Timon Harz
December 19, 2024
Introducing Moxin LLM 7B: The Fully Open-Source Language Model Built with the Model Openness Framework (MOF)
Moxin LLM 7B is a groundbreaking open-source language model designed to accelerate AI innovation. Built with the Model Openness Framework (MOF), it offers unparalleled transparency and flexibility for researchers, developers, and businesses.
The rapid advancements in Large Language Models (LLMs) have revolutionized natural language processing (NLP). While proprietary models like GPT-4 and Claude 3 excel in performance, they often pose challenges such as high costs, restricted access, and opaque methodologies. On the other hand, many so-called open-source models fail to meet true openness standards, withholding critical components like training data, fine-tuning processes, or employing restrictive licenses. These limitations stifle innovation, hinder reproducibility, and complicate adoption across industries. Overcoming these barriers is essential to building trust, fostering collaboration, and driving progress in the AI ecosystem.
Introducing Moxin LLM 7B: A Fully Open-Source Solution
To address these challenges, researchers from Northeastern University, Harvard University, Cornell University, Tulane University, University of Washington, Roboraction.ai, Futurewei Technologies, and AIBAO LLC have collaborated to create Moxin LLM 7B. Guided by the Model Openness Framework (MOF), Moxin LLM 7B embodies the principles of transparency and inclusivity.
This fully open-source model offers comprehensive access to its pre-training code, datasets, configurations, and intermediate checkpoints, earning the highest MOF classification: “open science.” Moxin LLM 7B is available in two versions—Base and Chat—and features a 32k token context size alongside innovative technologies like Grouped-Query Attention (GQA) and Sliding Window Attention (SWA). Designed for both NLP and coding applications, it is a powerful tool for researchers, developers, and businesses seeking adaptable, high-performance solutions.
Technical Innovations and Key Features
Building on Mistral’s architecture, Moxin LLM 7B introduces several enhancements:
Expanded Architecture: A 36-block design incorporating GQA for memory efficiency and SWA for effective long-sequence processing.
Optimized Memory Usage: A rolling buffer cache for handling extended contexts in real-world applications.
Advanced Training Process: The model was trained on over 2 trillion tokens using curated datasets like SlimPajama, DCLM-BASELINE, and The Stack, leveraging Colossal-AI’s parallelization techniques.
These advancements provide key benefits:
True Open-Source Customization: Flexibility to adapt and tailor the model across diverse applications.
Exceptional Performance: Strong results in zero-shot and few-shot tasks, demonstrating capabilities in complex reasoning, coding, and multitasking.
Balanced Efficiency: Combines computational efficiency with high output quality for both research and practical use cases.
Performance Highlights
Moxin LLM 7B has been rigorously benchmarked against leading models:
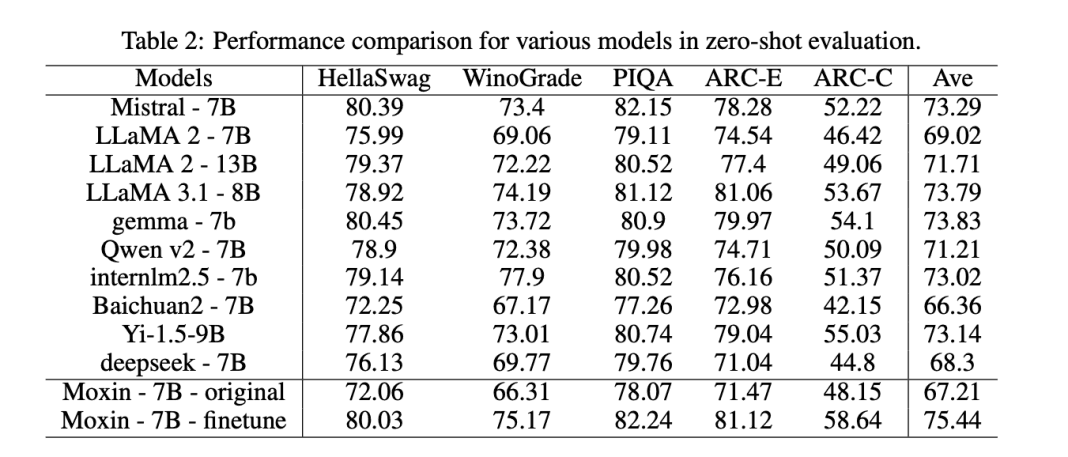
Zero-Shot Evaluation: Outperformed models like LLaMA 2-7B and Gemma-7B on tasks such as the AI2 Reasoning Challenge, HellaSwag, and PIQA. Its fine-tuned version achieved a notable 82.24% accuracy on PIQA, setting new performance standards.
Few-Shot Evaluation: Demonstrated superior reasoning and domain-specific knowledge in tasks such as MTBench, with the Moxin Chat 7B variant rivaling proprietary models in interactive assistant scenarios.
Moxin LLM 7B emerges as a pivotal advancement in the open-source LLM domain. By adhering to the principles of the Model Openness Framework, it tackles key challenges such as transparency, reproducibility, and accessibility—areas where many models fall short. Combining technical excellence, strong performance, and a dedication to openness, Moxin LLM 7B provides a powerful alternative to proprietary systems. As AI's influence expands across industries, models like Moxin LLM 7B pave the way for a future rooted in collaboration, inclusivity, and innovation in natural language processing and beyond.
Moxin LLM 7B represents a significant advancement in the field of natural language processing, embodying the principles of transparency and inclusivity as outlined in the Model Openness Framework (MOF). This fully open-source language model distinguishes itself by providing comprehensive access to its pre-training code, datasets, configurations, and intermediate checkpoints, thereby achieving the highest MOF classification of "open science."
Developed through a collaborative effort involving researchers from institutions such as Northeastern University, Harvard University, Cornell University, Tulane University, University of Washington, Roboraction.ai, Futurewei Technologies, and AIBAO LLC, Moxin LLM 7B is available in two versions: Base and Chat. Both versions are designed to cater to a wide range of applications, from natural language processing tasks to coding-related functions.
One of the standout features of Moxin LLM 7B is its architecture, which includes a 32,000-token context size. This extensive context window enables the model to process and generate longer sequences of text, enhancing its applicability in complex tasks that require understanding and generating extended discourse. Additionally, the model incorporates advanced mechanisms such as grouped-query attention (GQA) and sliding window attention (SWA). GQA improves memory efficiency by reducing the computational load during the attention mechanism, while SWA allows the model to handle long sequences more effectively by segmenting them into manageable windows.
The development of Moxin LLM 7B under the MOF ensures that it adheres to the highest standards of openness and reproducibility. The Model Openness Framework is a ranked classification system that evaluates AI models based on their completeness and openness, incorporating the principles of open science, open source, open data, and open access. By fully complying with MOF, Moxin LLM 7B addresses critical issues of transparency and reproducibility that are often challenges in the AI community.
In summary, Moxin LLM 7B is a robust and accessible language model that exemplifies the ideals of open science. Its development in accordance with the Model Openness Framework ensures that it is a valuable resource for researchers, developers, and businesses seeking flexible and high-performing solutions in the realm of natural language processing and beyond.
Open-source models have become a cornerstone in the evolution of artificial intelligence (AI), playing a pivotal role in enhancing transparency, reproducibility, and innovation within the AI community. By making AI tools and models freely accessible, open-source initiatives democratize technology, allowing a diverse range of individuals and organizations to contribute to and benefit from AI advancements.
Transparency is a fundamental advantage of open-source AI models. When the underlying code and data of AI systems are openly available, it enables developers, researchers, and end-users to scrutinize and understand how these models function. This openness fosters trust, as stakeholders can verify the processes and decisions made by AI systems, ensuring they align with ethical standards and societal values. Moreover, transparent AI models facilitate the identification and mitigation of biases, leading to more fair and equitable outcomes.
In terms of reproducibility, open-source models allow researchers to validate and replicate findings, a cornerstone of scientific inquiry. The ability to reproduce results ensures that AI research is reliable and that models perform as intended across different scenarios and datasets. This reproducibility accelerates the iterative process of model improvement and fosters a collaborative environment where researchers can build upon each other's work without starting from scratch.
Innovation thrives in an open-source ecosystem. When AI models and tools are openly shared, they become the foundation upon which new ideas and applications are built. This collaborative approach leads to the rapid development of novel solutions and technologies, as developers worldwide can adapt and enhance existing models to address specific challenges or explore new domains. Open-source AI also lowers the barriers to entry for startups and smaller organizations, enabling them to compete and contribute to the AI landscape without the need for substantial initial investments.
Furthermore, open-source AI models contribute to **equitable development** by encouraging diverse contributions from various communities. This inclusivity helps address potential biases and ensures that AI technologies are developed with a broader perspective, catering to the needs of different populations and reducing the risk of marginalization.
However, the journey towards fully open-source AI is ongoing. Challenges such as "open washing," where models are labeled as open-source without fully adhering to open-source principles, persist. For instance, some AI models may share only partial components, limiting true transparency and reproducibility. Addressing these challenges requires a concerted effort from the AI community to establish clear definitions and standards for what constitutes open-source AI.
In conclusion, open-source AI models are instrumental in promoting transparency, reproducibility, and innovation within the AI community. By embracing open-source principles, the AI field can continue to advance in a manner that is inclusive, equitable, and aligned with the broader interests of society.
Understanding the Model Openness Framework (MOF)
The Model Openness Framework (MOF) is a comprehensive system designed to evaluate and classify the completeness and openness of machine learning models. Developed by the Generative AI Commons at the LF AI & Data Foundation, MOF assesses various components of the model development lifecycle to determine their availability and the licenses under which they are released.
The primary objective of MOF is to promote transparency, reproducibility, and collaboration in AI research and development. By providing a structured approach to assess model openness, MOF helps prevent "openwashing," a practice where models are falsely presented as open-source without meeting the necessary criteria. This framework guides researchers and developers in releasing all model components under permissive licenses, ensuring that individuals and organizations can adopt these models without restrictions.
MOF identifies 16 critical components that constitute a complete model release. These components encompass various aspects of the model development process, including the availability of training data, model architecture, training code, and evaluation metrics. Each component is evaluated to determine its openness, and models are classified into tiers based on the extent to which they meet these criteria.
To facilitate the practical application of MOF, the Model Openness Tool (MOT) has been developed. MOT presents users with a series of questions corresponding to the 16 MOF criteria, allowing them to assess their models' openness. Based on the responses, MOT generates a score that classifies the model's openness on a scale of 1 to 3. This user-friendly tool aids developers in understanding the openness of their models and provides clarity on permissible uses of the model and its components.
By establishing a standardized framework for evaluating model openness, MOF aims to foster a more open AI ecosystem. It encourages the release of comprehensive menabling the AI community to reproduce results, build upon existing work, and drive innovation. The widespread adoption of MOF is expected to enhance the transparency and usability of AI models, benefiting researchers, developers, and end-users alike.
The Model Openness Framework (MOF) identifies 16 critical components that constitute a truly complete machine learning model release. These components span various stages of the model development lifecycle, ensuring transparency, reproducibility, and usability. Each component is expected to be released under appropriate open licenses, facilitating open science and collaborative advancement in AI.
Model Architecture (III.1): This refers to the detailed design of the model, including its structure, layers, and configuration. Openly sharing the architecture allows others to understand the model's foundational design and adapt it for various applications.
Model Parameters (III.2): These are the weights and biases learned during training. Providing access to the model parameters enables replication of the model's performance and facilitates fine-tuning for specific tasks.
Model Card (III.3): A comprehensive document that outlines the model's intended use, limitations, ethical considerations, and performance metrics. The model card promotes responsible deployment and informs users about appropriate applications.
Training Code (II.1): The scripts and algorithms used to train the model. Releasing the training code ensures that others can reproduce the training process and verify results.
Training Data (II.2): The datasets employed to train the model. Access to training data allows for validation of the model's learning process and assessment of potential biases.
Training Configuration (II.3): Details about the hyperparameters, optimization settings, and other configurations used during training. Sharing this information aids in replicating the training environment accurately.
Inference Code (II.4): The code required to deploy the model for making predictions. Open inference code enables seamless integration of the model into various applications.
Evaluation Code (II.5): Scripts used to assess the model's performance. Providing evaluation code allows others to benchmark the model consistently.
Evaluation Data (II.6): Datasets used to evaluate the model's accuracy and effectiveness. Access to evaluation data ensures transparency in performance reporting.
Supporting Libraries and Tools (II.7): Additional software, libraries, or tools developed during the model's creation. Sharing these resources supports the community in reproducing and extending the model's capabilities.
Research Paper (I.1): A scholarly article detailing the model's development, methodology, and findings. Open access to the research paper disseminates knowledge and encourages academic discourse.
Technical Report (I.2): A document providing in-depth technical details about the model. Releasing the technical report offers deeper insights into the model's design and implementation.
Datasheets for Datasets (I.3): Documentation that describes the datasets used, including their composition, collection methods, and intended use. Datasheets promote transparency and ethical use of data.
Model Checkpoints (I.4): Intermediate saved states of the model during training. Providing checkpoints allows researchers to analyze the training process and resume training if needed.
Log Files (I.5): Records of the training and evaluation processes, including system outputs and errors. Access to log files aids in debugging and understanding the model's development trajectory.
Sample Model Outputs (I.6): Examples of the model's predictions or generated content. Sharing sample outputs demonstrates the model's capabilities and potential applications.
By ensuring that these 16 components are openly available under appropriate licenses, the MOF aims to foster an environment of openness and collaboration in AI development. This comprehensive approach addresses issues of "open-washing" and promotes genuine transparency, enabling the community to reproduce, validate, and build upon existing models effectively.
Development of Moxin LLM 7B
Moxin LLM 7B exemplifies a steadfast commitment to transparency and inclusivity by meticulously adhering to the principles outlined in the Model Openness Framework (MOF). This adherence ensures that every facet of the model's development is accessible, reproducible, and open for community engagement.
In alignment with MOF's comprehensive criteria, Moxin LLM 7B has made available all 16 critical components that constitute a complete model release. This includes the model architecture, parameters, training code, datasets, configurations, and evaluation metrics. By providing these components under permissive open-source licenses, the developers facilitate unrestricted use, modification, and distribution of the model, fostering an environment conducive to innovation and collaboration.
The development process of Moxin LLM 7B was characterized by an unwavering dedication to openness. The pre-training code and configurations were released, allowing researchers to understand the foundational aspects of the model's training regimen. Training and fine-tuning datasets were made publicly available, enabling the community to scrutinize and build upon the data that shaped the model's learning. Intermediate and final checkpoints were also shared, offering insights into the model's progression and facilitating further experimentation.
This comprehensive openness not only aligns with the highest MOF classification of "open science" but also addresses prevalent concerns in the AI community regarding "openwashing," where models are superficially labeled as open-source without providing meaningful access to their development components. By fully complying with MOF, Moxin LLM 7B sets a benchmark for genuine transparency, ensuring that the model's development is both reproducible and verifiable.
Furthermore, this adherence to MOF principles enhances the model's inclusivity. By making all components accessible, Moxin LLM 7B invites a diverse range of contributors to engage with the model, whether for academic research, commercial application, or independent study. This inclusivity promotes a more equitable AI landscape, where advancements are shared, scrutinized, and enhanced by a broad spectrum of voices.
Moxin LLM 7B stands as a testament to the power of collaborative research, bringing together experts from a diverse array of institutions to advance the field of natural language processing. This collective effort underscores the importance of interdisciplinary collaboration in developing open-source AI models that are both innovative and accessible.
The development of Moxin LLM 7B involved researchers from several esteemed universities, including Northeastern University, Harvard University, Cornell University, Tulane University, and the University of Washington. These institutions contributed their expertise in machine learning, computational linguistics, and data science, providing a solid academic foundation for the project. The collaboration among these universities facilitated the integration of diverse perspectives and methodologies, enriching the model's development process.
In addition to academic institutions, the project benefited from the involvement of industry leaders such as Roboraction.ai, Futurewei Technologies, and AIBAO LLC. These organizations brought practical insights and resources, ensuring that the model's development was aligned with real-world applications and industry standards. Their participation also highlighted the importance of bridging the gap between academic research and industry practice, fostering a more holistic approach to AI development.
This collaborative endeavor was guided by the principles of the Model Openness Framework (MOF), which emphasizes transparency, reproducibility, and inclusivity in AI research. By adhering to MOF, the team ensured that Moxin LLM 7B was developed with a commitment to open science, making all components of the model—including pre-training code, datasets, configurations, and intermediate checkpoints—freely accessible to the public. This openness not only promotes trust within the AI community but also encourages further research and innovation by providing a solid foundation for future work.
The collaborative nature of this project exemplifies the collective effort required to advance AI technologies responsibly and ethically. By pooling resources and expertise from a wide range of institutions and organizations, the team behind Moxin LLM 7B has set a precedent for future AI developments, demonstrating that collaboration across academia and industry can lead to significant advancements in the field.
For those interested in exploring Moxin LLM 7B further, the model is available on Hugging Face, where it can be accessed and utilized for various natural language processing tasks.
This initiative not only advances the capabilities of AI models but also fosters a culture of openness and collaboration that is essential for the responsible development of artificial intelligence.
Features of Moxin LLM 7B
Moxin LLM 7B is a state-of-the-art language model that exemplifies the convergence of advanced architecture and innovative attention mechanisms, designed to handle extensive contexts with remarkable efficiency. At its core, the model comprises 7 billion parameters, a substantial scale that enables it to capture intricate patterns and nuances within language data. This parameter count positions Moxin LLM 7B as a robust tool for a wide array of natural language processing (NLP) tasks, including text generation, translation, and summarization.
A standout feature of Moxin LLM 7B is its expansive context window, accommodating up to 32,000 tokens. This extended context size allows the model to process and generate longer sequences of text without losing coherence or context, a significant advantage over models with more limited context windows. Such capability is particularly beneficial for applications involving lengthy documents or complex dialogues, where maintaining context over extended text spans is crucial.
To efficiently manage this extensive context, Moxin LLM 7B employs advanced attention mechanisms, notably Grouped-Query Attention (GQA) and Sliding Window Attention (SWA). GQA enhances the model's ability to focus on relevant parts of the input sequence by grouping queries, thereby reducing computational overhead and improving processing speed. This mechanism is particularly effective during the decoding phase, allowing for larger batch sizes and higher throughput, which is essential for real-time applications.
Complementing GQA, the Sliding Window Attention mechanism enables the model to handle long sequences by applying a sliding window approach. This method allows each token to attend to a fixed-size window of surrounding tokens, effectively managing long-range dependencies without incurring substantial computational costs. The implementation of SWA ensures that Moxin LLM 7B can process lengthy inputs efficiently, making it suitable for tasks that require understanding and generating long-form content.
The integration of these attention mechanisms not only enhances the model's performance but also contributes to its versatility across various NLP applications. By leveraging GQA and SWA, Moxin LLM 7B achieves a balance between computational efficiency and the ability to maintain context over extended text spans. This balance is crucial for applications such as document summarization, code generation, and complex question-answering systems, where understanding and generating long sequences are essential.
Moxin LLM 7B is a fully open-source language model that offers two distinct versions: Base and Chat. Both versions have achieved the highest classification under the Model Openness Framework (MOF), designated as "open science." This classification underscores the model's commitment to transparency, reproducibility, and inclusivity in AI research.
The Base version of Moxin LLM 7B serves as the foundational model, providing a robust architecture suitable for a wide range of natural language processing tasks. It is designed to handle various applications, including text generation, translation, and summarization, offering flexibility for researchers and developers to fine-tune the model according to specific requirements. The Base model's open-source nature allows users to access and modify the underlying code, facilitating customization and adaptation to diverse use cases.
The Chat version, on the other hand, is fine-tuned specifically for conversational AI applications. This version has been trained on dialogue-specific datasets, enabling it to generate contextually relevant and coherent responses in a conversational setting. The Chat model's specialization makes it particularly effective for applications such as chatbots, virtual assistants, and other interactive AI systems. By providing the Chat model as an open-source resource, the developers encourage the AI community to explore and build upon its capabilities, fostering innovation in conversational AI technologies.
Both versions of Moxin LLM 7B are accessible through platforms like GitHub and Hugging Face, where users can download the models, review the source code, and contribute to their development. This accessibility aligns with the principles of open science, promoting collaboration and knowledge sharing within the AI community. The comprehensive release of pre-training code, datasets, configurations, and intermediate checkpoints ensures that the models are not only usable but also transparent and reproducible.
By offering both the Base and Chat versions under the "open science" classification, Moxin LLM 7B exemplifies a commitment to advancing AI technologies in an open and collaborative manner. This approach empowers researchers, developers, and organizations to leverage the models for a wide array of applications, contributing to the broader goal of fostering an open and inclusive AI ecosystem.
Access and Usage
Moxin LLM 7B, a fully open-source language model developed in accordance with the Model Openness Framework (MOF), is available for download in two versions: Base and Chat. Both versions have achieved the highest MOF classification, "open science," ensuring transparency and accessibility for the AI community.
To access the models, you can visit the official GitHub repository at https://github.com/moxin-org/Moxin-LLM. Within this repository, you'll find detailed instructions on downloading and setting up the models, along with the necessary code and configurations.
For those preferring to use the models directly without local setup, Moxin LLM 7B is also available on Hugging Face. You can download the Base model from https://huggingface.co/moxin-org/moxin-llm-7b and the Chat model from https://huggingface.co/moxin-org/moxin-llm-7b-chat. Hugging Face provides an intuitive interface for model deployment and inference, facilitating seamless integration into various applications.
Both platforms offer comprehensive resources, including technical documentation, usage examples, and community support, to assist you in effectively utilizing Moxin LLM 7B for your projects. By providing these models under the "open science" classification, the developers aim to promote transparency, reproducibility, and inclusivity in AI research, fostering a more open and collaborative AI ecosystem.
To perform inference with Moxin LLM 7B, you can utilize the Hugging Face Transformers library, which provides a straightforward interface for loading and interacting with the model. Ensure you have the necessary dependencies installed:
Once the dependencies are installed, you can use the following Python code to load the model and tokenizer, and generate text based on a given prompt:
In this script:
Model Loading: The model and tokenizer are loaded from the Hugging Face Model Hub using the specified model name.
Pipeline Initialization: A text generation pipeline is set up with the model and tokenizer, specifying the data type and device mapping.
Text Generation: The
pipefunction generates text based on the provided prompt, with parameters controlling the sampling behavior, such astemperature,top_k, andtop_p.Output: The generated text is printed to the console.
This approach leverages the Hugging Face Transformers library to facilitate seamless interaction with Moxin LLM 7B, enabling efficient text generation for various applications.
Conclusion
Moxin LLM 7B, developed in accordance with the Model Openness Framework (MOF), represents a significant advancement in the field of artificial intelligence, particularly in natural language processing (NLP). Its fully open-source nature and adherence to the principles of open science, open source, open data, and open access have profound implications for research, development, and business applications, fostering a more inclusive and collaborative AI ecosystem.
In the realm of research, Moxin LLM 7B's open-source availability democratizes access to advanced AI models. Researchers across various institutions can now study, modify, and build upon the model without the constraints typically associated with proprietary systems. This openness accelerates innovation, as scholars can experiment with the model's architecture, fine-tune it for specific tasks, and contribute to its evolution. The comprehensive release of pre-training code, configurations, training and fine-tuning datasets, and intermediate checkpoints ensures that the model is not only usable but also transparent and reproducible, which is crucial for fostering a more inclusive and collaborative research environment.
For developers, Moxin LLM 7B offers a robust foundation for creating a wide array of applications. Its architecture, featuring a 32k token context size and advanced attention mechanisms like grouped-query attention (GQA) and sliding window attention (SWA), makes it particularly adept at handling complex tasks such as code generation, document summarization, and multilingual translation. The model's open-source status allows developers to customize and integrate it into diverse platforms, enhancing the versatility and functionality of their applications. This adaptability is further supported by the model's strong performance in zero-shot and few-shot evaluations, demonstrating its capability to handle complex reasoning, coding, and multitask challenges.
In business contexts, Moxin LLM 7B's open-source nature reduces the barriers to entry for companies seeking to leverage AI technologies. Organizations can deploy the model for various purposes, including customer service automation, content generation, and data analysis, without the high costs and licensing complexities associated with proprietary models. This accessibility enables businesses to innovate and enhance their operations, contributing to a more open and competitive market landscape. The model's balance between computational efficiency and output quality makes it practical for both research and real-world use cases.
Furthermore, Moxin LLM 7B's compliance with the MOF ensures that it meets rigorous standards for openness and completeness. This adherence not only sets a benchmark for future AI model development but also encourages other entities to adopt similar practices, promoting a culture of transparency and collaboration within the AI community. By providing comprehensive access to the model's components and training data, Moxin LLM 7B exemplifies a commitment to advancing AI technologies in an open and collaborative manner.
The release of Moxin LLM 7B, developed in accordance with the Model Openness Framework (MOF), signifies a pivotal moment in the evolution of artificial intelligence, particularly in the realm of natural language processing (NLP). This development not only enhances the current landscape but also sets the stage for future advancements that could profoundly impact research, development, and business applications.
One of the most promising prospects is the acceleration of collaborative research. With Moxin LLM 7B's open-source nature, researchers worldwide can access, modify, and build upon the model without the constraints typically associated with proprietary systems. This openness fosters a more inclusive research environment, enabling scholars to experiment with the model's architecture, fine-tune it for specific tasks, and contribute to its evolution. Such collaboration is expected to lead to the development of more sophisticated models, driving innovation in AI research.
In the development sector, Moxin LLM 7B's architecture, featuring a 32k token context size and advanced attention mechanisms like grouped-query attention (GQA) and sliding window attention (SWA), offers a robust foundation for creating a wide array of applications. Its open-source status allows developers to customize and integrate it into diverse platforms, enhancing the versatility and functionality of their applications. This adaptability is anticipated to lead to the creation of more efficient and effective AI-driven solutions across various industries.
For businesses, the open-source nature of Moxin LLM 7B reduces the barriers to entry for leveraging AI technologies. Organizations can deploy the model for various purposes, including customer service automation, content generation, and data analysis, without the high costs and licensing complexities associated with proprietary models. This accessibility is expected to democratize AI capabilities, enabling businesses of all sizes to innovate and enhance their operations, thereby contributing to a more open and competitive market landscape.
Furthermore, Moxin LLM 7B's adherence to the MOF ensures that it meets rigorous standards for openness and completeness. This commitment to transparency is anticipated to set a benchmark for future AI model development, encouraging other entities to adopt similar practices. Such adherence is expected to promote a culture of transparency and collaboration within the AI community, leading to the development of more reliable and trustworthy AI systems.
In summary, the release of Moxin LLM 7B and its adherence to the Model Openness Framework are poised to drive significant advancements in AI research, development, and business applications. By promoting transparency, reproducibility, and inclusivity, it is expected to empower researchers, developers, and businesses to innovate and collaborate, thereby advancing the field of artificial intelligence and fostering a more open and inclusive AI ecosystem.
Press contact
Timon Harz
oneboardhq@outlook.com
Other posts





Company
About
Blog
Careers
Press
Legal
Privacy
Terms
Security