Timon Harz
December 18, 2024
How Specifications Drive the Modularization of Large Language Models
Discover the key role specifications play in enhancing the modularity and flexibility of LLMs. Learn how emerging methodologies are transforming AI development into a more structured, engineering-driven process.

Over the past few decades, software has been a key driver of economic growth, a phenomenon famously highlighted by Andreessen in his influential blog post, “Why Software is Eating the World.” Today, the technological landscape is undergoing another major shift, driven by Artificial Intelligence, particularly Large Language Models (LLMs), which are poised to transform the software ecosystem. To unlock the full potential of this technology, experts argue that LLM-based systems must be developed with the same engineering rigor and reliability found in established fields like control theory, mechanical engineering, and software engineering. Specifications play a crucial role in this process, offering a framework for system decomposition, component reusability, and thorough system verification.
Generative AI has made remarkable strides in the past two decades, with rapid advancements since the launch of ChatGPT. However, this progress is largely due to the development of increasingly larger models, which require vast computational resources and significant financial investments. Building these state-of-the-art models costs hundreds of millions of dollars, and future expenses could reach billions. This approach presents two major challenges: first, the high costs make it difficult for all but a few companies to develop these models, and second, the monolithic nature of these models complicates identifying and addressing inaccuracies. Hallucinations, a prominent issue in AI outputs, demonstrate the difficulty in debugging and refining these complex systems, limiting the broader growth and accessibility of AI technologies.
Researchers from UC Berkeley, UC San Diego, Stanford University, and Microsoft Research have identified two types of specifications: statement specifications and solution specifications. Statement specifications outline the fundamental objectives of a task, answering the question, “What should this task achieve?” On the other hand, solution specifications define the methods for verifying task outputs, addressing the query, “How can we ensure the solution meets the original specification?” These specifications are illustrated in different domains: in traditional software development, statement specifications take the form of Product Requirements Documents, while solution specifications are represented by input-output tests. Formal frameworks like Coq/Gallina embody statement specifications through formal specifications and solution specifications through proofs that demonstrate code correctness. In some cases, particularly in mathematical problem-solving, the statement and solution specifications can align seamlessly, offering a unified approach to defining and verifying tasks.
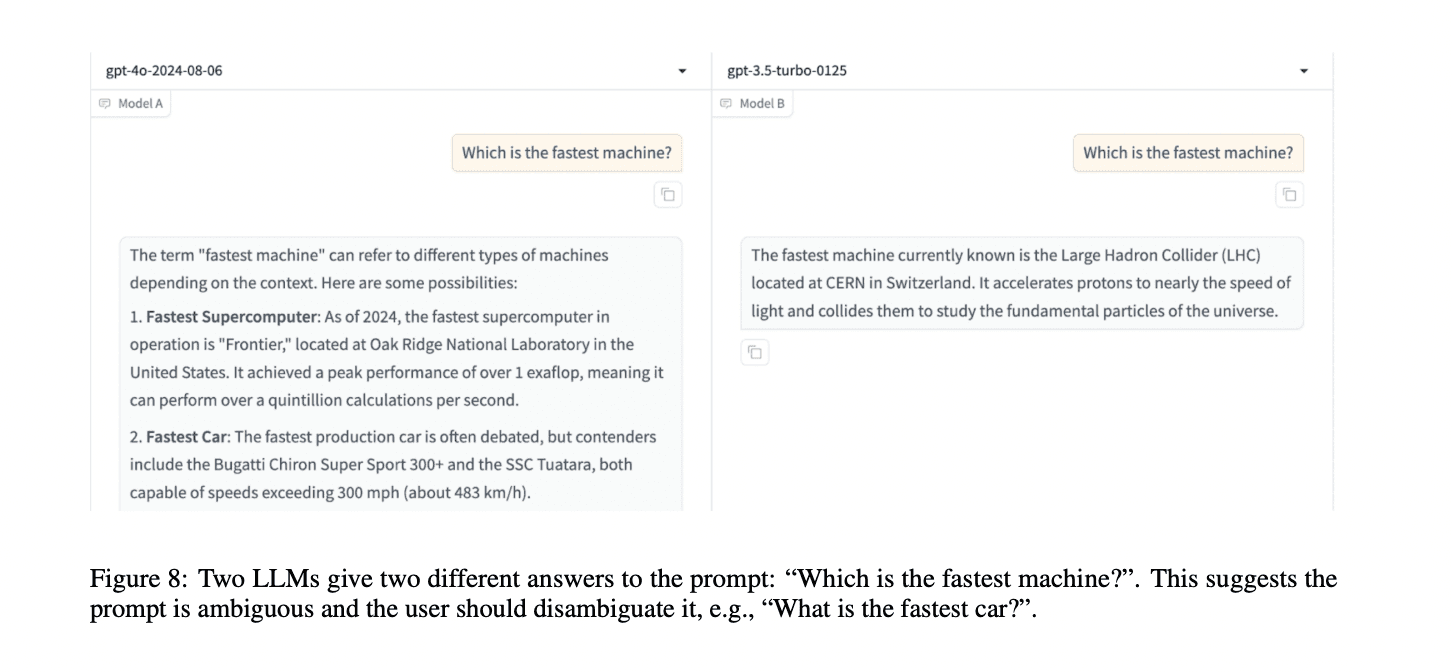
LLMs face a key challenge in task specification: balancing the ease of using natural language with its inherent ambiguity. This conflict arises because prompts can be both flexible and unclear at the same time. Some prompts are inherently ambiguous, making precise interpretation impossible, such as "Write a poem about a white horse in Shakespeare’s style." Other prompts have ambiguities that can be resolved with additional context or clarification. For example, a prompt like "How long does it take to go from Venice to Paris?" can be disambiguated by providing specific details about the locations and transportation methods. Researchers are exploring various methods to address these challenges, drawing from human communication strategies to create more precise and effective task definitions for LLMs.
LLMs encounter significant challenges in verifiability and debuggability, two essential engineering properties that ensure system reliability. Verifiability concerns whether a task’s implementation matches its original specification, a process complicated by ambiguous solution specifications and the risk of hallucinations. Researchers suggest several methods to improve verification, such as proof-carrying outputs, step-by-step verification, execute-then-verify techniques, and statistical verification approaches. Debuggability adds another layer of complexity, as LLMs often function as black boxes where traditional debugging techniques are ineffective. Emerging strategies include generating multiple outputs, using self-consistency checks, leveraging mixtures of outputs, and implementing process supervision to iteratively refine system performance. These approaches aim to shift LLM development from trial and error to a more systematic, engineered process.

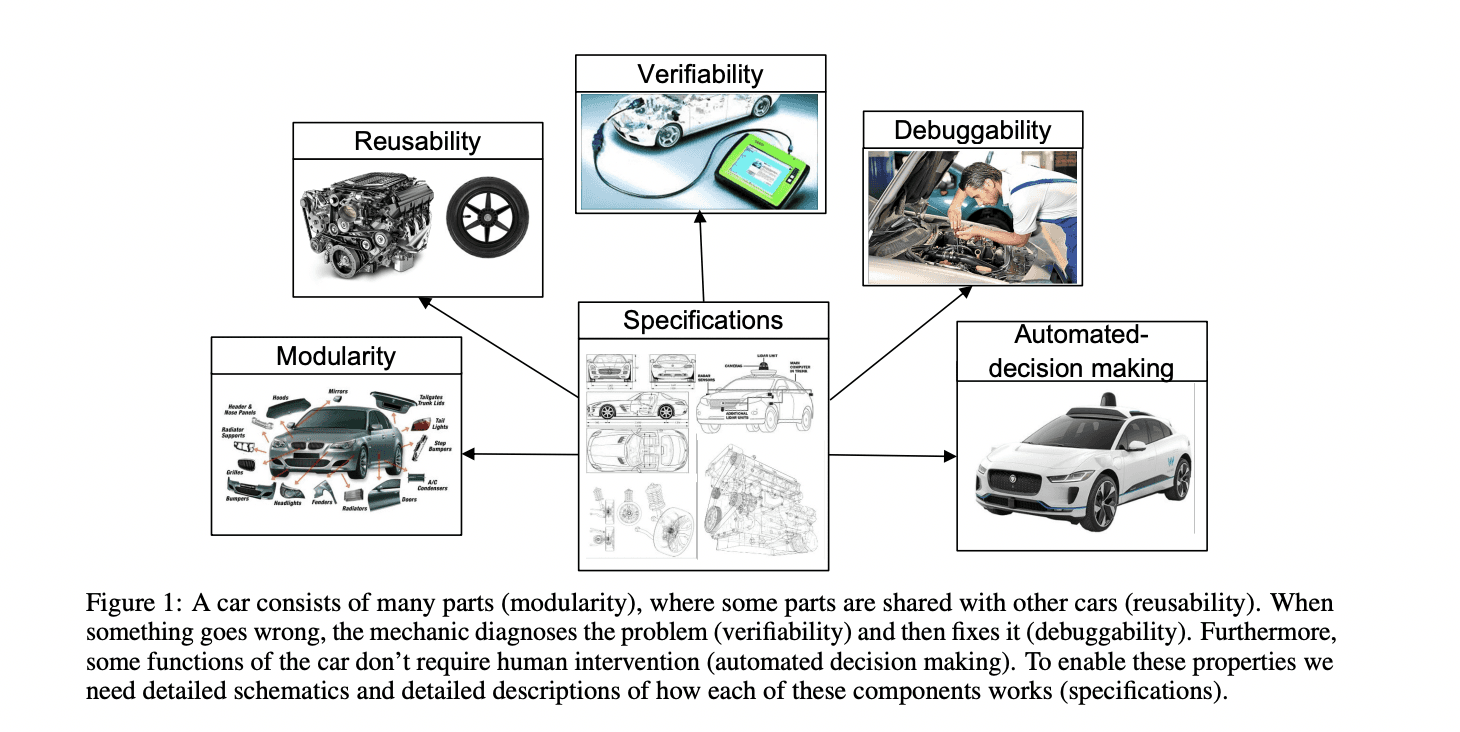
Engineering disciplines have historically fueled significant economic progress by emphasizing five key properties: verifiability, debuggability, modularity, reusability, and automatic decision-making. These properties enable developers to efficiently build complex systems, establish reliable infrastructures, and create autonomous solutions. The foundation of these properties lies in clear, precise specifications that outline task objectives and offer thorough verification mechanisms. Artificial Intelligence, especially LLMs, stands at the brink of another transformative shift in both economic and social landscapes. However, the inherent ambiguity in LLM task specifications, driven by the complexity of natural language, poses a major challenge to systematic development. Researchers argue that developing methods to generate unambiguous statement and solution specifications is essential for advancing LLM technology and expanding its real-world applications.
Large Language Models (LLMs) are advanced deep learning algorithms designed to understand and generate human-like text. They utilize transformer architectures and are trained on extensive datasets, enabling them to perform a wide array of natural language processing (NLP) tasks, including translation, summarization, and question-answering.
The significance of LLMs in NLP is profound. Their ability to comprehend context and generate coherent text has revolutionized applications such as chatbots, content creation, and language translation. By processing vast amounts of text data, LLMs capture intricate language patterns, facilitating more accurate and contextually relevant outputs.
However, the growing complexity of LLMs presents challenges. As these models scale, they demand substantial computational resources and pose difficulties in interpretation and fine-tuning. Understanding the internal mechanisms of LLMs remains an active area of research, as scientists strive to decode their operations and enhance their reliability.
Modularity in Large Language Models (LLMs) is essential for enhancing efficiency, scalability, and adaptability. By structuring models into distinct, specialized components, each focusing on specific tasks or domains, we can achieve several key benefits:
Efficiency: Modular designs allow for the activation of only relevant components during processing, reducing computational load and improving response times. For instance, the ModuleFormer architecture leverages modularity to enhance efficiency by activating a subset of modules for each input token, achieving performance comparable to dense LLMs with significantly higher throughput.
Scalability: Modular systems can be expanded by adding new modules without overhauling the entire model. This flexibility facilitates the integration of new knowledge or capabilities, enabling LLMs to adapt to evolving requirements. Research indicates that standard LLMs can be fine-tuned as Mixture-of-Expert (MoE) models, effectively improving generalization without introducing extra parameters.
Adaptability: Modular architectures support specialization, allowing LLMs to focus on specific tasks or domains. This specialization enhances performance in targeted areas and enables the model to handle a broader range of applications. For example, the mPLUG-Owl model employs modularization to empower LLMs with multimodal capabilities, demonstrating improved instruction and visual understanding abilities.
Specifications are precise descriptions of the expected behaviors, inputs, and outputs of each component within a system. In the context of Large Language Models (LLMs), specifications serve as a foundational tool for guiding modularization. By clearly defining the functions and interactions of individual modules, specifications enable the decomposition of complex systems into manageable, reusable components. This approach not only enhances the efficiency of development but also ensures that each module operates reliably within the larger framework. Researchers argue that realizing the full potential of LLMs requires developing systems with the same engineering rigor and reliability found in established disciplines like control theory, mechanical engineering, and software engineering. Specifications emerge as a fundamental tool that can facilitate this systematic development, enabling complex system decomposition, component reusability, and comprehensive system verification.
However, defining specifications for LLM components presents unique challenges. The generality of LLMs and the inherent ambiguity of natural language make it difficult to establish precise specifications. This complexity underscores the need for ongoing research to develop methodologies that can effectively capture the nuanced behaviors of LLM components.
The Need for Modularity in LLMs
Scaling Large Language Models (LLMs) presents several significant challenges, particularly concerning computational demands, training complexities, and the difficulties associated with updating knowledge bases.
The computational requirements for training LLMs are substantial. As models increase in size and complexity, they demand more processing power, memory, and storage. This escalation leads to higher energy consumption and longer training times, making the process both resource-intensive and costly. For instance, training state-of-the-art LLMs can involve thousands of GPUs running for weeks or even months, resulting in significant financial and environmental costs.
Training these models also involves complexities related to data preparation and model optimization. The vast amounts of data required must be carefully curated and preprocessed to ensure quality and relevance. Additionally, optimizing the models to effectively learn from this data without overfitting or underfitting presents ongoing challenges. Researchers are continually exploring new training techniques to address these issues, such as developing methods that mimic human-like thinking to improve model performance.
Updating the knowledge bases of LLMs is another significant challenge. As the world evolves, models need to incorporate new information to remain accurate and relevant. Traditional retraining methods are often impractical due to the computational costs and time required. To address this, researchers are developing more efficient techniques for knowledge editing, allowing models to update their knowledge without comprehensive retraining. These methods aim to modify specific parts of the model's knowledge base, enabling timely updates while preserving overall performance.
Modularity in Large Language Models (LLMs) offers several advantages that enhance their efficiency, scalability, and adaptability.
One significant benefit is improved maintainability. By dividing LLMs into specialized modules, each responsible for specific tasks or domains, developers can update or replace individual components without overhauling the entire system. This modular approach simplifies debugging and allows for targeted improvements, leading to more robust and reliable models.
Additionally, modularity enables specialization. Each module can be tailored to handle specific types of data or tasks, enhancing the model's performance in those areas. For example, specialized modules can process different data formats—such as text, images, or audio—more effectively, leading to better overall performance.
Furthermore, modularity facilitates the independent updating or replacement of modules. This flexibility allows models to adapt to new information or tasks without the need for complete retraining. Researchers have demonstrated that standard LLMs can be fine-tuned as Mixture-of-Expert (MoE) models without introducing extra parameters, effectively improving generalization across various tasks.
Specifications as the Foundation for Modularity
In the context of Large Language Models (LLMs), specifications are detailed descriptions of the expected behaviors, inputs, and outputs of each component within the model. These specifications serve as blueprints, guiding the development and integration of individual modules to ensure they function correctly within the larger system.
Defining specifications involves outlining the precise requirements and constraints for each module. This includes specifying the types of inputs the module can process, the operations it performs, and the format and structure of its outputs. Clear specifications are essential for several reasons:
Ensuring Consistency: They provide a standard framework that all components must adhere to, promoting uniformity across the system.
Facilitating Integration: Well-defined specifications make it easier to combine modules, as developers can anticipate how each component will behave and interact with others.
Enabling Verification: Specifications allow for the testing and validation of each module against its defined requirements, ensuring reliability and performance standards are met.
For instance, in software engineering, specifications are used to define the expected behavior of software components, ensuring that each part functions as intended and integrates seamlessly with other parts of the system. Similarly, in AI systems, specifications help in decomposing complex systems into manageable modules, facilitating component reusability and comprehensive system verification.
Clear specifications are essential in guiding the modular design of Large Language Models (LLMs), ensuring that each component meets specific requirements and functions correctly within the larger system. By defining the expected behaviors, inputs, and outputs of individual modules, specifications provide a structured framework that informs the design and integration of these components.
In the context of LLMs, specifications serve several critical purposes:
Defining Module Functions: Specifications outline the specific tasks or functions that each module is intended to perform. This clarity ensures that each component contributes effectively to the overall model's objectives.
Establishing Input and Output Standards: By specifying the types and formats of inputs and outputs, specifications ensure consistency across modules. This standardization facilitates seamless communication between components and simplifies the integration process.
Guiding Development and Testing: Specifications provide a basis for developing and testing individual modules. They set clear criteria for performance and functionality, enabling developers to verify that each component operates as intended before integration.
For example, in the development of the ModuleFormer architecture, researchers emphasized the importance of clear specifications in guiding the design of specialized modules. By defining the expected behaviors and interactions of these modules, they were able to create a system that balances efficiency, extendability, and specialization.
Case Studies and Research Insights
Emergent modularity in Large Language Models (LLMs) refers to the spontaneous development of modular structures during the pre-training phase, where the model's architecture naturally organizes into specialized components without explicit design. This phenomenon enables LLMs to perform distinct functions within different regions of their architecture, enhancing their efficiency and adaptability.
A study titled "Unlocking Emergent Modularity in Large Language Models" explores this concept by demonstrating that standard LLMs can be fine-tuned into Mixture-of-Expert (MoE) models without introducing additional parameters. These MoEs, termed Emergent MoEs (EMoE), leverage the model's inherent modularity to improve performance on both in-domain and out-of-domain tasks. The research indicates that fine-tuning EMoE enhances generalization capabilities compared to traditional fine-tuning methods.
The study also highlights that this emergent modularity is robust across various configurations and scales effectively to large models, such as Llama2-7B and Llama-30B. This scalability suggests that leveraging emergent modularity can lead to more efficient and adaptable LLMs, capable of handling a wide range of tasks with improved performance.
Modular architectures have significantly advanced the capabilities of Large Language Models (LLMs), particularly in integrating multimodal functionalities. A notable example is the mPLUG-Owl model, which employs a modularized training approach to equip LLMs with multimodal abilities. This model incorporates a foundation LLM, a visual knowledge module, and a visual abstractor module, enabling the system to process and generate both textual and visual information effectively.
The mPLUG-Owl model utilizes a two-stage training paradigm to align images and text. In the first stage, the visual knowledge and abstractor modules are trained with a frozen LLM to align image and text data. The second stage involves fine-tuning a low-rank adaptation (LoRA) module on the LLM and abstractor module using language-only and multimodal supervised datasets, while keeping the visual knowledge module frozen. This approach allows the model to maintain and even enhance its generation abilities while integrating visual information.
Experimental results demonstrate that mPLUG-Owl outperforms existing multimodal models, showcasing impressive instruction and visual understanding abilities, multi-turn conversation capabilities, and knowledge reasoning skills. Additionally, the model exhibits unexpected abilities such as multi-image correlation and scene text understanding, enabling applications in complex real-world scenarios like vision-only document comprehension.
Building upon the foundation of mPLUG-Owl, the mPLUG-Owl2 model introduces a modularized network design with the language decoder serving as a universal interface for managing different modalities. This design facilitates modality collaboration, allowing the model to generalize across both text and multimodal tasks and achieve state-of-the-art performance with a single generic model.
These advancements in modular architectures underscore the potential of LLMs to integrate and process multimodal information effectively, paving the way for more versatile and powerful AI systems.
Challenges and Considerations
Defining effective specifications for Large Language Model (LLM) components is a complex endeavor, primarily due to the inherent ambiguities in natural language and the intricate nature of LLMs. Unlike traditional software systems, where specifications can be precisely defined, LLMs often require specifications through natural language prompts, which can introduce significant ambiguity.
One of the primary challenges is the difficulty in describing and testing every possible behavior of an LLM component. The vastness of potential inputs and the model's capacity to generate diverse outputs make it challenging to anticipate and specify all possible scenarios. This complexity is further compounded by the fact that, apart from formal specifications, most specifications contain some degree of ambiguity.
Additionally, the dynamic nature of LLMs, which can adapt and evolve based on the data they are trained on, adds another layer of complexity. This adaptability means that even well-defined specifications might not account for all emergent behaviors, making it difficult to ensure that components function as intended across all contexts.
Moreover, the integration of LLMs into existing systems requires specifications that not only define individual component behaviors but also ensure seamless interaction between components. This necessitates a comprehensive understanding of both the individual and collective functionalities of the components, further complicating the specification process.
Balancing modularity and flexibility in Large Language Models (LLMs) is a nuanced challenge. While modularity enhances efficiency and adaptability by decomposing complex tasks into specialized components, it can also introduce rigidity, potentially limiting the model's capacity to handle diverse tasks. Conversely, excessive flexibility may lead to inefficiencies and difficulties in managing specialized functions.
Recent research has explored this balance. The study "Balancing Speciality and Versatility: a Coarse to Fine Framework for Supervised Fine-tuning Large Language Model" proposes a framework that addresses this tension. By employing a coarse-to-fine approach, the framework fine-tunes specific modules to enhance specialization while preserving the model's overall versatility. This method mitigates the risk of catastrophic forgetting, where fine-tuning on new tasks erodes performance on previous ones. The framework demonstrates that carefully managing the specialization of modules can lead to improved performance across a range of tasks.
Similarly, the "ModuleFormer" architecture introduces a modular design that activates a subset of modules for each input token. This approach achieves efficiency by processing only relevant modules, thereby enhancing throughput without compromising performance. It also allows for the extension of the model with new modules, facilitating the integration of new knowledge without forgetting existing information. This design exemplifies how modularity can be implemented to maintain flexibility and adaptability in LLMs.
Future Directions
Advancements in specification techniques are pivotal in driving the modularization of Large Language Models (LLMs). Recent research has introduced several methodologies to enhance the precision and applicability of specifications, thereby facilitating more efficient and reliable LLM development.
One notable advancement is the use of Large Language Models (LLMs) to derive formal specifications from unstructured natural language. The nl2spec framework exemplifies this approach by translating natural language requirements into temporal logics, addressing the inherent ambiguities of natural language. This interactive process allows users to refine specifications iteratively, improving the accuracy and utility of the generated formalizations.
Another significant development is the integration of process supervision and test-time computation to enhance specification precision. By incorporating structured outputs and process supervision, researchers aim to transform LLM development from a trial-and-error approach to a more systematic, engineered methodology. This shift is expected to improve the reliability and modularity of LLM-based systems.
Furthermore, the exploration of modular architectures, such as the mPLUG-Owl model, demonstrates how modularization can empower LLMs with multimodal capabilities. This approach involves training LLMs with visual knowledge modules and abstractor modules, enabling the models to process and generate both textual and visual information effectively.
Looking ahead, the future of specification methodologies for LLMs is poised to focus on enhancing the precision and applicability of specifications. By leveraging advanced techniques like interactive translation of natural language to formal specifications and integrating process supervision, the development of modular and reliable LLM-based systems is expected to become more systematic and efficient. These advancements will likely lead to more robust and adaptable LLMs, capable of handling a broader range of tasks with greater reliability.
Integrating modular Large Language Models (LLMs) with emerging technologies like robotics and autonomous systems holds significant promise for advancing intelligent automation. By leveraging detailed specifications, these models can enhance the capabilities of autonomous systems across various domains.
In robotics, LLMs can interpret natural language commands, enabling robots to understand and execute tasks with human-like proficiency. For instance, a study demonstrated that LLMs could control robots through natural language prompts, translating commands into precise actions.
Furthermore, integrating LLMs with digital twins and industrial automation systems can facilitate intelligent planning and control of production processes. A proposed framework combines LLMs, digital twins, and automation systems to enable intelligent planning and control of production processes.
Additionally, LLMs can enhance autonomous systems by enabling them to process and generate both textual and visual information effectively. For example, the mPLUG-Owl model integrates visual and textual modules to enhance multimodal capabilities, allowing robots to process and generate both textual and visual information effectively.
Moreover, LLMs can improve human-robot interaction by enabling robots to engage in natural language conversations, making them more user-friendly and accessible. This capability is crucial for applications in education and customer service, where understanding user intent is paramount.
Conclusion
Specifications are fundamental in driving the modularization of Large Language Models (LLMs), serving as precise descriptions of expected behaviors, inputs, and outputs for each component. This clarity enables the decomposition of complex tasks into specialized modules, enhancing efficiency and adaptability. However, defining such specifications is challenging due to the inherent ambiguities of natural language and the intricate nature of LLMs. Despite these challenges, advancements in specification techniques, such as interactive translation of natural language to formal specifications and the integration of process supervision, are paving the way for more modular and reliable LLM-based systems. These developments are crucial for the effective integration of LLMs with emerging technologies like robotics and autonomous systems, leading to more intelligent and adaptable applications.
Integrating detailed specifications into the development of Large Language Models (LLMs) is poised to significantly influence the future of AI model development and deployment. By establishing clear and precise guidelines for each component, this approach enhances the modularity, reliability, and adaptability of AI systems.
A study titled "Specifications: The Missing Link to Making the Development of LLM Systems an Engineering Discipline" emphasizes that incorporating formal specifications is crucial for transforming LLM development into a more systematic and engineering-focused process. This shift addresses challenges in building reliable and modular LLM systems, highlighting the need for clear specifications in AI development.
Furthermore, the article "The Role of Specifications in Modularizing Large Language Models" discusses how specifications facilitate systematic development by enabling complex system decomposition, component reusability, and comprehensive system verification. This perspective underscores the importance of specifications in achieving modularity and reliability in AI systems.
By adopting this approach, AI models can achieve greater specialization and efficiency, leading to more robust and adaptable systems. This advancement is particularly beneficial for applications requiring high reliability and performance, such as autonomous systems and robotics.
In summary, the integration of detailed specifications into AI model development represents a pivotal step toward more structured and dependable AI systems. This methodology not only enhances the modularity and reliability of LLMs but also sets a precedent for future AI development practices, promoting a more engineering-oriented approach to AI system design and deployment.
References
In developing Large Language Models (LLMs), the integration of detailed specifications is crucial for enhancing modularity and reliability. A study titled "Specifications: The Missing Link to Making the Development of LLM Systems an Engineering Discipline" emphasizes that incorporating formal specifications is essential for transforming LLM development into a more systematic and engineering-focused process.
Another significant advancement is the exploration of emergent modularity within LLMs. The paper "Unlocking Emergent Modularity in Large Language Models" discusses how fine-tuning models can lead to improved generalization across various tasks, highlighting the potential of emergent modularity in enhancing LLM performance.
Additionally, the article "The Role of Specifications in Modularizing Large Language Models" discusses how specifications facilitate systematic development by enabling complex system decomposition, component reusability, and comprehensive system verification.
These resources collectively underscore the importance of clear specifications and the exploration of emergent modularity in advancing the development and deployment of LLMs.
Press contact
Timon Harz
oneboardhq@outlook.com
Other posts





Company
About
Blog
Careers
Press
Legal
Privacy
Terms
Security