Timon Harz
December 20, 2024
How AI Models Learn to Solve Problems That Humans Can’t
Discover how the Easy-to-Hard Generalization (E2H) framework is reshaping AI alignment by minimizing human supervision while enhancing model performance on complex tasks. This breakthrough methodology has the potential to drive the future of AI in diverse fields, from mathematics to coding.
Natural Language Processing (NLP) leverages large language models (LLMs) to power applications like language translation, sentiment analysis, speech recognition, and text summarization. While these models typically rely on human feedback-based supervised data, the growing complexity of tasks calls for a shift to unsupervised data as models surpass human capabilities. However, this shift brings about the challenge of alignment as models become more intricate. To address this, researchers from Carnegie Mellon University, Peking University, MIT-IBM Watson AI Lab, University of Cambridge, Max Planck Institute for Intelligent Systems, and UMass Amherst have developed the Easy-to-Hard Generalization (E2H) methodology, which tackles the alignment issue in complex tasks without relying on human feedback.
Traditional alignment methods heavily depend on supervised fine-tuning and Reinforcement Learning from Human Feedback (RLHF), which can be limiting as they scale. Collecting high-quality human feedback is costly and labor-intensive, and models struggle to generalize to new scenarios beyond learned behaviors. As a result, a new methodology that allows complex tasks to be tackled with minimal human supervision is urgently needed.
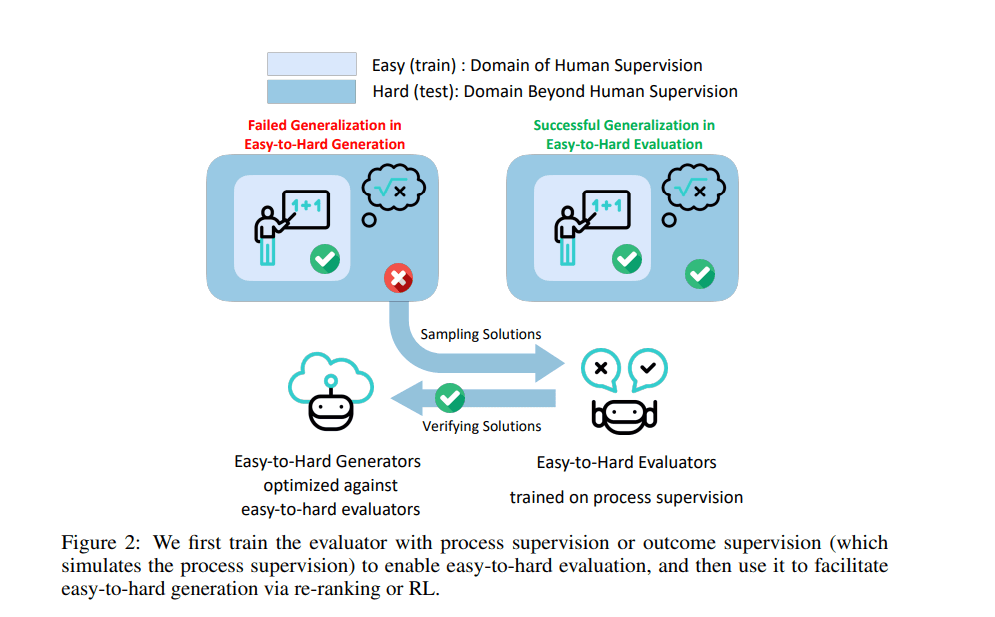
The proposed Easy-to-Hard Generalization approach uses a three-step process to enable scalable task generalization:
Process-Supervised Reward Models (PRMs): Models are first trained on simpler human-level tasks, and these models then evaluate and guide the AI's problem-solving on more complex tasks.
Easy-to-Hard Generalization: Models are gradually exposed to more difficult tasks, with predictions and evaluations from easier tasks helping guide the learning process.
Iterative Refinement: Models are fine-tuned based on feedback provided by the PRMs, improving their performance over time.
This iterative learning process reduces reliance on human feedback, enabling smoother generalization to tasks beyond what has been explicitly taught. The result is a methodology that optimizes AI performance in scenarios where human engagement becomes less feasible.
Performance comparisons show notable improvements on the MATH500 benchmark, where a 7 billion-parameter process-supervised RL model achieved 34.0% accuracy, while a 34 billion-parameter model reached 52.5% accuracy, using only human supervision for easier problems. The method also proved effective on the APPS coding benchmark, indicating that the approach can achieve alignment outcomes comparable to or even surpassing RLHF, while significantly reducing the need for human-labeled data in complex tasks.
This research addresses the critical challenge of AI alignment beyond human supervision with the introduction of an innovative Easy-to-Hard Generalization framework. The method shows promising results in enabling AI systems to handle progressively complex tasks while staying aligned with human values. Its strengths include a novel approach to scalable alignment, demonstrated effectiveness across diverse domains such as mathematics and coding, and the potential to overcome the limitations of current alignment techniques. However, further testing in real-world, diverse scenarios is required. Overall, this work represents a significant advancement toward AI systems that can safely and effectively operate without direct human oversight, opening the door to more advanced and aligned AI technologies.
Press contact
Timon Harz
oneboardhq@outlook.com
Other posts





Company
About
Blog
Careers
Press
Legal
Privacy
Terms
Security