Timon Harz
December 17, 2024
How do Large Language Models work?
Discover how Large Language Models (LLMs) work and explore their current applications and future potential. Understand the challenges and opportunities they bring to industries like healthcare, education, and more.
TLDR;
Large Language Models (LLMs) are a class of artificial intelligence systems designed to comprehend and generate human-like text. They achieve this by processing extensive datasets, enabling them to perform a variety of tasks such as text generation, translation, summarization, and more.
At their core, LLMs utilize deep learning techniques, particularly transformer architectures, to analyze and understand the intricacies of human language. These models are trained on vast amounts of text data, allowing them to learn patterns, structures, and nuances inherent in language. This training enables LLMs to generate coherent and contextually relevant text based on the input they receive.
The applications of LLMs are diverse and impactful. In natural language processing, they are employed for tasks such as language generation, translation, and summarization. In the realm of conversational AI, LLMs power chatbots and virtual assistants, facilitating human-like interactions. Additionally, they assist in code generation, aiding developers in writing and debugging code more efficiently.
Despite their capabilities, LLMs face several challenges. One significant concern is the potential for bias in their outputs, stemming from biases present in the training data. This issue raises questions about fairness and the ethical implications of deploying LLMs in sensitive areas. Another challenge is the interpretability of these models; understanding how LLMs arrive at specific outputs remains a complex task, which can be problematic in applications requiring transparency. Furthermore, the computational resources required to train and deploy LLMs are substantial, leading to concerns about their environmental impact and accessibility.
In summary, Large Language Models represent a significant advancement in artificial intelligence, offering powerful tools for understanding and generating human language. However, addressing the challenges associated with their use is crucial to ensure they are applied responsibly and effectively.
How do they work?
Large Language Models (LLMs) are sophisticated artificial intelligence systems that process and generate human-like text by analyzing vast amounts of textual data. Their functionality is rooted in deep learning architectures, particularly the transformer model, which enables them to understand and produce language with remarkable coherence and context.
The operational mechanism of LLMs begins with the ingestion of extensive text corpora, encompassing books, articles, websites, and other textual sources. This diverse dataset provides the model with a comprehensive understanding of language patterns, structures, and nuances. During the training phase, the model learns to predict the probability of a word or sequence of words following a given context, effectively capturing the syntactic and semantic relationships inherent in the language.
Central to the functionality of LLMs is the transformer architecture, which employs self-attention mechanisms to process input data. This design allows the model to weigh the importance of different words in a sentence, regardless of their position, thereby capturing long-range dependencies and contextual information. The self-attention mechanism computes attention scores for each word in relation to others, enabling the model to focus on relevant parts of the input when generating or interpreting text.
The training process involves adjusting the model's internal parameters to minimize the difference between its predicted outputs and the actual outcomes in the training data. This is achieved through backpropagation, where the model iteratively updates its parameters based on the error gradients computed during the prediction phase. The extensive training on diverse datasets enables LLMs to generalize across various language tasks, making them versatile tools for applications such as text generation, translation, summarization, and question-answering.
Once trained, LLMs can generate contextually relevant responses to a wide range of prompts. When a user inputs a query or statement, the model processes the input by encoding it into a numerical representation, which captures the semantic meaning of the text. It then decodes this representation to produce a response, drawing upon the patterns and information it learned during training. The model's ability to generate coherent and contextually appropriate text is a direct result of its exposure to diverse linguistic structures and contexts during the training phase.
The versatility of LLMs is further enhanced by their capacity to perform tasks beyond simple text generation. They can engage in complex dialogues, translate languages, summarize lengthy documents, and even generate code snippets, demonstrating their broad applicability across various domains. This adaptability is a testament to the depth of their training and the robustness of the transformer architecture.
However, the operation of LLMs is not without challenges. The models are sensitive to the quality and diversity of the training data; biases present in the data can be learned and perpetuated by the model, leading to biased outputs. Additionally, the vast number of parameters in LLMs makes them computationally intensive, requiring significant resources for both training and deployment. Despite these challenges, ongoing research and development continue to refine LLMs, enhancing their performance and mitigating issues related to bias and resource consumption.
In summary, Large Language Models function by processing extensive textual data through deep learning architectures, particularly transformers, to understand and generate human-like text. Their ability to learn from diverse datasets enables them to perform a wide array of language-related tasks, making them powerful tools in the field of artificial intelligence.
Applications of LLMs
Large Language Models (LLMs) have revolutionized numerous industries by enhancing efficiency, accuracy, and accessibility across various applications. Their ability to understand and generate human-like text has led to significant advancements in several domains.
In the realm of content generation, LLMs have become indispensable tools for writers, marketers, and content creators. They assist in drafting articles, reports, and creative pieces, enabling professionals to produce high-quality content more efficiently. By providing initial drafts or suggesting edits, LLMs streamline the content creation process, allowing human creators to focus on strategic and creative aspects. This capability has been particularly beneficial in industries where content volume and speed are critical.
In customer support, LLMs have transformed traditional service models by powering chatbots and virtual assistants. These AI-driven systems can handle a wide range of customer inquiries, providing timely and accurate responses. By understanding context and analyzing sentiment, LLMs offer personalized support, enhancing customer satisfaction and operational efficiency. This advancement has enabled businesses to offer 24/7 support without extensive human resources, ensuring a seamless support experience.
Language translation and localization have also benefited from LLMs. These models offer real-time, accurate translation services, making websites, applications, and digital content universally accessible. By understanding the nuances of different languages, LLMs facilitate effective communication across linguistic barriers, which is crucial for businesses aiming to reach a global audience. This capability has been instrumental in expanding the reach of digital content and services worldwide.
In the legal industry, LLMs have been utilized to analyze vast amounts of data and documents efficiently. Law firms have developed in-house AI tools tailored to their specific needs, enabling them to sort through complex legal texts and extract pertinent information. This application has enhanced the efficiency of legal research and document review processes, allowing legal professionals to focus on more strategic tasks.
Moreover, LLMs have been integrated into educational platforms to provide personalized learning experiences. By analyzing student interactions and performance, these models can offer tailored feedback and support, enhancing the learning process. This application has been particularly beneficial in language learning apps, where LLMs explain mistakes and facilitate practice conversations, thereby improving user engagement and learning outcomes.
In the field of healthcare, LLMs have been employed to analyze medical literature and assist in research. By processing large volumes of medical texts, these models can identify patterns and insights that may not be immediately apparent to human researchers. This capability has the potential to accelerate medical discoveries and improve patient care by providing healthcare professionals with comprehensive and up-to-date information.
Additionally, LLMs have been utilized in the financial sector to analyze market trends and assist in decision-making. By processing financial reports, news articles, and other relevant texts, these models can provide insights into market dynamics, aiding investors and analysts in making informed decisions. This application has enhanced the ability to predict market movements and assess investment opportunities.
Furthermore, LLMs have been integrated into creative industries, such as music and art, to generate new compositions and designs. By learning from existing works, these models can create original pieces that mimic the styles of various artists, offering new tools for creators and expanding the possibilities of artistic expression. This application has opened new avenues for creativity and innovation in the arts.
In summary, Large Language Models have a wide array of applications that span multiple industries, including content generation, customer support, language translation, legal analysis, education, healthcare, finance, and the arts. Their ability to understand and generate human-like text has led to significant advancements, enhancing efficiency, accuracy, and accessibility across various domains. As technology continues to evolve, the potential applications of LLMs are expected to expand, further integrating AI into everyday life and business operations.
Challenges
Large Language Models (LLMs) have significantly advanced the field of artificial intelligence, offering remarkable capabilities in understanding and generating human-like text. However, despite their impressive performance, LLMs face several critical challenges that impact their effectiveness, fairness, and reliability.
One of the most pressing concerns is the issue of bias. LLMs are trained on vast datasets sourced from the internet, which inherently contain biases present in human language and societal structures. These biases can manifest in various forms, including gender, racial, and cultural biases, leading to outputs that may perpetuate stereotypes or unfairly represent certain groups. For instance, a study highlighted in *Communications of the ACM* discusses how LLMs can inadvertently reinforce societal biases due to the nature of their training data.
Addressing these biases is complex, as it requires not only identifying and mitigating them within the models but also ensuring that the training data is representative and free from discriminatory content. Researchers are actively exploring techniques to reduce bias in LLMs, such as implementing fairness constraints during training and developing post-processing methods to adjust biased outputs.
Another significant challenge is the substantial computational resources required to train and deploy LLMs. The process demands extensive processing power, large-scale data storage, and significant energy consumption, raising concerns about environmental impact and accessibility. The energy-intensive nature of training these models has been discussed in various studies, emphasizing the need for more efficient algorithms and hardware to mitigate these issues.
The lack of interpretability in LLMs further complicates their deployment, especially in sensitive domains like healthcare, finance, and law. These models often operate as "black boxes," making it difficult to understand how they arrive at specific conclusions or recommendations. This opacity can undermine trust and hinder the adoption of LLMs in critical applications where understanding the decision-making process is essential.
Efforts to enhance the transparency of LLMs include developing methods to visualize and interpret the internal workings of these models, as well as creating frameworks that can explain their outputs in human-understandable terms. However, achieving a balance between model complexity and interpretability remains a significant challenge.
Additionally, LLMs are susceptible to generating incorrect or nonsensical information, a phenomenon known as "hallucination." This issue arises because the models predict the next word based on patterns learned during training, without a true understanding of the content. As a result, they can produce plausible-sounding but factually incorrect statements, posing risks in applications where accuracy is paramount.
To mitigate hallucinations, researchers are exploring methods such as incorporating external knowledge sources, implementing stricter output validation, and refining training processes to enhance factual accuracy.
In summary, while Large Language Models offer powerful capabilities, they also present significant challenges related to bias, resource demands, and interpretability. Addressing these issues is crucial for the responsible and effective deployment of LLMs across various sectors. Ongoing research and development are essential to overcome these challenges, ensuring that LLMs can be utilized in a manner that is both ethical and beneficial to society.
Introduction
Large Language Models (LLMs) are a class of advanced artificial intelligence systems designed to comprehend and generate human-like text. They achieve this by processing extensive datasets, enabling them to perform a wide array of natural language processing tasks with remarkable proficiency. LLMs utilize deep learning architectures, particularly transformer models, to capture the intricate patterns and structures inherent in human language.
The foundational architecture of LLMs is the transformer model, which employs self-attention mechanisms to process input data. This design allows the model to weigh the importance of different words in a sentence, regardless of their position, thereby capturing long-range dependencies and contextual information. The self-attention mechanism computes attention scores for each word in relation to others, enabling the model to focus on relevant parts of the input when generating or interpreting text.
During the training phase, LLMs are exposed to vast amounts of text data, learning to predict the probability of a word or sequence of words following a given context. This process allows the model to understand and generate text that is contextually relevant and coherent. The extensive training on diverse datasets enables LLMs to generalize across various language tasks, making them versatile tools for applications such as text generation, translation, summarization, and question-answering.
Once trained, LLMs can generate contextually relevant responses to a wide range of prompts. When a user inputs a query or statement, the model processes the input by encoding it into a numerical representation, which captures the semantic meaning of the text. It then decodes this representation to produce a response, drawing upon the patterns and information it learned during training. The model's ability to generate coherent and contextually appropriate text is a direct result of its exposure to diverse linguistic structures and contexts during the training phase.
The versatility of LLMs is further enhanced by their capacity to perform tasks beyond simple text generation. They can engage in complex dialogues, translate languages, summarize lengthy documents, and even generate code snippets, demonstrating their broad applicability across various domains. This adaptability is a testament to the depth of their training and the robustness of the transformer architecture.
However, the operation of LLMs is not without challenges. The models are sensitive to the quality and diversity of the training data; biases present in the data can be learned and perpetuated by the model, leading to biased outputs. Additionally, the vast number of parameters in LLMs makes them computationally intensive, requiring significant resources for both training and deployment. Despite these challenges, ongoing research and development continue to refine LLMs, enhancing their performance and mitigating issues related to bias and resource consumption.
In summary, Large Language Models function by processing extensive textual data through deep learning architectures, particularly transformers, to understand and generate human-like text. Their ability to learn from diverse datasets enables them to perform a wide array of language-related tasks, making them powerful tools in the field of artificial intelligence.
Large Language Models (LLMs) have become integral to numerous sectors, significantly enhancing efficiency, accuracy, and accessibility across various applications. Their ability to understand and generate human-like text has led to transformative changes in fields such as natural language processing, content generation, and customer service.
In natural language processing (NLP), LLMs have revolutionized tasks like sentiment analysis, language translation, and information extraction. By comprehending the context and nuances of human language, these models enable machines to interpret and respond to text inputs with remarkable accuracy. This advancement has facilitated more sophisticated interactions between humans and machines, allowing for a deeper understanding of textual data. For instance, LLMs can analyze customer feedback to gauge sentiment, providing businesses with valuable insights into consumer perceptions.
In content generation, LLMs assist in drafting articles, reports, and creative pieces, enabling professionals to produce high-quality content more efficiently. By providing initial drafts or suggesting edits, LLMs streamline the content creation process, allowing human creators to focus on strategic and creative aspects. This capability has been particularly beneficial in industries where content volume and speed are critical. For example, LLMs can generate product descriptions for e-commerce platforms, saving time and ensuring consistency across listings.
In customer service, LLMs have transformed traditional service models by powering chatbots and virtual assistants. These AI-driven systems can handle a wide range of customer inquiries, providing timely and accurate responses. By understanding context and analyzing sentiment, LLMs offer personalized support, enhancing customer satisfaction and operational efficiency. This advancement has enabled businesses to offer 24/7 support without extensive human resources, ensuring a seamless support experience. For instance, LLMs can manage routine customer queries, allowing human agents to focus on more complex issues.
Beyond these applications, LLMs are also utilized in areas such as code generation, where they assist developers by suggesting code snippets or debugging existing code. This functionality accelerates the development process and reduces the likelihood of errors. Additionally, LLMs are employed in legal document analysis, helping legal professionals review and interpret complex documents more efficiently. Their ability to process and understand large volumes of text makes them valuable tools in research and data analysis across various fields.
The integration of LLMs into these domains has not only improved efficiency but also opened new possibilities for innovation and service delivery. As technology continues to evolve, the potential applications of LLMs are expected to expand, further integrating AI into everyday life and business operations. Their versatility and adaptability make them powerful tools in addressing complex challenges and enhancing human capabilities across diverse sectors.
The Architecture of Large Language Models
Large Language Models (LLMs) have revolutionized the field of artificial intelligence, particularly in natural language processing (NLP), by leveraging the transformer architecture. Introduced in the seminal 2017 paper "Attention is All You Need" by Vaswani et al., the transformer model has become the foundational architecture for many state-of-the-art NLP systems.
The transformer architecture is designed to process and generate human-like text for a wide range of tasks, from machine translation to general-purpose text generation.
At its core, the transformer model consists of two primary components: the encoder and the decoder. The encoder reads and processes the input text, transforming it into a format that the model can understand. Imagine it as absorbing a sentence and breaking it down into its essence. On the other side, the decoder takes this processed information and steps through it to produce the output, like translating the sentence into another language.
A key feature of the transformer architecture is its use of self-attention mechanisms. This mechanism allows the model to weigh the importance of different words in a sentence, regardless of their position, thereby capturing long-range dependencies and contextual information. The self-attention mechanism computes attention scores for each word in relation to others, enabling the model to focus on relevant parts of the input when generating or interpreting text.
The transformer model processes data in parallel, unlike its predecessors, which processed data sequentially. This parallel processing capability significantly reduces training times and enhances the model's ability to handle long-range dependencies in text. By processing entire sequences simultaneously, transformers can capture complex patterns and relationships within the data more effectively.
The encoder-decoder structure of the transformer allows it to perform a variety of tasks. For instance, in machine translation, the encoder processes the input sentence in one language, and the decoder generates the corresponding sentence in another language. In text generation, the encoder processes the input prompt, and the decoder generates a continuation of the text. This versatility makes the transformer architecture highly adaptable to various NLP applications.
The transformer architecture has been instrumental in the development of large language models, enabling them to achieve state-of-the-art performance across a wide range of NLP tasks. Its ability to capture complex patterns and relationships in text data has made it the architecture of choice for many modern AI systems.
In summary, the transformer architecture, with its encoder-decoder structure and self-attention mechanisms, has been pivotal in advancing the capabilities of large language models. Its design allows for efficient processing of text data, capturing long-range dependencies, and enabling the generation of human-like text across various applications.
Components of Transformers
Tokenization is a fundamental process in natural language processing (NLP) that involves converting text into smaller units called tokens. These tokens can be words, subwords, or characters, depending on the tokenization strategy employed. The primary purpose of tokenization is to transform raw text into a format that can be effectively processed by language models, such as Large Language Models (LLMs). By breaking down text into manageable units, tokenization simplifies the complexities of human language, enabling models to analyze and generate text more efficiently.
In the context of LLMs, tokenization serves as the initial step in text processing. Before any analysis or generation can occur, the text must be converted into tokens that the model can understand. This process involves several key steps:
Text Preprocessing: The raw text is first cleaned to remove any irrelevant characters, such as extra spaces, special symbols, or formatting issues. This step ensures that the text is standardized and ready for tokenization.
Segmentation: The cleaned text is then divided into smaller units. Depending on the tokenization strategy, these units can be words, subwords, or characters. For example, the sentence "Hello, world!" can be tokenized into ["Hello", ",", "world", "!"].
Mapping to Numerical Representations: Each token is assigned a unique identifier or index from a predefined vocabulary. This mapping transforms the tokens into numerical representations, which are essential for the model's processing.
The choice of tokenization strategy significantly impacts the performance of LLMs. Word-level tokenization treats each word as a separate token, which can be straightforward but may struggle with out-of-vocabulary words. Subword tokenization, on the other hand, breaks words into smaller units, allowing the model to handle rare or unseen words more effectively. Character-level tokenization treats each character as a token, which can be useful for languages with complex morphology but may result in longer sequences. The selection of an appropriate tokenization strategy depends on the specific requirements of the NLP task and the characteristics of the language being processed.
After tokenization, the sequence of tokens is ready to be fed into the LLM. The model processes these tokens to understand the underlying patterns and structures of the language, enabling it to perform tasks such as text generation, translation, summarization, and more. The effectiveness of tokenization directly influences the model's ability to comprehend and generate human-like text.
In summary, tokenization is a crucial step in preparing text for processing by LLMs. By converting raw text into tokens, it enables models to handle the complexities of human language, facilitating a wide range of NLP applications.
In large language models (LLMs), embedding layers play a crucial role in transforming tokens into continuous vector representations, enabling the model to process and understand textual data effectively. These embeddings capture the semantic meaning of words or subwords, allowing the model to discern relationships and contextual nuances within the language.
The process begins with tokenization, where text is divided into smaller units such as words or subwords. Each token is then mapped to a unique identifier from a predefined vocabulary. The embedding layer takes these identifiers and converts them into dense, high-dimensional vectors. These vectors are learned during the training phase, with the model adjusting them to minimize the loss function, thereby refining the embeddings to better capture the semantic relationships between tokens. This learning process enables the model to understand that words with similar meanings are represented by vectors that are close to each other in the embedding space.
The dimensionality of these embedding vectors is a critical factor in the model's performance. Higher-dimensional embeddings can capture more complex relationships but may also introduce computational challenges and the risk of overfitting. Conversely, lower-dimensional embeddings are computationally more efficient but might not capture the full richness of the language. Therefore, selecting an appropriate embedding size is essential for balancing performance and efficiency.
Embeddings are not static; they evolve during training as the model learns to represent words in a way that reflects their usage and context within the training data. This dynamic nature allows embeddings to adapt to various linguistic patterns, including synonyms, antonyms, and polysemy (words with multiple meanings). For instance, the words "king" and "queen" would have embeddings that are close to each other, reflecting their semantic similarity, while "king" and "car" would be farther apart. This relational positioning in the embedding space enables the model to perform tasks such as analogy reasoning and semantic similarity assessments.
The quality of embeddings directly influences the performance of downstream tasks. Well-trained embeddings facilitate better understanding and generation of text, leading to improved outcomes in applications like machine translation, sentiment analysis, and text summarization. Conversely, poorly trained embeddings can hinder the model's ability to grasp subtle linguistic nuances, resulting in suboptimal performance. Therefore, embedding layers are not merely a preprocessing step but a foundational component that significantly impacts the efficacy of LLMs.
In summary, embedding layers are integral to large language models, transforming discrete tokens into continuous vector representations that capture the semantic essence of language. Through the training process, these embeddings evolve to reflect the complex relationships and contextual meanings inherent in human language, enabling LLMs to perform a wide array of natural language processing tasks with remarkable proficiency.
In large language models (LLMs), attention mechanisms are pivotal in enabling the model to focus on specific parts of the input text, thereby capturing the intricate relationships and contextual nuances inherent in human language. These mechanisms allow the model to assign varying levels of importance to different tokens within a sequence, facilitating a more nuanced understanding and generation of text.
The concept of attention in neural networks was introduced to address the limitations of earlier architectures, such as recurrent neural networks (RNNs) and long short-term memory networks (LSTMs), which struggled with capturing long-range dependencies due to their sequential processing nature. Attention mechanisms, particularly the self-attention mechanism, revolutionized this by allowing models to process all tokens in a sequence simultaneously, with each token dynamically attending to all others. This parallel processing capability significantly enhances the model's ability to understand context and relationships within the text.
In practice, attention mechanisms compute a set of attention scores that determine the relevance of each token to every other token in the sequence. These scores are derived from the input embeddings and are used to weight the influence of each token when producing the output representation. The self-attention mechanism computes attention scores for each word in relation to others, enabling the model to focus on relevant parts of the input when generating or interpreting text.
The self-attention mechanism utilizes three key components: queries, keys, and values. Each token in the input sequence is transformed into these components through learned weight matrices. The attention score between two tokens is computed by taking the dot product of the query of one token with the key of another, followed by a scaling factor and a softmax operation to normalize the scores. These normalized scores are then used to weight the values, resulting in a weighted sum that represents the attended information for each token. This process allows the model to dynamically adjust its focus based on the input context, enabling it to capture complex relationships and dependencies within the text.
The ability of attention mechanisms to focus on relevant parts of the input text is particularly beneficial in tasks such as machine translation, where understanding the relationship between words in different languages is crucial. By assigning appropriate attention weights, the model can effectively align words and phrases across languages, leading to more accurate translations. Similarly, in text summarization, attention mechanisms enable the model to identify and focus on the most salient information, producing concise and informative summaries. In sentiment analysis, attention mechanisms help the model discern which parts of the text contribute most to the overall sentiment, enhancing its ability to accurately classify the sentiment of the text.
Despite their effectiveness, attention mechanisms can be computationally intensive, especially for long input sequences, as they involve computing pairwise similarities between all tokens, resulting in quadratic complexity with respect to sequence length. This can be computationally expensive, particularly for long sequences. Various techniques have been proposed to mitigate this computational complexity, such as sparse attention mechanisms, approximate attention methods, and efficient attention mechanisms like the Reformer model's locality-sensitive hashing.
In summary, attention mechanisms are fundamental to the operation of large language models, enabling them to focus on relevant parts of the input text and capture the complex relationships and contextual nuances inherent in human language. By dynamically adjusting their focus, these mechanisms enhance the model's ability to understand and generate text across a wide range of natural language processing tasks.
In large language models (LLMs), feedforward neural networks (FFNs) are integral components that process information through a series of transformations, enabling the model to capture complex patterns and relationships within the data. These networks consist of multiple layers of interconnected neurons, where each layer performs a specific function to transform the input data into a desired output.
The architecture of an FFN typically includes an input layer, one or more hidden layers, and an output layer. Each neuron in a layer is connected to every neuron in the subsequent layer, forming a fully connected structure. Information flows through these connections in a unidirectional manner, from the input to the output, without any feedback loops. This design allows FFNs to model complex, non-linear relationships between inputs and outputs.
In the context of LLMs, FFNs are employed within the transformer architecture, which underlies many state-of-the-art language models. Within this framework, FFNs are applied to the output of the attention mechanism, serving to further process and refine the information. The transformer model consists of multiple layers, each containing a multi-head self-attention mechanism followed by an FFN. This structure enables the model to capture both local and global dependencies within the input text.
The processing of information through FFNs in LLMs involves several key steps:
Input Transformation: The output from the attention mechanism, which is a set of contextually enriched embeddings, serves as the input to the FFN. These embeddings represent the input text in a high-dimensional space, capturing semantic and syntactic information.
Linear Transformation: The input embeddings are first passed through a linear layer, which applies a weight matrix to transform the input into a new space. This transformation allows the model to learn complex representations of the input data.
Activation Function: Following the linear transformation, an activation function, such as the Rectified Linear Unit (ReLU), is applied element-wise to introduce non-linearity into the model. This non-linearity enables the FFN to model complex, non-linear relationships within the data.
Output Transformation: The activated output is then passed through another linear layer, which projects the data back to the original embedding space. This step ensures that the output dimensions are consistent with the input dimensions, maintaining the integrity of the data flow through the network.
Residual Connection: To facilitate training and improve performance, a residual connection is often employed, where the original input to the FFN is added to the output of the FFN before being passed to the next layer. This addition helps in mitigating issues like vanishing gradients and allows for more efficient training.
The role of FFNs in LLMs is to further process the information after it has been enriched by the attention mechanism. While attention mechanisms allow the model to focus on relevant parts of the input text, FFNs enable the model to learn complex, non-linear transformations of the data, capturing intricate patterns and relationships. This combination of attention and feedforward processing allows LLMs to achieve high performance across a wide range of natural language processing tasks.
It's important to note that the design and configuration of FFNs can significantly impact the performance of LLMs. Factors such as the number of layers, the size of each layer, the choice of activation functions, and the presence of regularization techniques can all influence how effectively the FFNs process information. Ongoing research continues to explore and optimize these aspects to enhance the capabilities of LLMs.
In summary, feedforward neural networks are essential components of large language models, processing information through a series of linear transformations and non-linear activations. By learning complex representations of the input data, FFNs enable LLMs to capture the rich, nuanced patterns inherent in human language, facilitating tasks such as text generation, translation, and summarization.
Training Large Language Models
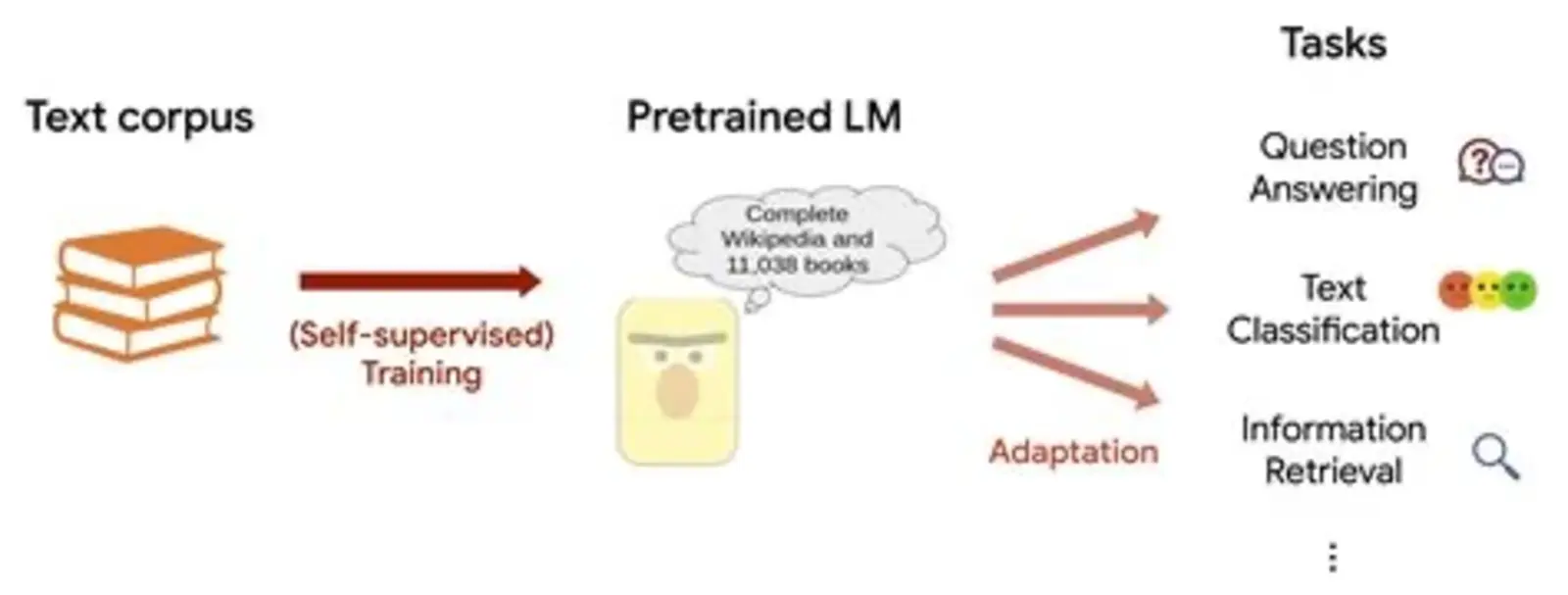
Large Language Models (LLMs) are sophisticated artificial intelligence systems that have revolutionized natural language processing by understanding and generating human-like text. The effectiveness of these models is largely attributed to the extensive and diverse datasets used during their training phases. These datasets encompass a wide array of textual data sources, including books, articles, websites, and other publicly available content, which collectively provide the foundational knowledge that enables LLMs to perform a multitude of language-related tasks.
The training process of LLMs involves the ingestion of vast amounts of text data, allowing the models to learn the intricacies of language, such as grammar, syntax, semantics, and contextual relationships between words and phrases. This comprehensive exposure to diverse linguistic patterns equips LLMs with the capability to generate coherent and contextually relevant text based on the input they receive.
One of the primary sources of training data for LLMs is the Common Crawl dataset. This dataset comprises terabytes of raw web data extracted from billions of web pages, providing a broad spectrum of information across various domains. The Common Crawl dataset is updated monthly, ensuring that the models trained on it have access to the most current information available on the internet. Several large language models, including GPT-3, LLaMA, OpenLLaMa, and T5, have been trained using the Common Crawl dataset, benefiting from its extensive and diverse content.
Another significant dataset is the Colossal Clean Crawled Corpus (C4), which is a 750 GB English corpus derived from the Common Crawl. C4 employs heuristic methods to extract only natural language data while removing all gibberish text, and it has undergone heavy deduplication to improve its quality. Language models like MPT-7B and T5 have been pre-trained with C4, utilizing its refined content to enhance their language understanding capabilities.
The Pile is another notable dataset, consisting of 825 GiB of English text curated from 22 diverse high-quality subsets, including academic papers, books, and web content. This diversity enables models trained on The Pile to develop a more generalized understanding of language, improving their performance across various tasks.
In addition to these, specialized datasets like BookCorpus, which contains 985 million words from 11,000 unpublished books, and ROOTS, a 1.6 TB multilingual dataset curated from text in 59 languages, have been utilized to train models for specific applications, such as understanding literary styles or multilingual language processing.
The process of collecting and preparing these datasets is meticulous and involves several key steps to ensure the quality and relevance of the data:
Data Collection: Gathering large-scale textual data from diverse sources to ensure a varied data distribution.
Data Cleaning: Removing irrelevant and incomplete information, duplicates, and inappropriate content to maintain the integrity of the dataset.
Data Normalization: Standardizing the text to a consistent format, which may include converting all text to lowercase, removing special characters, and correcting spelling errors.
Tokenization: Breaking down the text into manageable units, such as words, subwords, or characters, to create a token set suitable for model training.
Data Augmentation: Applying techniques to artificially expand the dataset, such as paraphrasing sentences or translating text into different languages, to enhance the model's robustness.
The quality and diversity of the training data are crucial factors that influence the performance of LLMs. A well-curated dataset enables the model to learn a wide range of linguistic patterns and contextual nuances, leading to more accurate and coherent text generation. Conversely, biases or gaps in the training data can result in models that produce skewed or incomplete outputs.
In recent developments, Harvard University, in collaboration with Microsoft and OpenAI, has announced the release of a free, high-quality dataset comprising nearly one million public-domain books. This initiative aims to democratize access to refined content for AI training, providing a valuable resource for researchers and developers in the AI community.
The continuous expansion and refinement of these datasets are essential for advancing the capabilities of LLMs. As AI technology progresses, there is an increasing need for diverse and high-quality data to train models that can understand and generate human-like text across various domains and languages. Efforts are ongoing to develop new datasets and improve existing ones, ensuring that LLMs can effectively handle the complexities of human language.
In summary, the vast and diverse datasets used for training Large Language Models are fundamental to their ability to understand and generate human-like text. Through meticulous collection, cleaning, and processing of textual data from a wide array of sources, these models acquire the knowledge necessary to perform a multitude of language-related tasks with remarkable proficiency.
Training Large Language Models (LLMs) involves a meticulous and resource-intensive process aimed at enabling these models to understand and generate human-like text. The core objective is to equip the model with the ability to predict subsequent words in a sequence, thereby capturing the intricate patterns and structures inherent in human language.
The training process commences with the preparation of extensive and diverse datasets. These datasets are meticulously curated to encompass a wide array of textual data, including books, articles, websites, and other publicly available content. The diversity and quality of the data are paramount, as they directly influence the model's capacity to generalize across various linguistic contexts. For instance, Harvard University, in collaboration with Microsoft and OpenAI, has released a free, high-quality dataset comprising nearly one million public-domain books. This initiative aims to democratize access to refined content for AI training, providing a valuable resource for researchers and developers in the AI community.
Once the dataset is assembled, it undergoes a rigorous preprocessing phase. This phase involves cleaning the data to remove any irrelevant, incomplete, or duplicate information, ensuring that the model is trained on high-quality content. Additionally, the text is tokenized, a process that breaks down the text into manageable units such as words, subwords, or characters. Tokenization is a critical step, as it transforms the raw text into a format that the model can process effectively.
With the data prepared, the training phase begins. LLMs are typically trained using unsupervised learning techniques, where the model learns to predict the next word in a sequence based on the preceding context. This approach allows the model to learn the statistical properties of language, including grammar, syntax, and semantics, without explicit labeling of the data. The model's parameters are adjusted iteratively through backpropagation, a method that updates the model's weights to minimize the difference between the predicted and actual next words. This process involves the computation of gradients, which indicate the direction and magnitude of changes needed in the model's parameters to reduce prediction errors.
The training process is computationally intensive and requires substantial hardware resources, including high-performance GPUs or TPUs. The duration of training can vary significantly, ranging from several weeks to months, depending on factors such as the size of the model, the volume of the dataset, and the computational power available. During this phase, the model is exposed to vast amounts of text data, allowing it to learn the nuances of language and develop a robust understanding of linguistic patterns.
After the initial training, the model undergoes fine-tuning on specific tasks or domains. Fine-tuning involves training the model on a smaller, task-specific dataset to adapt it to particular applications, such as sentiment analysis, machine translation, or question answering. This phase enhances the model's performance in specialized areas by focusing on examples relevant to those tasks. Fine-tuning is essential for tailoring the model's capabilities to meet the requirements of specific applications, ensuring that it can handle domain-specific language and nuances effectively.
Throughout the training process, various techniques are employed to enhance the model's performance and efficiency. Regularization methods, such as dropout, are used to prevent overfitting by randomly deactivating a subset of neurons during training, thereby promoting the development of more robust features. Additionally, optimization algorithms like Adam or SGD (Stochastic Gradient Descent) are utilized to adjust the model's parameters effectively, balancing the trade-off between convergence speed and stability. The choice of optimization algorithm can significantly impact the training dynamics and the final performance of the model.
The training of LLMs is an ongoing area of research, with continuous efforts to improve efficiency, reduce biases, and enhance the models' generalization capabilities. Innovations in training methodologies, such as the use of mixed-precision training to accelerate computation and reduce memory usage, are being explored to make the training process more accessible and cost-effective. Moreover, there is a growing emphasis on developing techniques to mitigate biases in training data, ensuring that the models produce fair and unbiased outputs.
In summary, the training of Large Language Models is a complex and resource-intensive process that involves the preparation of extensive datasets, rigorous preprocessing, and iterative learning to enable the model to predict subsequent words in a sequence. This process equips the model with the ability to understand and generate human-like text, facilitating a wide range of applications in natural language processing.
Fine-tuning Large Language Models (LLMs) is a pivotal process that enhances their performance for specific tasks or domains. While pre-trained LLMs possess a broad understanding of language, fine-tuning allows them to specialize in particular applications, thereby improving their accuracy and efficiency.
The fine-tuning process involves training a pre-trained LLM on a smaller, task-specific dataset. This dataset is typically labeled, providing the model with explicit examples of the desired output for given inputs. By adjusting the model's parameters during this phase, it learns to align its general language understanding with the specific requirements of the task at hand. This method enables the model to adapt to specialized language patterns, terminologies, and nuances inherent in the target domain.
For instance, in the field of sentiment analysis, a pre-trained LLM can be fine-tuned on a dataset containing product reviews labeled with sentiments such as positive, negative, or neutral. Through this fine-tuning, the model becomes adept at discerning the sentiment expressed in new, unseen reviews. Similarly, in legal document analysis, fine-tuning allows the model to comprehend and process legal jargon, enabling it to perform tasks like contract review or legal research more effectively.
The fine-tuning process is typically supervised, meaning the model learns from labeled data. However, there are also unsupervised and semi-supervised approaches where the model learns from unlabeled data or a combination of labeled and unlabeled data. The choice of approach depends on the availability of labeled data and the specific requirements of the task.
One of the key advantages of fine-tuning is its efficiency. Instead of training a model from scratch, which is computationally expensive and time-consuming, fine-tuning leverages the knowledge embedded in the pre-trained model. This approach significantly reduces the resources required for training and allows for quicker adaptation to new tasks. Moreover, fine-tuning can be performed with relatively smaller datasets, making it accessible for applications where large labeled datasets are not available.
However, fine-tuning also presents certain challenges. One notable issue is the risk of overfitting, where the model becomes too specialized to the fine-tuning dataset and loses its generalization capabilities. To mitigate this, techniques such as regularization, early stopping, and cross-validation are employed. Additionally, there is the concern of catastrophic forgetting, where the model forgets previously learned information when fine-tuned on new tasks. Strategies like progressive training and multi-task learning are used to address this issue.
In recent years, there has been a growing interest in parameter-efficient fine-tuning methods. These methods aim to fine-tune only a subset of the model's parameters, thereby reducing computational costs and mitigating issues like catastrophic forgetting. Techniques such as Low-Rank Adaptation (LoRA) and BitFit have been developed to achieve this goal. For example, LoRA introduces low-rank matrices into the model's architecture, allowing for efficient adaptation with fewer parameters. Similarly, BitFit focuses on fine-tuning only the bias terms of the model, which has been shown to be effective in certain scenarios.
The effectiveness of fine-tuning is also influenced by the quality and representativeness of the fine-tuning dataset. A well-curated dataset that accurately reflects the target domain is crucial for achieving optimal performance. Moreover, the size of the fine-tuning dataset plays a significant role; while fine-tuning can be performed with smaller datasets compared to training from scratch, having a sufficiently large and diverse dataset can lead to better generalization and performance.
In practice, fine-tuning has been successfully applied across various domains. In healthcare, LLMs have been fine-tuned to assist in medical diagnosis by analyzing patient records and medical literature. In finance, they have been adapted to predict market trends and analyze financial reports. The versatility of fine-tuning makes it a powerful tool for customizing LLMs to meet the specific needs of different industries and applications.
In summary, fine-tuning is a critical process that enhances the capabilities of Large Language Models by adapting them to specific tasks or domains. Through careful training on task-specific datasets, LLMs can achieve high performance in specialized applications, making them invaluable tools across various fields.
Capabilities and Applications
Large Language Models (LLMs) have revolutionized the field of natural language processing by enabling machines to generate coherent and contextually relevant text. This capability has profound implications across various domains, including content creation, customer service, and education.
The process of text generation in LLMs is fundamentally based on their training to predict the next word or token in a sequence. By analyzing vast amounts of text data, these models learn the statistical relationships between words, allowing them to generate text that mirrors human language patterns. This predictive ability is harnessed through autoregressive decoding, where the model generates one token at a time, with each new token depending on all the previous tokens in the sequence. This method ensures that the generated text maintains coherence and relevance to the input prompt.
To enhance the quality and relevance of the generated text, various decoding strategies are employed. Techniques such as temperature sampling, top-k sampling, and nucleus sampling (top-p sampling) are commonly used to introduce diversity and creativity into the outputs. Temperature sampling adjusts the probability distribution of the next token, with higher temperatures leading to more random outputs and lower temperatures resulting in more deterministic text. Top-k sampling limits the selection of the next token to the top 'k' most probable options, while nucleus sampling considers the smallest set of tokens whose cumulative probability exceeds a certain threshold 'p'. These strategies allow for a balance between creativity and coherence in the generated text.
In practical applications, LLMs are utilized for a wide range of text generation tasks. In content creation, they assist in drafting articles, composing poetry, and generating creative writing pieces. In customer service, LLMs power chatbots and virtual assistants, providing users with prompt and contextually appropriate responses. In education, they are employed to generate personalized learning materials and assist in language translation. The versatility of LLMs in generating human-like text has made them invaluable tools across various industries.
Despite their impressive capabilities, LLMs face challenges in text generation. Ensuring the factual accuracy of the generated text is a significant concern, as these models may produce plausible-sounding but incorrect or nonsensical information. Additionally, controlling the style and tone of the generated text to align with specific requirements remains a complex task. Ongoing research is focused on addressing these challenges by developing methods to improve the factual accuracy and controllability of LLM-generated text.
In summary, Large Language Models have transformed text generation by enabling machines to produce coherent and contextually relevant text. Their applications span various fields, and ongoing advancements continue to enhance their capabilities and address existing challenges.
Large Language Models (LLMs) have significantly advanced the fields of machine translation and text summarization, enabling machines to comprehend and generate human-like text across various languages and contexts. Their ability to translate languages and summarize content effectively has transformed numerous applications, from facilitating cross-cultural communication to enhancing information accessibility.
In machine translation, LLMs are trained by exposing them to input sequences in a source language alongside their corresponding translations in a target language. This training process allows the models to learn the complex relationships between languages, including syntax, semantics, and cultural nuances. By leveraging this knowledge, LLMs can produce translations that are not only accurate but also contextually appropriate, capturing the subtleties of the original text. Recent studies have demonstrated the effectiveness of LLM-based translation systems, showcasing their superiority over traditional methods in translating historical languages into modern ones.
In the realm of text summarization, LLMs excel at condensing large volumes of information into concise, coherent summaries. They achieve this by identifying and retaining the most pertinent information, effectively reducing redundancy and focusing on key points. This capability is particularly valuable in scenarios where quick comprehension of extensive content is necessary, such as summarizing lengthy documents, articles, or reports. The performance of LLMs in summarization tasks has been evaluated using various metrics, highlighting their proficiency in generating summaries that balance informativeness and conciseness.
The integration of LLMs into translation and summarization tasks has led to the development of context-aware systems that enhance the quality of outputs. By considering the broader context of the text, these systems can produce translations and summaries that are more accurate and relevant. For instance, in customer support scenarios, LLMs can utilize conversation history to provide translations that are sensitive to the ongoing dialogue, thereby improving user experience.
Despite their impressive capabilities, LLMs face challenges in translation and summarization tasks. Ensuring the factual accuracy of the generated text is a significant concern, as these models may produce plausible-sounding but incorrect or nonsensical information. Additionally, controlling the style and tone of the generated text to align with specific requirements remains a complex task. Ongoing research is focused on addressing these challenges by developing methods to improve the factual accuracy and controllability of LLM-generated text.
In summary, Large Language Models have transformed the fields of machine translation and text summarization by enabling machines to comprehend and generate human-like text across various languages and contexts. Their applications span numerous domains, and ongoing advancements continue to enhance their capabilities and address existing challenges.
Large Language Models (LLMs) have significantly advanced the development of conversational agents, including chatbots and virtual assistants, by enabling more natural and contextually relevant interactions. Traditional chatbots often relied on predefined scripts and rule-based systems, which limited their ability to handle the complexity and variability of human language. LLMs, however, have transformed this landscape by providing a deeper understanding of language nuances, allowing for more dynamic and human-like conversations.
In the realm of chatbots, LLMs have enhanced the ability to understand and generate human-like text responses. Unlike traditional chatbots that rely on predefined scripts, LLMs can generate responses based on the context of the conversation, making interactions more fluid and engaging. This capability has been particularly beneficial in customer service, where chatbots powered by LLMs can handle a wide range of inquiries, providing users with prompt and accurate information. For instance, AI-powered shopping assistants are now guiding consumers through their holiday shopping, helping create shopping lists, compare products, and track prices. These AI recommendations have led to a significant increase in consumer engagement, with a 2,000% rise in traffic from AI tools on Cyber Monday.
Virtual assistants have also benefited from the integration of LLMs, enabling them to perform more complex tasks and understand user intent with greater accuracy. LLMs have enhanced the capabilities of virtual assistants by enabling them to comprehend and execute multi-step instructions, making them more effective in assisting users with a variety of tasks. For example, intelligent virtual assistants powered by LLMs can automatically perform multi-step operations within mobile apps based on high-level user requests, representing a significant advancement in virtual assistant technology.
The integration of LLMs into conversational agents has also led to the development of more personalized and context-aware interactions. By analyzing user inputs and maintaining context throughout a conversation, LLM-powered chatbots and virtual assistants can provide responses that are tailored to individual user needs and preferences. This personalization enhances user satisfaction and engagement, as users feel that the system understands and responds to their specific requirements.
Despite the advancements brought about by LLMs, challenges remain in ensuring the accuracy and reliability of responses generated by conversational agents. Issues such as hallucinations, where the model generates plausible but incorrect information, and the need for continuous learning to adapt to new information are areas of ongoing research. Addressing these challenges is crucial for the continued evolution of conversational agents and their integration into various applications.
Large Language Models (LLMs) have significantly transformed the field of software development by enhancing code generation capabilities. These models, trained on extensive code datasets, can understand natural language descriptions and generate corresponding code snippets, thereby streamlining the development process and improving productivity.
The integration of LLMs into code generation has led to the creation of tools that assist developers in various tasks, including code completion, error detection, and refactoring. By analyzing the context and intent behind a developer's input, these models can suggest relevant code snippets, identify potential errors, and recommend optimizations. This assistance not only accelerates the coding process but also helps in maintaining code quality and consistency.
One notable example of LLMs in code generation is GitHub Copilot, an AI-powered code completion tool that leverages models from OpenAI, Google, and Anthropic. GitHub has introduced multi-model support for Copilot, allowing developers to choose the model that best fits their coding tasks. This flexibility enhances the tool's effectiveness across different programming languages and development environments.
Another significant development is Meta's Code Llama, a state-of-the-art LLM designed specifically for code generation. Built on top of Llama 2, Code Llama is available in three models: the foundational Code Llama, Code Llama - Python specialized for Python, and Code Llama - Instruct, which is fine-tuned for understanding natural language instructions. This specialization enables Code Llama to generate code and natural language descriptions from both code and natural language prompts, facilitating tasks such as code completion and debugging.
The application of LLMs in code generation has also been explored in academic research. A comprehensive survey published in June 2024 examines the advancements in LLMs for code generation, discussing aspects such as data curation, performance evaluation, and real-world applications. The study highlights the progressive enhancements in LLM capabilities for code generation and identifies critical challenges and promising opportunities in the field.
Despite the advancements, challenges remain in ensuring the accuracy and reliability of code generated by LLMs. Issues such as hallucinations, where the model generates plausible but incorrect information, and the need for continuous learning to adapt to new information are areas of ongoing research. Addressing these challenges is crucial for the continued evolution of code generation tools and their integration into various development workflows.
Challenges and Limitations
Large Language Models (LLMs) have revolutionized various fields by enabling machines to understand and generate human-like text. However, a significant concern arises regarding the biases inherent in these models, which often stem from the data used during their training. These biases can lead to outputs that perpetuate stereotypes, misinformation, and unfair representations, posing ethical challenges in their deployment across diverse applications.
The training data for LLMs typically comprises vast amounts of text sourced from the internet, including books, articles, and websites. This data inherently reflects societal biases present in the real world, encompassing prejudices related to gender, race, ethnicity, and other social constructs. Consequently, LLMs can inadvertently learn and reproduce these biases, resulting in outputs that may reinforce existing stereotypes or propagate discriminatory content. For instance, studies have demonstrated that LLMs can exhibit gender biases, associating certain professions or attributes predominantly with one gender over another.
Addressing these biases is crucial to ensure fairness and ethical integrity in AI systems. Researchers have identified several strategies to mitigate bias in LLMs. One approach involves curating and preprocessing training data to remove or reduce biased content. This process includes identifying and eliminating text that perpetuates harmful stereotypes or misinformation. Additionally, implementing fairness-aware algorithms during the training phase can help adjust the model's learning process to minimize bias. Techniques such as adversarial training, where the model is exposed to examples designed to challenge biased behavior, have been explored to promote fairness. Moreover, post-training interventions, including fine-tuning the model on carefully selected datasets or applying bias correction algorithms, can further reduce biased outputs.
Despite these efforts, challenges persist in achieving complete fairness in LLMs. The complexity of human language and the subtlety of biases make it difficult to fully eliminate all forms of bias. Moreover, the dynamic nature of societal norms means that what is considered biased can evolve over time, necessitating continuous monitoring and updating of models. Additionally, the trade-off between model performance and fairness remains a topic of ongoing research, as some interventions to reduce bias may inadvertently affect the model's accuracy or utility.
In summary, while LLMs offer remarkable capabilities in natural language understanding and generation, addressing the biases inherent in these models is essential to ensure their ethical and fair application. Ongoing research and development are focused on creating methodologies to identify, mitigate, and monitor biases in LLMs, striving to build AI systems that are both powerful and equitable.
Large Language Models (LLMs) have revolutionized natural language processing by enabling machines to understand and generate human-like text. However, a significant challenge remains in interpreting how these models arrive at specific outputs. The complexity and scale of LLMs make it difficult to trace the decision-making process, raising concerns about transparency, trustworthiness, and accountability in AI systems.
LLMs, such as GPT-3 and GPT-4, consist of billions of parameters and are trained on vast datasets. This immense scale contributes to their impressive performance but also complicates the understanding of their internal workings. Unlike traditional models, where decision paths can be more straightforward, LLMs operate through intricate networks of interconnected nodes, making it challenging to pinpoint how specific inputs lead to particular outputs. This opacity is often referred to as the "black box" nature of LLMs.
The lack of interpretability in LLMs poses several critical issues. First, it hinders the ability to diagnose and correct errors. Without understanding the reasoning behind a model's output, it becomes difficult to identify and rectify mistakes, potentially leading to the propagation of misinformation or biased content. Second, it challenges the validation of model behavior, making it hard to ensure that LLMs align with ethical standards and societal norms. Third, the opacity of these models can erode user trust, as stakeholders may be hesitant to rely on AI systems whose decision-making processes are not transparent.
Researchers are actively exploring methods to enhance the interpretability of LLMs. One approach involves developing techniques to visualize and analyze the internal representations of these models. By examining the activations and weights within the network, researchers aim to uncover how LLMs process and represent information. However, this method faces challenges due to the high dimensionality and complexity of the models. Another strategy is to create surrogate models that approximate the behavior of LLMs in a more interpretable manner. These simplified models can provide insights into the decision-making processes of LLMs, though they may not capture all the nuances of the original models. Additionally, there is an effort to develop explainability frameworks that can generate human-readable explanations for the outputs of LLMs. These frameworks aim to bridge the gap between complex model behavior and user understanding.
Despite these efforts, achieving full interpretability remains a formidable challenge. The trade-off between model performance and transparency is a central concern. Simplifying models to enhance interpretability can sometimes lead to a loss in performance, as the intricate structures that contribute to high accuracy may be obscured. Moreover, the dynamic nature of LLMs, which can adapt and evolve based on new data, adds another layer of complexity to understanding their behavior.
Large Language Models (LLMs) have revolutionized natural language processing by enabling machines to understand and generate human-like text. However, the development and deployment of these models demand substantial computational resources, raising concerns about accessibility, environmental impact, and operational costs.
Training LLMs requires immense computational power. Models like GPT-3 and GPT-4 consist of billions of parameters and are trained on vast datasets, necessitating high-performance hardware such as Graphics Processing Units (GPUs) or specialized accelerators. The training process involves processing massive amounts of data through complex neural network architectures, which can take weeks or even months to complete, depending on the model's size and the computational resources available. This extensive training process consumes significant energy, contributing to high operational costs and environmental concerns.
The deployment of LLMs also presents challenges. Serving these models in real-time applications requires powerful infrastructure to handle the computational demands of inference. This includes maintaining low latency and high throughput to ensure responsive user experiences. Organizations must invest in robust hardware and efficient software frameworks to manage these requirements effectively. Additionally, deploying LLMs at scale can lead to increased energy consumption, raising concerns about the environmental impact of widespread AI adoption.
To address these challenges, researchers and practitioners are exploring various strategies to optimize the computational efficiency of LLMs. Techniques such as model pruning, quantization, and knowledge distillation aim to reduce the size and complexity of models without significantly compromising performance. For instance, quantization involves representing model weights with lower precision, thereby reducing memory usage and computational requirements. Similarly, knowledge distillation transfers knowledge from a large, complex model to a smaller, more efficient one, enabling faster inference with minimal loss in accuracy. These methods are part of ongoing efforts to make LLMs more accessible and sustainable.
Furthermore, advancements in hardware accelerators, such as specialized AI chips and optimized GPUs, are being developed to enhance the efficiency of LLM training and deployment. These hardware innovations aim to provide the necessary computational power while reducing energy consumption, thereby mitigating some of the environmental impacts associated with large-scale AI operations.
The Future of Large Language Models
Large Language Models (LLMs) have undergone significant advancements in recent years, with ongoing research focusing on enhancing their efficiency, reducing biases, and expanding their capabilities across various domains. These developments aim to address the challenges associated with LLMs, such as computational resource demands, interpretability, and ethical considerations.
One of the primary areas of research is improving the efficiency of LLMs. Earlier models required vast amounts of computational resources, making them less accessible and more expensive to train and deploy. Recent innovations have led to models that are not only more efficient but also faster and more cost-effective. For instance, advancements in model architecture and training techniques have resulted in LLMs that can perform complex tasks with reduced computational overhead, enabling broader applications and more sustainable AI practices.
Another significant focus is enhancing the reasoning and problem-solving capabilities of LLMs. Researchers are developing models that can better understand context, handle ambiguity, and perform multi-step reasoning. This includes integrating external knowledge sources and refining training methods to improve the models' ability to generate coherent and contextually relevant responses. Such advancements are crucial for applications requiring deep understanding and complex decision-making processes.
Addressing biases in LLMs is also a critical area of research. Studies have shown that LLMs can inadvertently learn and reproduce biases present in their training data, leading to outputs that may perpetuate stereotypes or misinformation. To mitigate these biases, researchers are exploring various strategies, including curating diverse and representative training datasets, implementing fairness-aware algorithms, and developing post-training interventions to adjust the models' outputs. These efforts aim to ensure that LLMs operate ethically and fairly across different applications.
Advancements in hardware and software are also contributing to the evolution of LLMs. The development of specialized AI chips and optimized GPUs has enhanced the computational efficiency of LLMs, enabling faster training and inference times. Additionally, software frameworks and libraries are being developed to facilitate the deployment and fine-tuning of LLMs, making them more accessible to a broader range of users and applications.
Large Language Models (LLMs) have made significant strides in artificial intelligence, and their future applications are poised to profoundly impact various sectors of society. As these models evolve, they are expected to enhance efficiency, foster innovation, and address complex challenges across multiple domains.
In the healthcare sector, LLMs are anticipated to revolutionize patient care and medical research. By analyzing extensive medical literature and patient records, these models can assist in diagnosing diseases, recommending personalized treatment plans, and predicting health outcomes. Their ability to process and synthesize vast amounts of medical data could lead to more accurate and timely interventions, potentially saving lives and reducing healthcare costs. Moreover, LLMs could expedite drug discovery by identifying potential compounds and predicting their efficacy, thereby accelerating the development of new medications.
In education, LLMs have the potential to transform learning experiences by providing personalized tutoring and support. They can adapt to individual learning styles and paces, offering tailored explanations and resources to enhance understanding. This personalized approach could make education more accessible and effective, catering to diverse learning needs. Additionally, LLMs could assist educators in developing curriculum materials and assessing student performance, streamlining administrative tasks and allowing more focus on teaching.
The manufacturing industry stands to benefit from LLMs by improving operational efficiency and innovation. These models can analyze production data to identify inefficiencies, predict maintenance needs, and optimize supply chains. By serving as conversational interfaces, LLMs can facilitate communication between human workers and machines, enabling more intuitive control and monitoring of manufacturing processes. This integration could lead to smarter factories and more sustainable production practices.
In the realm of social collaboration, LLMs are expected to enhance collective intelligence by facilitating information sharing and decision-making. They can process and summarize large volumes of data, providing insights that inform group discussions and strategies. However, it is crucial to ensure that LLMs support diverse perspectives and do not reinforce existing biases, as this could impact the quality of collaborative outcomes.
Despite these promising applications, the integration of LLMs into society raises several ethical and societal considerations. There are concerns about privacy, as LLMs process vast amounts of personal data, potentially leading to unauthorized access or misuse. Bias in training data can result in discriminatory outputs, perpetuating existing inequalities. Additionally, the potential for LLMs to generate misinformation poses risks to public trust and the integrity of information. Addressing these challenges requires the development of robust ethical guidelines, transparent AI practices, and continuous monitoring to ensure that LLMs are used responsibly and for the benefit of all.
Conclusion
Large Language Models (LLMs) have significantly advanced artificial intelligence, enabling machines to understand and generate human-like text. Their applications span various domains, including text generation, translation, summarization, conversational agents, and code generation. However, challenges such as biases, interpretability issues, and substantial computational resource requirements persist.
In text generation, LLMs produce coherent and contextually relevant content, facilitating tasks like content creation and dialogue systems. Their proficiency in translation and summarization has enhanced cross-lingual communication and information accessibility. As conversational agents, LLMs power chatbots and virtual assistants, providing human-like interactions across diverse industries. In code generation, they assist programmers by suggesting code snippets and debugging, streamlining the development process.
Despite these advancements, LLMs face challenges. Biases in training data can lead to biased outputs, raising ethical concerns. The complexity of LLMs makes it difficult to understand how they arrive at specific outputs, posing interpretability challenges. Additionally, training and deploying LLMs require significant computational resources, raising concerns about accessibility and environmental impact.
Ongoing research aims to address these challenges by enhancing efficiency, reducing biases, and improving interpretability. Advancements in hardware and software are also contributing to the evolution of LLMs, making them more accessible and sustainable. The future applications of LLMs hold transformative potential across various sectors, including healthcare, education, manufacturing, and social collaboration. However, it is imperative to address the ethical and societal challenges they present to ensure responsible and equitable integration into society.
Large Language Models (LLMs) have undergone remarkable advancements, and their future developments are poised to further transform various sectors. As these models evolve, they are expected to become more efficient, accessible, and integrated into diverse applications, offering both opportunities and challenges.
One significant area of development is the enhancement of multimodal capabilities. Models like Google's Gemini 2.0 Flash exemplify this trend, integrating functionalities such as image and audio generation alongside text processing. This evolution enables LLMs to handle a broader range of tasks, including content creation across different media formats and more sophisticated human-computer interactions.
Another promising direction is the improvement of efficiency and resource utilization. Researchers are exploring methods to reduce the computational demands of LLMs, making them more accessible and environmentally sustainable. Techniques such as model pruning, quantization, and knowledge distillation are being investigated to create smaller, more efficient models without compromising performance.
The integration of LLMs into specialized domains is also advancing. For instance, in the legal industry, firms are developing bespoke AI tools tailored to their specific needs, enabling more efficient document analysis and case preparation. This trend reflects a broader movement towards domain-specific AI applications, where LLMs are fine-tuned to understand and process specialized knowledge, enhancing their utility in fields such as medicine, finance, and engineering.
Despite these advancements, challenges remain. Addressing biases in training data is a critical concern, as biased models can perpetuate and amplify societal inequalities. Ongoing research aims to develop methods for detecting and mitigating biases, ensuring that LLMs operate fairly and ethically.
The future of LLMs also involves a shift towards more interactive and conversational AI systems. As these models become more adept at understanding and generating human-like text, they are expected to play a central role in enhancing user experiences across various platforms, from customer service chatbots to virtual assistants. This evolution could lead to more natural and intuitive human-computer interactions, transforming how we access information and services.
In summary, the future developments of Large Language Models are set to expand their capabilities, making them more efficient, versatile, and integrated into specialized applications. While challenges such as bias and resource consumption persist, ongoing research and innovation are paving the way for LLMs to become more accessible and impactful across various sectors.
Press contact
Timon Harz
oneboardhq@outlook.com
Other posts





Company
About
Blog
Careers
Press
Legal
Privacy
Terms
Security