected in controlled environments may perform poorly when deployed in real-world settings, where conditions such as lighting, terrain, and object placement vary. This mismatch between training and real-world scenarios can lead to substantial performance degradation.
Addressing these challenges requires more robust approaches, such as combining reinforcement learning with diverse demonstration datasets, or developing methods that allow for better exploration and adaptation to new tasks.
What is GRAPE?
GRAPE (Generalizing Robot Policy via Preference Alignment) is an innovative algorithm designed to enhance the performance and generalizability of vision-language-action (VLA) models in robotics. While traditional VLA models often struggle with tasks involving unseen environments due to their reliance on behavior cloning from expert demonstrations, GRAPE overcomes these limitations by improving the model's ability to generalize across various tasks.
Unlike standard approaches that focus primarily on successful trial rollouts, GRAPE aligns VLA models at the trajectory level, taking into account both success and failure scenarios. This process enables the model to learn from a broader set of experiences, increasing its adaptability to diverse tasks, whether it be safety, efficiency, or task completion.
Additionally, GRAPE divides complex tasks into independent stages and uses a large vision-language model to propose customizable spatiotemporal constraints. These constraints allow for preference modeling that aligns with specific objectives, which can vary based on the needs of the task at hand. This customization ensures that GRAPE can be fine-tuned to address a variety of goals, making it more versatile than previous methods.
The performance improvements are significant: GRAPE shows a 51.79% increase in success rates for in-domain tasks and a 60.36% increase for unseen tasks. It also improves safety and efficiency, with a 44.31% reduction in collision rates and an 11.15% decrease in rollout step-length.
GRAPE (Generalizing Robot Policy via Preference Alignment) is a plug-and-play algorithm designed to address challenges in the generalization of vision-language-action (VLA) models for robot policies. One of the key principles behind GRAPE is aligning VLAs at the trajectory level using reinforcement learning (RL) objectives. This process enhances the model’s decision-making abilities beyond simple behavior cloning, which typically relies on successful rollout data.
Another core principle of GRAPE is its ability to model rewards from both successful and failed trials, helping the model generalize better across a wider range of tasks. By incorporating failures, it improves robustness and adaptability.
Additionally, GRAPE deconstructs complex manipulation tasks into manageable stages and incorporates customizable spatiotemporal constraints based on keypoints suggested by a large vision-language model. These constraints are flexible and can be adjusted to align with specific goals, such as task efficiency, safety, or success. Through these mechanisms, GRAPE offers a versatile and efficient way to align robotic policies with diverse and customized objectives.
GRAPE (Generalizing Robot Policy via Preference Alignment) represents a significant contribution to the field of robot learning and artificial intelligence, particularly in how robots can autonomously generalize tasks across diverse environments. This approach leverages the power of Vision-Language-Action Models (VLAs), which integrate computer vision, language understanding, and robotic control actions into a unified framework. By combining these elements, GRAPE enables robots to adapt their learned behaviors to new, unseen scenarios without needing extensive retraining. This is accomplished through the use of human preference alignment, where robots optimize their actions based on ranked trajectories, balancing performance with human feedback.
Within the broader context of AI and robot learning, GRAPE builds on key trends such as the rise of vision-language models that understand both visual inputs (images) and textual instructions, crucial for robotic manipulation and interaction tasks. This method allows robots to be trained on large, diverse datasets and then fine-tuned to specific tasks, enhancing their ability to generalize across different robots or settings. It also highlights the ongoing evolution towards more flexible, scalable, and general-purpose robotic systems, moving away from task-specific robots to systems that can operate across various domains. Thus, GRAPE's integration of preference learning and VLA offers a pathway for robots to not only improve task performance but also align more closely with human-defined objectives, making them more intuitive and safer to work alongside in real-world applications.
The Need for Generalized Robot Policies
Transferring robot policies across various tasks and environments poses several significant challenges that affect the scalability and generalization of robotic systems.
Environment Variability: One of the primary challenges arises from differences in environments where robots must operate. These environments often vary in terms of geometry, object properties, lighting, and physical conditions. This variability makes it difficult for robots to directly transfer learned behaviors without adjustment. For instance, a robot trained to navigate one type of terrain may struggle to adapt to a different surface, such as sand or snow, due to differences in friction and other surface dynamics. This is often referred to as domain shift, where the robot's prior knowledge no longer aligns with the new environment.
Action Space Alignment: Robots often work with diverse action spaces, depending on their design and hardware capabilities. For example, a robot with a highly articulated arm may have a different set of motor controls and kinematics than a simpler mobile robot. Aligning action spaces when transferring policies between robots or tasks is critical. Techniques like shared inverse kinematics solvers and modularized control stacks help address these disparities but may not fully eliminate the discrepancies that arise from variations in robot hardware and motor controls.
Task Transfer and Generalization: Even when environmental factors are similar, transferring policies between different tasks can be complex. For example, a robot trained to sort objects by size may struggle to adapt to a new task, such as sorting by color, without retraining on task-specific data. This issue highlights the need for robust task representations and learning algorithms that can generalize across different tasks. However, the complexity of these tasks—ranging from simple sorting to more intricate manipulation or decision-making tasks—makes it difficult to maintain consistent performance across the board.
Negative Transfer: One of the risks of transfer learning in robotics is negative transfer, where transferring knowledge from one task or environment actually worsens performance. This can occur if the transferred policy is incompatible with the new scenario, causing the robot to perform poorly. For example, a robot trained to perform tasks in a highly structured environment may fail when placed in an unstructured one, as the prior training data does not provide the necessary flexibility.
Learning Efficiency and Computation: The computational cost of learning across multiple environments and tasks can be prohibitively high. This is especially true when robots need to continuously update and optimize their policies in real-time. Strategies like pretraining using shared representations or fine-tuning to account for specific robot characteristics can help alleviate some of these costs, but they still represent a significant barrier to efficient learning.
One of the key challenges in robotics today lies in the difficulty of generalizing robot policies effectively across different environments and tasks. Current algorithms for policy learning, such as reinforcement learning and imitation learning, face significant limitations when it comes to transferring learned behaviors from one domain to another. These methods often struggle with domain shifts, where slight changes in the environment—such as new object placements, different lighting conditions, or unfamiliar terrains—can cause the robot's performance to degrade drastically.
This problem is exacerbated in real-world scenarios, where environments are not controlled or predictable, and the robot must adapt to new, unseen circumstances. For example, while simulation-based training can offer a controlled environment, the gap between simulated and real-world environments remains large. Algorithms trained in simulations often fail when deployed in the real world due to differences in physical dynamics and visual information, leading to poor generalization.
Moreover, many traditional approaches to handling domain shifts, such as domain randomization or fine-tuning models on a variety of training data, require vast amounts of data and computational resources. These techniques also tend to be heavily dependent on the specific domain of application and may not generalize well to completely new situations. The need for large, diverse datasets for training robots to perform well in varied environments remains a substantial challenge.
Despite advancements, these limitations hinder the robustness and adaptability of robots in dynamic, real-world tasks. To overcome these challenges, new approaches are being developed that focus on improving the generalization capabilities of learned policies by addressing domain shift more effectively.
Preference alignment plays a crucial role in overcoming challenges in robotic policy generalization. One of the primary issues faced in reinforcement learning (RL) for robotics is the design of reward functions that accurately reflect human values and preferences. Traditional methods often struggle to align the agent's behavior with complex human preferences, leading to suboptimal or unintended actions. Preference alignment helps bridge this gap by directly incorporating human preferences into the learning process, ensuring that the agent's behavior aligns with human goals.
In the context of algorithms like GRAPE, preference alignment enables more efficient policy learning by leveraging human feedback. This approach allows robots to learn tasks without requiring an extensive set of pre-defined rewards, making it particularly useful in dynamic or poorly understood environments. By aligning robot actions with human preferences, the robot can better navigate the complexities of real-world scenarios, where rewards might be noisy or ambiguous.
Furthermore, preference alignment techniques such as Active Preference Learning and Preference Optimal Transport (POT) enhance the robot's ability to generalize across tasks. Active Preference Learning involves an iterative process where the robot asks humans for feedback on uncertain actions, refining its behavior over time. This reduces the risk of misalignments between human intent and robotic actions. Similarly, the use of Optimal Transport in POT allows for the transfer of preference labels from one task to another, effectively overcoming task-specific reward design limitations.
These advancements also address the challenge of reward uncertainty. By modeling reward functions as distributions and incorporating uncertainty into the learning process, preference alignment techniques help the robot handle noisy or ambiguous feedback more effectively. This is especially valuable in real-world applications, where perfect information is often unavailable.
How GRAPE Works
GRAPE (Gradient Ascent Pulse Engineering) is an advanced algorithm used for optimizing the control pulses that govern a system's evolution, aiming to bring it as close as possible to a desired target state. This algorithm is often applied in quantum computing and robotics, where precise control over a system's behavior is crucial. Below is an overview of how the GRAPE algorithm works without involving math-heavy details:
Initial Setup: The process begins by defining an initial state of the system and the target state you want to achieve. This could involve preparing a quantum system in a specific state or designing a robot’s policy to complete a task.
Piecewise Control: The evolution of the system is broken into discrete time intervals. During each time interval (or timeslot), the control pulse (e.g., field strength, robot action) remains constant. The length of these intervals and the number of intervals are key parameters in the setup.
Time Evolution: For each timeslot, the system's behavior is calculated based on its current state and the applied control pulse. The total behavior of the system over time is obtained by combining the individual time intervals.
Measuring Fidelity: After the system has evolved based on the initial control pulses, the "fidelity" or how close the system's state is to the target state is measured. Fidelity is used to evaluate the performance of the control pulses; the higher the fidelity, the better the system has approximated the desired state.
Optimization Using Gradient Ascent: GRAPE uses a technique called gradient ascent, where the control parameters are adjusted iteratively based on the computed fidelity. In each iteration, the control parameters (pulse amplitudes) are updated in the direction that improves the fidelity, effectively “climbing” the gradient to achieve better results.
Convergence: This iterative process continues until the system reaches a state where the fidelity is sufficiently high or another stopping criterion (such as a maximum number of iterations) is met. The goal is to find the optimal set of control pulses that minimizes the difference between the system's actual state and the desired target state.
Challenges: One of the main challenges with GRAPE is the computational complexity, particularly for large systems like multi-qubit quantum systems or complex robotic tasks. To address this, optimizations such as iterative GRAPE (iGRAPE) or approximations like quasi-Newton methods are used.
GRAPE's ability to optimize control pulses makes it highly valuable for tasks like quantum state preparation, gate synthesis, and even for generalizing robot behaviors across various environments.
Steepest Descent and Newton's Methods
To address some of the challenges posed by gradient ascent, GRAPE employs variants of steepest descent and second-order methods such as the Newton-Raphson method or quasi-Newton methods like BFGS. The Newton-Raphson method accelerates convergence by approximating the system's landscape as a parabola, which reduces the number of iterations required. However, calculating second-order derivatives can be computationally expensive. Thus, methods like BFGS (Broyden–Fletcher–Goldfarb–Shanno) provide approximations of the Hessian matrix (second-order derivatives) to improve efficiency without the heavy computational cost.
Preference alignment
The role of preference alignment in GRAPE (Guided-Reinforced Vision-Language-Action Preference Optimization) is to ensure that the robot’s actions are aligned with user-defined preferences across various tasks. GRAPE enhances generalization by considering not just the successful demonstrations but also learning from failure cases, providing a more robust model for real-world robot interactions. The key component here is aligning Vision-Language-Action (VLA) models with user preferences on a trajectory level.
Preference alignment works by guiding the model through customized spatiotemporal constraints, using keypoints from a large vision-language model. These constraints can be adjusted to prioritize specific objectives, such as safety, efficiency, or task success. For instance, the model may be trained to minimize collision rates or ensure task completion within a given time frame. This preference alignment helps the robot adapt its behavior to meet user expectations, regardless of task complexity or environment (simulated or real-world).
Through GRAPE’s framework, preference alignment significantly boosts the robot's ability to handle unseen tasks, improving its adaptability. By incorporating feedback from both successful and unsuccessful trials, the robot learns not just from ideal outcomes but also from the nuances of failure, thereby improving its decision-making and task execution in a diverse range of environments.
The GRAPE algorithm, or Generalizing Robot Policy via Preference Alignment, enhances the performance of vision-language-action (VLA) models by improving their adaptability and generalization across diverse robotic tasks. The key innovations and algorithms behind GRAPE revolve around a few core strategies designed to optimize task performance while aligning with various objectives like safety, efficiency, and task success.
Trajectory-Level Alignment via Reinforcement Learning: GRAPE aligns robot policies at the trajectory level, moving beyond traditional behavior cloning. This method applies reinforcement learning (RL) to reward the model based on the entire trajectory, rather than just successful outcomes. By modeling both successes and failures, GRAPE reduces the distribution bias that often hinders generalization, making it possible for the model to better handle unseen tasks.
Implicit Modeling of Reward from Failure: Unlike models that focus solely on success, GRAPE integrates both successful and failed trial data into its training process. This allows the algorithm to learn more robust, generalizable policies by recognizing not only what worked but also why some actions failed, offering more nuanced feedback for improvement.
Customized Spatiotemporal Constraints: A unique feature of GRAPE is its use of spatiotemporal constraints proposed by a large vision-language model, which helps break down complex tasks into independent stages. These constraints are flexible, allowing the model to align with different goals like safety or efficiency. This capability is crucial for tasks where precision and adaptability are necessary.
Scalable Preference Synthesis Algorithm: GRAPE employs a preference synthesis algorithm that ranks trajectories based on how well they align with predefined preferences. This customization enables GRAPE to be tailored to specific objectives, whether it's optimizing for safer actions, more efficient movements, or higher task completion rates.
These innovations significantly improve the adaptability of VLA models in real-world and simulated robotic environments. For instance, GRAPE has been shown to increase success rates in both in-domain and unseen tasks by over 50%, while also achieving substantial reductions in collision rates and task completion time. The combination of trajectory-level RL alignment, reward modeling from failures, and scalable preference modeling makes GRAPE a powerful tool for generalizing robotic tasks across diverse scenarios.
Key Features of GRAPE
The plug-and-play (PnP) nature of the GRAPE algorithm allows for significant flexibility and efficiency in its deployment, as it removes the need for extensive retraining when adapting to new tasks. This is a major advantage for applications where retraining large models can be computationally expensive and time-consuming. Instead of retraining the entire system for each new problem or dataset, PnP allows for the straightforward integration of new components without the need for major adjustments to the underlying model structure.
The plug-and-play framework works by leveraging pre-existing components, such as denoising algorithms or optimization methods, which can be easily swapped in or out depending on the task. This approach allows the system to quickly adjust to different tasks while maintaining high performance. Additionally, by using pre-trained models or established algorithms, PnP reduces the need for continuous model fine-tuning, making it highly adaptable to diverse problem domains.
This approach is particularly useful in machine learning applications like image reconstruction or large language models (LLMs), where rapid adaptation is essential but retraining on every new dataset is impractical. By using PnP, these models can quickly process new inputs without the time and resource investment typically associated with retraining. This makes it an attractive solution for real-time processing or applications that require flexibility with minimal overhead.
Flexibility in applying AI to a wide range of tasks is a key feature that enhances its practicality in real-world scenarios. Recent advancements, such as the Pi_0 model used in robotics, show how AI can be trained to handle diverse tasks, from laundry folding to table cleaning, using a vision-language-action flow architecture. This model, designed with dexterous robots in mind, is capable of generalizing across different tasks and adapting to new ones by fine-tuning. Its ability to learn from vast datasets and apply instructions via natural language allows it to tackle a variety of challenges with minimal additional training.
Such flexibility is valuable beyond robotics, allowing AI to perform well in other domains, like data analysis, content creation, and problem-solving. This adaptability not only makes AI tools more powerful but also reduces the barriers to entry for different industries, making advanced automation accessible to a broader range of users and applications.
GRAPE (Generalized Robot Policies with Preference Alignment) is designed to improve the efficiency of learning and decision-making in complex robotic systems. Its core innovation lies in the alignment of robots' decision-making processes with human preferences, allowing for more intuitive, effective, and safer interactions. This is achieved by leveraging a combination of advanced learning algorithms and reinforcement learning techniques that ensure that robots not only learn tasks faster but also make decisions that align with human values and preferences.
In the context of improving learning efficiency, GRAPE uses techniques such as preference-based reinforcement learning and trajectory optimization to minimize the time and data required to train robots. This allows robots to generalize learned policies across various environments and tasks, reducing the need for extensive retraining. By introducing human preferences into the learning loop, GRAPE also facilitates quicker adaptation to real-world situations, where human judgments may be necessary to refine the actions of the robot.
For decision-making, GRAPE enhances robot autonomy by making its policy selection process more transparent and adaptable. By aligning robot actions with human goals, GRAPE ensures that robots can make decisions that not only optimize for task success but also ensure that these decisions are ethical, safe, and reliable. These improvements in learning and decision-making lead to faster, more efficient robot operation in dynamic environments.
Advantages Over Traditional Methods
GRAPE (Generalizing Robot Policy via Preference Alignment) presents a significant advancement over traditional robot learning algorithms by addressing some common challenges in robot learning and generalization. Unlike conventional methods that rely heavily on behavior cloning from expert demonstrations (often restricted to specific successful rollouts), GRAPE integrates a more generalized framework that enhances adaptability across diverse tasks.
Traditional learning algorithms, especially those in vision-language-action (VLA) models, tend to struggle with generalizing to new, unseen tasks due to overfitting to specific expert demonstrations. They also fail to model failure cases effectively, leading to poor generalization in real-world applications. GRAPE overcomes this by aligning VLAs on a trajectory level through reinforcement learning, allowing robots to make global decisions rather than just mimic expert actions. This approach ensures that the model learns from both successful and failed trials, improving its robustness and adaptability.
Furthermore, GRAPE introduces scalable preference modeling, allowing the robot to align its actions with specific objectives such as safety, efficiency, or task success. This ability to prioritize different aspects of a task, such as reducing collision rates or optimizing task efficiency, is a key differentiator from conventional algorithms. It also breaks down complex tasks into independent stages, guided by spatiotemporal constraints that are customized according to the task's needs.
In practical tests, GRAPE significantly outperformed traditional methods, increasing success rates on both in-domain and unseen tasks by over 50%, while also reducing errors and optimizing task completion times. This ability to generalize across tasks and align with multiple objectives makes GRAPE a versatile and powerful tool for robotic learning.
For more information on GRAPE and its experimental results, you can explore the paper and project details here.
In recent advancements in vision-language models (VLMs), there is a strong focus on enabling models to generalize across various tasks with minimal adjustments. This capability is especially powerful for addressing domain adaptation and generalization. Models like CLIP (Contrastive Language-Image Pretraining) have demonstrated the ability to align visual and textual data in a shared space, leading to impressive zero-shot generalization across tasks without the need for task-specific retraining. For example, prompt learning with models such as CoOp and StyLIP enhances task performance by adjusting the input prompts, offering flexible and efficient adaptation to new data distributions without requiring extensive retraining.
These models leverage domain-agnostic features and can perform well in scenarios like visual question answering (VQA) and remote sensing classification, where domain shifts are a challenge. The beauty of such methods is that they can transfer knowledge effectively across domains, often reducing the need for large, task-specific datasets. Furthermore, by adjusting prompt structures, these models can improve generalization across both familiar and unseen classes, expanding their ability to handle diverse tasks with minimal customization.
This flexibility and efficiency are key in deploying AI across varied real-world applications, particularly when data is scarce or difficult to label. The trend points to models that don’t just specialize in one task but are adaptable and scalable across numerous use cases, with minimal additional data or supervision needed.
Recent advancements in machine learning algorithms, particularly with improved models like YOLOv4 and its variants, have significantly enhanced the learning speed, accuracy, and robustness of applications in various fields, including agriculture and industrial tasks. One such improvement was seen in the application of YOLOv4 for grape maturity detection, where modifications such as the integration of Mobilenetv3 as the backbone and deep separable convolution techniques helped optimize the model's speed without compromising its accuracy. The model's performance, with an average accuracy of 93.52% and a fast detection time of 10.82 ms, demonstrates how these enhancements make it not only faster but also more reliable, especially in complex environments like orchards. The reduced parameters and better real-time performance also contribute to its robustness in variable conditions.
In similar contexts, using attention mechanisms like SENet has further refined models' ability to focus on crucial features, thus improving their overall accuracy and robustness. For example, in automated grape harvesting, the combination of maturity detection and spatial positioning through binocular stereo vision has delivered precise positioning with minimal error (mean error of 27 mm), which would be critical for real-world applications that require high reliability in non-ideal conditions.
Incorporating such improvements helps not only in faster processing but also enhances robustness across different types of input data, thus creating a more efficient, accurate, and scalable solution for real-time applications.
Use Cases and Applications
GRAPE (Geometric Robotic Application for Perception and Estimation) algorithms can be applied in several advanced robotics and AI systems where precision and real-time decision-making are crucial. A key area of application is in agricultural robotics, particularly in grape harvesting. These algorithms are used to detect, segment, and precisely locate grape bunches and stems, enabling robotic systems to harvest fruit autonomously. For example, in grape harvesting, deep learning-based perception systems, utilizing algorithms like Mask R-CNN, are used to process images, estimate the pose of grape bunches, and direct robotic arms to perform the harvesting task. With a high degree of accuracy and efficiency in real-world tests, these systems can support robotic platforms, improving the harvesting process by overcoming labor shortages.
Another prominent application of GRAPE algorithms is in autonomous vehicles. In this context, they are used for pose estimation and 3D reconstruction, critical for navigation and obstacle detection. GRAPE algorithms process visual and sensor data to create accurate 3D models of the environment, helping autonomous systems make decisions based on their spatial awareness.
Additionally, GRAPE can be applied in AI systems where environment modeling, pathfinding, and decision-making are integral. The algorithm's ability to work with multiple data sources—such as visual cues, sensor data, and 3D point clouds—makes it suitable for complex tasks in dynamic environments like robotics, AI-powered navigation, and autonomous operations. This adaptability enables GRAPE to be integrated into systems where real-time processing of vast amounts of sensory data is necessary.
The GRAPE algorithm is being applied to various fields where robots and machine learning models can improve performance, enhance efficiency, and handle diverse tasks with greater precision. Some key industries that can benefit from GRAPE's implementation include:
Agriculture: GRAPE has shown potential in autonomous agricultural tasks, such as precision harvesting. For instance, in grape harvesting, robots using GRAPE can generalize tasks like pruning, defoliation, and fruit picking, all of which are essential to sustainable farming practices. The GRAPE algorithm helps robots better understand their environment and adapt to various conditions, optimizing their operational effectiveness. This can significantly address labor shortages in agriculture and improve crop management.
Robotics and Automation: In broader robotics, particularly those employing Vision-Language-Action (VLA) models, GRAPE has been demonstrated to increase the generalization of robot policies. By aligning tasks with user preferences and breaking them down into manageable stages, it improves robot performance across various domains, including manipulation tasks. The flexibility of GRAPE in adapting to safety, efficiency, and task completion makes it ideal for applications in manufacturing, service robots, and industrial automation.
Healthcare: Robotics in healthcare is an emerging field, with tasks like surgery assistance, rehabilitation, and patient monitoring benefiting from GRAPE's generalization capabilities. By aligning robotic actions with specific health outcomes, GRAPE could enhance robot adaptability in real-world, unpredictable medical environments.
Transportation and Logistics: Autonomous vehicles and drones can benefit from GRAPE's ability to adjust to different environments. By improving decision-making and adapting strategies for various transport and delivery scenarios, it could optimize logistics operations, route planning, and safety features for autonomous vehicles.
Experimental Results
GRAPE (Generalizing Robot Policy via Preference Alignment) is designed to address the common issue of poor generalizability in vision-language-action (VLA) models used for robotics tasks. The approach enhances VLA models by aligning them at the trajectory level and incorporating reward signals not only from successful trials but also from failure cases. This method significantly improves the adaptability of robots to diverse manipulation objectives, including safety, efficiency, and task completion.
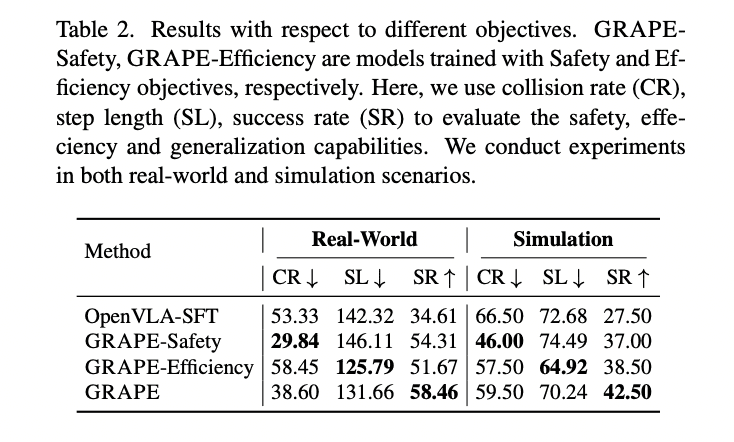
Experimental results demonstrate that GRAPE boosts the performance of state-of-the-art VLA models. Specifically, it improved success rates by 51.79% for tasks within the same domain and 60.36% for unseen tasks. Moreover, the method contributed to substantial reductions in collision rates by 44.31% and reduced the length of rollout steps by 11.15%. These improvements show that GRAPE not only enhances task success but also allows fine-tuning according to different goals, such as increasing safety or optimizing efficiency.
For further details, you can explore the full research paper on GRAPE's implementation and results here.
Performance Comparisons and Benchmarking of GRAPE
The GRAPE algorithm demonstrates substantial improvements in the field of robotic policy generalization, particularly when evaluated against existing benchmarks. Traditional vision-language-action (VLA) models, while effective in specific domains, suffer from limited adaptability when encountering novel tasks or operational constraints. GRAPE addresses these limitations by aligning robot policies with preference-driven trajectories, which enhances its ability to handle diverse and previously unseen tasks.
Key Performance Metrics:
Success Rates: GRAPE outperforms state-of-the-art models by achieving a 51.79% improvement in in-domain tasks and a 60.36% improvement in unseen manipulation tasks. This stark increase highlights GRAPE's capacity for generalizing across various environments.
Safety and Efficiency: The algorithm achieves a 44.31% reduction in collision rates, showcasing its prioritization of safety. Additionally, it reduces rollout step lengths by 11.15%, indicating an enhancement in task efficiency.
Robustness: By incorporating both successful and failed trials into its reward modeling process, GRAPE effectively mitigates the distribution bias present in earlier systems, ensuring robust performance across different scenarios.
Comparison with Benchmarks: GRAPE’s performance has been validated against leading benchmarks like RMBench, which evaluates deep reinforcement learning techniques for robotic manipulation tasks. While traditional methods often require extensive expert demonstrations, GRAPE’s reliance on preference alignment and dynamic spatiotemporal constraints makes it uniquely adaptable, allowing it to exceed the success rates and adaptability scores of many competing approaches.
The algorithm's ability to dynamically align policies to objectives such as task efficiency, safety, and success makes it a strong candidate for real-world deployments where robots need to operate autonomously in diverse and unpredictable environments.
Future Directions
To discuss potential future enhancements for the GRAPE (Gradient Ascent Pulse Engineering) algorithm, it's essential to focus on improving its computational efficiency, adaptability, and scalability, particularly for practical quantum systems:
Integration with Machine Learning: Incorporating reinforcement learning or neural networks could refine the initial guess for control pulses, potentially accelerating convergence and enhancing fidelity for complex quantum operations.
Parallelized Computation: As GRAPE relies heavily on iterative forward and backward propagations, optimizing these computations using parallel processing or GPU acceleration could significantly reduce runtime, making it more suitable for large quantum systems.
Handling Noise and Decoherence: Enhancing GRAPE to better account for environmental noise and system decoherence is critical for real-world applications. This could involve incorporating more sophisticated models of non-Hermitian operators or Lindblad dynamics.
Improved Fidelity Metrics: The definition of fidelity and its gradient could be adapted to consider constraints specific to certain quantum technologies, such as energy limitations or robustness against hardware imperfections.
Extensions to Open Quantum Systems: Tailoring GRAPE for open quantum systems by incorporating Lindblad operators more effectively would expand its usability in practical quantum experiments.
Hybrid Algorithms: Combining GRAPE with other quantum control techniques, such as Krotov's method, could leverage the strengths of both approaches to optimize specific tasks more effectively.
These improvements aim to address both theoretical and practical challenges, enabling GRAPE to handle increasingly complex quantum systems while maintaining high performance. For further technical insights, you can refer to Michael Goerz's introduction to the GRAPE algorithm .
GRAPE's upcoming projects and integrations are set to enhance its position as a robust blockchain ecosystem. Key developments include:
Public Testnet and Mainnet Launches: The GRAPE team is preparing to release its public testnet, enabling users to experiment with its functionalities. Following this, the mainnet is expected to launch, which will include enhanced features like sharding for scalability and a decentralized storage system.
AI-Powered Enhancements: Leveraging AI-driven coding tools, GRAPE is aiming to simplify the creation of smart contracts and decentralized applications. This aligns with broader trends where AI integration into APIs and platforms is redefining data usage and management in apps.
Future-Oriented Integrations: GRAPE plans to expand into areas such as biometric authentication, decentralized exchanges (DEX), and interoperable NFT platforms, paving the way for secure, scalable, and accessible blockchain applications.
These developments are part of GRAPE’s ambition to make blockchain more user-friendly and to integrate seamlessly with AI-driven innovations for enhanced utility across industries.
Conclusion
The algorithms behind GRAPE are tailored to enhance decentralized networks by integrating token-based membership solutions and facilitating broader applications within the blockchain space. Key features include:
Tokenized Access Control: GRAPE leverages token-based authentication systems like Grape Access to provide dynamic, balance-based memberships. This allows users to gain access to communities and services based on their token holdings, ensuring secure and automated permission management.
Smart Contract Efficiency: GRAPE employs audited smart contracts to facilitate transactions and interactions. These contracts automate rules and ensure integrity, eliminating the need for intermediaries and increasing system reliability.
Integration with Solana: Built on the Solana blockchain, GRAPE takes advantage of its high-speed and low-cost infrastructure to support efficient peer-to-peer trading, lending, and borrowing. This platform ensures scalability while reducing transaction costs.
Decentralized Social Networking: GRAPE uses its algorithms to power decentralized websites and applications, supporting community-driven initiatives in sectors such as gaming, music, and supply chains.
Enhanced Data Security: Through advanced encryption and continuous monitoring, GRAPE secures user data and assets against cyber threats, bolstered by regular updates and system audits.
The Impact of GRAPE on Generalized Robot Policies
GRAPE (Generalizing Robot Policy via Preference Alignment) is a transformative approach in robotics, addressing critical limitations of vision-language-action (VLA) models, particularly in their adaptability to diverse and unseen tasks. Traditional VLA models often struggle due to their dependence on behavior cloning from expert demonstrations, which introduces distribution bias and limits generalizability. GRAPE innovates by redefining how robots align their policies with varying task objectives like safety, efficiency, and task success.
Advancing Generalizability
GRAPE enhances the adaptability of robots by incorporating both successful and failure trials into its reward modeling. Unlike conventional methods that focus solely on successful outcomes, this dual-sided learning approach allows GRAPE to generalize more effectively across diverse tasks. For instance, the algorithm dissects complex manipulation tasks into manageable stages and applies spatiotemporal constraints derived from vision-language models. This modular approach ensures that each stage of a task is executed with precision, regardless of its complexity.
Boosting Performance Metrics
The experimental results underline GRAPE's potential. It significantly improves the performance of state-of-the-art VLA models, achieving a 51.79% higher success rate for in-domain tasks and a 60.36% increase for unseen manipulation tasks. Moreover, when aligned with specific objectives, GRAPE showcases remarkable flexibility. For example, safety-oriented configurations reduce collision rates by 44.31%, while efficiency-driven setups decrease rollout step-lengths by 11.15%. These metrics not only demonstrate GRAPE's capability to align with diverse priorities but also validate its practical applicability in both simulated and real-world environments.
Industry Implications
GRAPE’s ability to tailor robot behaviors to varying goals—whether it be minimizing energy consumption or maximizing operational safety—positions it as a critical tool in industrial automation, healthcare robotics, and beyond. Its plug-and-play nature simplifies integration into existing systems, making it an attractive choice for industries aiming to optimize robotic workflows while maintaining adaptability.
For a detailed overview of GRAPE and its capabilities, you can refer to the official project site at GRAPE-VLA.
Press contact
Timon Harz
oneboardhq@outlook.com
Other posts





Company
About
Blog
Careers
Press
Legal
Privacy
Terms
Security