Timon Harz
December 19, 2024
Google DeepMind's SALT: Machine Learning Approach for Efficient Training of High-Performing Large Language Models with SLMs
SALT introduces a novel way to optimize the training of large language models by leveraging smaller models, making AI more efficient and cost-effective. Discover how this approach could accelerate advancements across various industries, from healthcare to autonomous systems.

Large Language Models (LLMs) power a wide range of applications, including conversational agents, automated content creation, and natural language understanding tasks. Their strength lies in their ability to learn complex language patterns from massive datasets. However, creating LLMs is challenging due to the significant computational resources required for training. Optimizing models with billions of parameters across vast corpora demands extensive hardware and time. This creates a need for new training methods that can reduce these costs while preserving or improving model performance.
Traditional training methods for LLMs are inefficient because they treat all data uniformly, without distinguishing between simple and complex instances. These approaches do not focus on subsets of data that could speed up learning or utilize smaller models to assist in training larger ones. As a result, valuable computational resources are spent processing simple data in the same way as more complex data. Moreover, standard self-supervised learning methods, which typically involve predicting the next token in a sequence, fail to take advantage of smaller, less resource-intensive models that could guide the training of larger models more efficiently.
Knowledge distillation (KD) is typically used to transfer knowledge from large, well-trained models to smaller, more efficient ones. However, this process has rarely been reversed, where smaller models help train larger ones. This gap represents a missed opportunity, as smaller models, despite their limited capacity, can offer valuable insights into specific regions of the data. They are particularly good at identifying “easy” and “hard” instances, which can significantly influence the training of Large Language Models (LLMs).
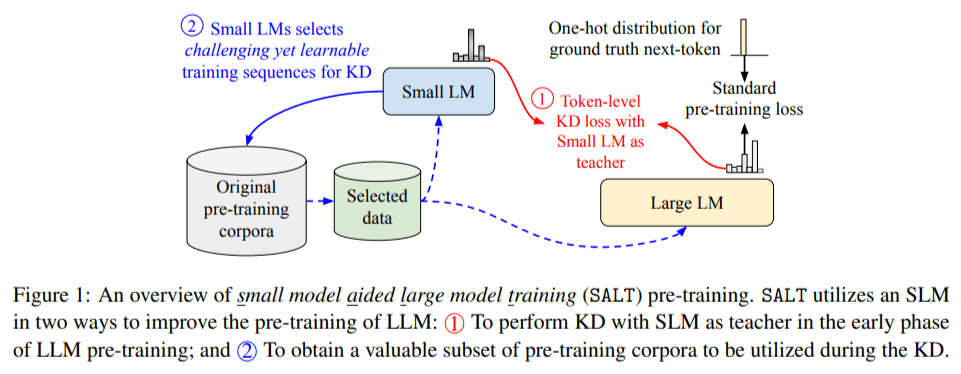
To address this gap, researchers at Google Research and Google DeepMind introduced a novel approach called Small model Aided Large model Training (SALT). SALT utilizes smaller language models (SLMs) to improve the efficiency of LLM training. It works in two key ways: first, by providing soft labels during the initial training phase as an additional source of supervision, and second, by selecting data subsets that are particularly valuable for learning. This ensures that LLMs are guided by SLMs to focus on the most informative and challenging data, reducing computational costs while enhancing the overall model quality.
SALT operates in two phases:
In the first phase, SLMs act as teachers, transferring their predictive distributions to LLMs via knowledge distillation. The LLM aligns its predictions with those of the SLM in areas where the smaller model excels. At the same time, the SLM identifies valuable subsets of data—both challenging and learnable—that the LLM can focus on early in training.
In the second phase, the process shifts to traditional self-supervised learning, where the LLM refines its understanding of more complex data distributions independently.
This two-phase approach balances the strengths of SLMs with the inherent capabilities of LLMs, improving both the efficiency and quality of model training.
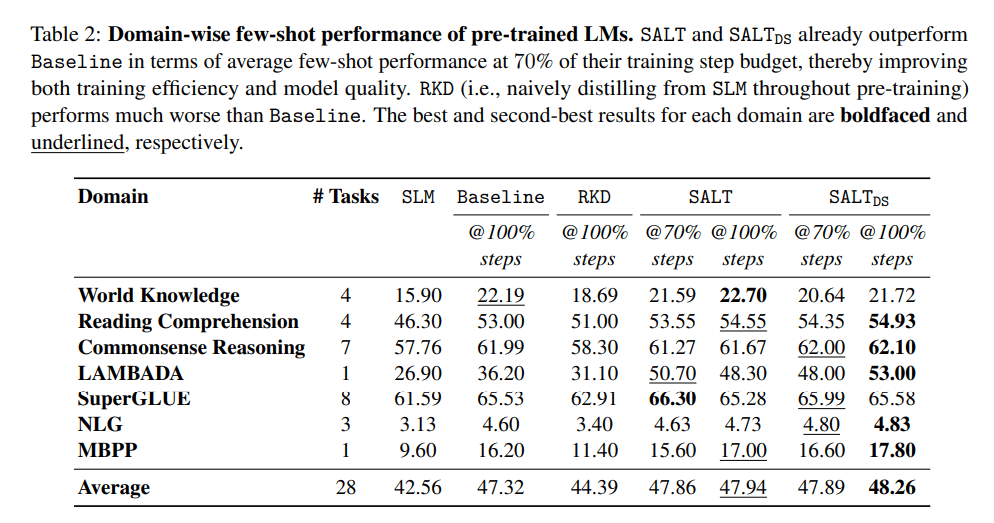
In experimental tests, a 2.8-billion-parameter LLM trained with SALT on the Pile dataset outperformed a baseline model trained with conventional methods. The SALT-trained model achieved superior results on benchmarks such as reading comprehension, commonsense reasoning, and natural language inference, all while using only 70% of the training steps. This led to a reduction of approximately 28% in wall-clock training time. Additionally, the LLM pre-trained with SALT achieved a 58.99% accuracy in next-token prediction, surpassing the baseline's 57.7%. It also demonstrated a lower log-perplexity of 1.868, compared to 1.951 for the baseline, reflecting improved model quality.
Key takeaways from the research include:
SALT reduced the computational costs of training LLMs by nearly 28%, mainly by using smaller models to guide the early training phases.
The approach consistently led to higher-performing LLMs across a range of tasks, including summarization, arithmetic reasoning, and natural language inference.
By allowing smaller models to select challenging but learnable data, SALT ensured that LLMs focused on high-value data points, speeding up learning without sacrificing quality.
This method is especially beneficial for organizations with limited computational resources, as it leverages smaller, more cost-effective models to support the development of large-scale LLMs.
Following supervised fine-tuning, the SALT-trained models demonstrated better generalization in few-shot evaluations and downstream tasks.
In conclusion, SALT reshapes the landscape of LLM training by turning smaller models into valuable training assets. Its innovative two-stage process strikes a unique balance between efficiency and effectiveness, positioning it as a groundbreaking approach in machine learning. SALT will play a key role in overcoming resource limitations, improving model performance, and making advanced AI technologies more accessible. This research highlights the need to rethink traditional methods and utilize existing tools to achieve greater results with fewer resources.
Large Language Models (LLMs) and Small Language Models (SLMs) are pivotal in the field of Natural Language Processing (NLP), each serving distinct roles in understanding and generating human language. LLMs, such as OpenAI's GPT series, are characterized by their vast number of parameters—often in the billions—enabling them to capture intricate patterns and relationships within language. This extensive training allows LLMs to perform a wide array of tasks, including text generation, translation, summarization, and question-answering, with a high degree of fluency and coherence. However, their large size necessitates substantial computational resources for both training and deployment, which can be a limiting factor in certain applications.
In contrast, Small Language Models (SLMs) are designed to be more compact and efficient. They typically have fewer parameters and are trained on smaller datasets, making them less resource-intensive. Despite their reduced size, SLMs can be highly effective for specific tasks, especially when fine-tuned on domain-specific data. Their efficiency makes them suitable for applications where computational resources are limited or where real-time processing is essential. For instance, SLMs are often employed in scenarios like document classification, sentiment analysis, and chatbots, where quick responses are crucial. Moreover, SLMs can be more cost-effective to train and deploy, offering a practical solution for businesses and organizations with limited resources.
The choice between LLMs and SLMs depends on the specific requirements of the task at hand. LLMs are preferable when the application demands a deep understanding of language and the ability to generate human-like text across a broad range of topics. However, for tasks that require efficiency, lower latency, and reduced computational overhead, SLMs present a compelling alternative. Recent advancements have also seen SLMs achieving performance levels that were once thought to be exclusive to larger models, further blurring the lines between the two categories. For example, Microsoft's Phi-2 model has demonstrated that smaller models can outperform larger ones in specific tasks, such as mathematics and coding, highlighting the potential of SLMs in specialized domains.
In summary, both LLMs and SLMs play crucial roles in NLP, each with its own set of advantages and trade-offs. Understanding the distinctions between them allows researchers and practitioners to select the most appropriate model based on the specific demands of their applications, balancing factors like performance, resource consumption, and task specificity.
Training high-performing Large Language Models (LLMs) is a complex endeavor that involves navigating a multitude of challenges, each contributing to the overall difficulty of the process. These challenges span from the acquisition and preparation of vast datasets to the substantial computational resources required, as well as the intricacies of model architecture and the necessity for specialized expertise.
One of the primary challenges in training LLMs is the acquisition and preparation of large, high-quality datasets. The success of an LLM is heavily dependent on the quality and diversity of the data it is trained on. Gathering such extensive datasets is not only time-consuming but also requires meticulous curation to ensure that the data is representative and free from biases. Moreover, the data must be preprocessed to remove noise and inconsistencies, a task that demands significant human oversight and computational power. The importance of accurate and updated data cannot be overstated, as it directly influences the model's ability to generalize and perform effectively across various tasks.
The computational demands of training LLMs present another significant hurdle. These models often contain billions of parameters, necessitating the use of advanced hardware such as Graphics Processing Units (GPUs) or specialized accelerators. The energy consumption associated with training these models is substantial, leading to increased operational costs and environmental concerns. Additionally, the complexity of managing multiple GPUs and specialized hardware increases the difficulty of training and deploying these models.
Model architecture also plays a crucial role in the training process. Designing architectures that are both efficient and capable of capturing the complexities of human language requires a deep understanding of neural network design principles. Innovations such as dynamic architectures, which involve techniques like layer stacking and layer dropping, have been explored to enhance training efficiency. However, these approaches often come with trade-offs in terms of performance and stability, necessitating careful experimentation and validation.
Furthermore, the scarcity of specialized talent in the field of AI and machine learning compounds these challenges. The rapid advancement of AI technologies has outpaced the availability of professionals with the requisite skills and expertise. This shortage leads to increased competition among organizations for qualified personnel, driving up costs and potentially delaying project timelines. Educational programs are beginning to incorporate AI and machine learning into their curricula, but the demand in the business world for skilled professionals far outstrips the current supply.
In addition to these challenges, LLMs are susceptible to issues such as generating incorrect information, known as "hallucinations," and struggling to update outdated knowledge. These problems can undermine the reliability and trustworthiness of the models, posing significant obstacles in their deployment for critical applications.
Addressing these challenges is imperative for the continued advancement of LLMs. Innovations in training techniques, such as the development of efficient training algorithms and the exploration of structured sparsity, are being actively pursued to mitigate some of these issues. For instance, the "Learn-To-be-Efficient" (LTE) algorithm aims to train LLMs to activate fewer neurons, achieving a better trade-off between sparsity and performance.
In conclusion, the training of high-performing LLMs is fraught with challenges that span data acquisition, computational resources, architectural design, and the availability of specialized expertise. Overcoming these obstacles requires a multifaceted approach, combining technological innovation with strategic planning and investment in human capital. As the field progresses, addressing these challenges will be crucial in realizing the full potential of LLMs and ensuring their effective and ethical deployment across various applications.
Google DeepMind's introduction of SALT (Small Language Model Training) represents a significant advancement in the field of machine learning, specifically addressing the challenges associated with training high-performing Large Language Models (LLMs). Traditional LLMs, while powerful, often require extensive computational resources and large datasets, making their training both time-consuming and costly. SALT offers a novel approach by leveraging the efficiency of Small Language Models (SLMs) to enhance the training process of LLMs.
The core concept behind SALT involves utilizing SLMs to guide and accelerate the training of larger models. By employing SLMs, which are less resource-intensive, researchers can perform initial training phases more efficiently. This method allows for a more streamlined training process, reducing the overall computational burden and time required to achieve high performance in LLMs.
Experimental results have demonstrated the effectiveness of SALT. In a study, a 2.8-billion-parameter LLM trained using SALT on the Pile dataset outperformed a baseline model trained with conventional methods. Notably, the SALT-trained model achieved superior results on benchmarks such as reading comprehension, commonsense reasoning, and natural language inference, all while utilizing only 70% of the training steps. This efficiency translated to a reduction of approximately 28% in wall-clock training time, highlighting the practical benefits of the SALT approach.
The implications of SALT extend beyond mere efficiency gains. By reducing the computational resources and time required for training, SALT makes it more feasible to develop high-performing LLMs. This advancement has the potential to democratize access to advanced AI capabilities, enabling a broader range of applications and fostering innovation across various industries.
In summary, SALT represents a promising direction in machine learning, offering a practical solution to the challenges of training large-scale language models. By harnessing the efficiency of SLMs, SALT not only enhances the training process but also contributes to the broader goal of making advanced AI technologies more accessible and applicable to a wide array of real-world problems.
Background
The evolution of language models has been a transformative journey, marked by significant milestones that have progressively enhanced the ability of machines to understand and generate human language. This progression can be traced from the early days of statistical models to the sophisticated Large Language Models (LLMs) and Small Language Models (SLMs) that dominate the field today.
In the early stages, language models were predominantly statistical, relying on probability distributions to predict the likelihood of word sequences. These models, such as N-grams, estimated the probability of a word based on the preceding words in a sequence. While effective for certain tasks, they were limited by their inability to capture long-range dependencies and contextual nuances inherent in human language. The simplicity of these models made them computationally efficient but less adept at handling complex linguistic structures.
The advent of neural networks in the 2010s marked a significant shift in language modeling. Neural Language Models (NLMs) introduced the use of deep learning techniques to capture more intricate patterns in language data. These models utilized architectures like Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs) to process sequences of words, allowing for better handling of context and dependencies over longer text spans. Despite their advancements, NLMs still faced challenges with long-term dependencies and computational efficiency.
A pivotal moment in the evolution of language models came with the introduction of the Transformer architecture in 2017. The Transformer model, introduced in the paper "Attention Is All You Need," revolutionized language modeling by employing self-attention mechanisms. This innovation enabled models to process entire sequences of text simultaneously, capturing complex relationships between words regardless of their position in the sequence. Transformers addressed many limitations of previous architectures, leading to significant improvements in tasks such as translation, summarization, and question-answering.
Building upon the Transformer architecture, Large Language Models (LLMs) emerged, characterized by their vast number of parameters and extensive training datasets. Models like OpenAI's GPT series and Google's BERT demonstrated remarkable capabilities in understanding and generating human-like text. These models were trained on diverse and massive datasets, enabling them to perform a wide array of language tasks with high proficiency. However, the large size of LLMs necessitated significant computational resources, raising concerns about accessibility and environmental impact.
In response to the challenges posed by LLMs, Small Language Models (SLMs) have gained prominence. SLMs are designed to be more efficient, with fewer parameters and reduced computational requirements. Despite their smaller size, SLMs have demonstrated competitive performance on various language tasks, often through techniques like knowledge distillation and fine-tuning. The rise of SLMs reflects a growing emphasis on creating models that balance performance with efficiency, making advanced language processing more accessible and sustainable.
The evolution from statistical models to neural networks, and subsequently to LLMs and SLMs, underscores the rapid advancements in the field of language modeling. Each phase has addressed the limitations of its predecessors, leading to models that are increasingly adept at understanding and generating human language. As research continues, the focus is shifting towards developing models that are not only powerful but also efficient and accessible, paving the way for more widespread and responsible use of AI in language-related applications.
Training Large Language Models (LLMs) presents a multitude of challenges, primarily due to their computational and resource-intensive nature. These challenges encompass several critical aspects, including the need for substantial computational power, the complexities of distributed training, the intricacies of model parallelism, and the significant energy consumption associated with training these models.
One of the foremost challenges in training LLMs is the requirement for substantial computational resources. These models often contain billions of parameters, necessitating the use of high-performance hardware such as Graphics Processing Units (GPUs) or Tensor Processing Units (TPUs). The computational demands are so significant that organizations must allocate considerable resources towards robust hardware infrastructure to ensure efficient model training and execution. This includes not only the acquisition of advanced hardware but also the maintenance and operation of these systems, which can be both costly and complex.
The complexities of distributed training further exacerbate these challenges. Training LLMs often requires the distribution of computations across multiple machines or nodes. This distribution introduces issues related to data synchronization, communication latency, and the efficient management of resources across different nodes. Ensuring that the training process remains efficient and effective in a distributed environment requires sophisticated algorithms and infrastructure, adding another layer of complexity to the training process.
Model parallelism, which involves splitting a model across multiple devices, presents its own set of challenges. LLMs often have complex architectures, making it challenging to split the model across multiple nodes without incurring significant overhead. The need to manage dependencies between different parts of the model and the communication overhead between devices can lead to inefficiencies. This complexity necessitates advanced strategies to optimize the distribution of the model and the data it processes, ensuring that the training process remains both efficient and effective.
Energy consumption is another critical concern. Training LLMs requires significant computational resources, which in turn leads to high energy consumption. The environmental impact of this energy usage is a growing concern, as the carbon footprint associated with training these models can be substantial. Organizations are increasingly aware of the need to balance the benefits of advanced AI capabilities with the environmental costs associated with their development and deployment.
In addition to these technical challenges, there are also financial and logistical considerations. The costs associated with acquiring and maintaining the necessary hardware, as well as the operational expenses related to energy consumption, can be prohibitive. This financial burden can limit the ability of smaller organizations to develop and train LLMs, potentially leading to a concentration of AI capabilities among a few large entities. Furthermore, the logistical challenges of managing large-scale training operations, including data storage, processing, and security, add additional layers of complexity to the training process.
Addressing these challenges requires a multifaceted approach. Advancements in hardware, such as the development of more efficient GPUs and TPUs, can help mitigate some of the computational demands. Innovations in distributed training algorithms and model parallelism strategies are also essential to improve efficiency. Additionally, the development of more energy-efficient training methods and hardware can help reduce the environmental impact. However, these solutions often come with their own set of challenges and trade-offs, necessitating ongoing research and development to achieve optimal outcomes.
Small Language Models (SLMs) have emerged as a pivotal component in the advancement of artificial intelligence (AI), offering a range of benefits that enhance AI capabilities across various domains. By being smaller, faster, and more easily customizable than their larger counterparts, SLMs have become instrumental in making AI more accessible and efficient, particularly for applications with limited resources.
One of the primary advantages of SLMs is their reduced parameter count, typically under 10 billion. This reduction leads to faster inference times and decreased memory usage, making them ideal for deployment in resource-constrained environments such as mobile devices and edge computing platforms. Despite their smaller size, SLMs maintain the ability to understand and generate coherent human-like text, enabling them to perform a wide range of natural language processing tasks effectively.
In the realm of text generation and summarization, SLMs have proven to be highly effective. Their ability to produce coherent and contextually relevant text makes them invaluable for tasks such as content generation for chatbots, virtual assistants, and automated content creation tools. Additionally, SLMs are adept at summarizing large volumes of text, extracting key information, and presenting it in a concise and readable format, thereby enhancing information accessibility and comprehension.
Language translation is another area where SLMs have demonstrated significant impact. Their compact size allows for faster translation processes without compromising translation quality. SLMs contribute to improving the accuracy and efficiency of language translation systems, facilitating real-time communication across language barriers and supporting global business operations.
Sentiment analysis is a critical application of SLMs, enabling businesses to gain insights into customer opinions and feedback. By analyzing textual data from sources such as social media, reviews, and surveys, SLMs can identify and interpret sentiments expressed by users, providing valuable information for decision-making processes. This capability allows companies to respond proactively to customer needs and enhance their products and services accordingly.
Personalized recommendations are another domain where SLMs have shown efficacy. By processing user interactions and preferences, SLMs can generate tailored suggestions for products, services, or content, thereby enhancing user experience and engagement. This personalization fosters customer satisfaction and loyalty, contributing to the success of businesses in competitive markets.
The adaptability of SLMs extends to various other applications, including text classification, named entity recognition, and question-answering systems. Their efficiency and versatility make them suitable for a wide range of tasks, from automating routine processes to providing advanced AI-driven solutions. The continuous development and optimization of SLMs promise further enhancements in AI capabilities, leading to more intelligent and responsive systems across diverse industries.
Deep Dive into SALT
The conceptual framework underpinning SALT (Switching Autoregressive Low-rank Tensor) models integrates principles from autoregressive hidden Markov models (ARHMMs) and switching linear dynamical systems (SLDSs) to effectively model systems with time-varying dynamics. This integration is achieved by parameterizing the tensor of an ARHMM with a low-rank factorization, thereby controlling the number of parameters and allowing for the capture of longer-range dependencies without overfitting. The low-rank factorization serves as a regularization technique, reducing the model's complexity and enhancing its generalization capabilities.
In practice, SALT models utilize a tensor representation to encapsulate the relationships between different states and time steps. This tensor is decomposed into low-rank components, which are learned from the data through optimization techniques. The low-rank structure ensures that the model captures the most significant patterns in the data while discarding noise and less informative variations. This approach not only improves computational efficiency but also enhances the interpretability of the model by highlighting the principal components of the data.
The training of SALT models involves the use of unrolled optimization algorithms, which iteratively refine the model parameters to minimize a loss function. These algorithms are designed to efficiently handle the complexities associated with low-rank tensor decompositions and time-series data. By leveraging the unrolled structure, SALT models can effectively capture temporal dependencies and transitions between different states, making them particularly well-suited for applications in behavioral and neural data analysis.
The theoretical foundation of SALT models is grounded in the principles of linear dynamical systems and SLDSs. These systems are characterized by their ability to model time-varying processes through state transitions governed by linear equations. SALT models extend this framework by incorporating low-rank tensor decompositions, which allow for a more compact and efficient representation of the system dynamics. This extension enables the modeling of complex, high-dimensional data with a reduced risk of overfitting, as the low-rank structure imposes a form of regularization on the model.
Empirical evaluations of SALT models have demonstrated their effectiveness across a range of tasks, including behavioral and neural data analysis. In these applications, SALT models have been shown to outperform traditional ARHMMs and SLDSs, particularly in scenarios involving long-range dependencies and complex temporal patterns. The low-rank factorization not only enhances predictive accuracy but also provides insights into the underlying structure of the data, facilitating a deeper understanding of the temporal dynamics at play.
In summary, the conceptual framework of SALT models represents a sophisticated integration of autoregressive hidden Markov models, switching linear dynamical systems, and low-rank tensor decompositions. This synthesis results in a powerful modeling approach capable of capturing complex, time-varying dynamics with enhanced efficiency and interpretability. The ongoing development and refinement of SALT models hold promise for advancing the field of machine learning, particularly in areas requiring the analysis of temporal data with intricate dependencies.
Google DeepMind's innovative approach, known as SALT (Small model Aided Large model Training), leverages the capabilities of Small Language Models (SLMs) to enhance the training efficiency and performance of Large Language Models (LLMs). This integration addresses several challenges inherent in training large-scale models, such as high computational costs, extended training durations, and the need for vast amounts of data.
In traditional LLM training, models are exposed to extensive datasets, often without differentiation between easy and complex examples. This uniform treatment can lead to inefficiencies, as the model expends resources on straightforward instances that do not significantly contribute to learning. SALT introduces a strategic shift by utilizing SLMs to identify and prioritize challenging yet learnable data points early in the training process. This selective focus ensures that the LLM dedicates computational resources to instances that offer the most substantial learning opportunities, thereby accelerating the training process and enhancing model performance.
The integration of SLMs into the LLM training process occurs in two distinct phases. Initially, SLMs serve as teachers, providing soft labels—probability distributions over possible outputs—for each token. This method offers a nuanced form of supervision, guiding the LLM to align its predictions with those of the SLM in areas where the latter excels. This phase allows the LLM to build a foundational understanding of the data distribution, focusing on areas where the SLM is confident.
In the subsequent phase, the LLM transitions to traditional self-supervised learning, refining its understanding of more complex data distributions. During this phase, the LLM continues to learn from the data, now equipped with the insights gained from the SLM-guided phase. This two-stage process effectively balances the strengths of SLMs with the inherent capabilities of LLMs, leading to more efficient and effective training outcomes.
Empirical evaluations of SALT have demonstrated its effectiveness in enhancing LLM training. For instance, a 2.8-billion-parameter LLM trained using SALT on the Pile dataset outperformed a baseline model trained through conventional methods. Notably, the SALT-trained model achieved superior results on benchmarks such as reading comprehension, commonsense reasoning, and natural language inference, all while utilizing only 70% of the training steps. This efficiency translated to a reduction of approximately 28% in wall-clock training time, underscoring the practical benefits of integrating SLMs into LLM training.
By incorporating SLMs into the training regimen, SALT addresses several critical challenges in LLM development. It reduces computational requirements, accelerates training times, and enhances model performance across various tasks. This innovative approach not only optimizes the training process but also contributes to the democratization of advanced AI technologies by making them more accessible and efficient.
The Switching Autoregressive Low-rank Tensor (SALT) model introduces several technical innovations that enhance the efficiency and performance of large language models (LLMs). By integrating principles from autoregressive hidden Markov models (ARHMMs) and switching linear dynamical systems (SLDSs), SALT addresses key challenges in modeling time-varying dynamics and long-range dependencies.
A central innovation of SALT is its use of low-rank tensor factorization to parameterize the transition dynamics of the model. This approach reduces the number of parameters required to capture complex temporal dependencies, mitigating the risk of overfitting and improving generalization to new data. The low-rank factorization enables the model to efficiently represent high-dimensional data structures, facilitating the learning of intricate patterns without excessive computational demands.
Incorporating the concept of switching dynamics, SALT models the system as a mixture of linear dynamical systems, each corresponding to a distinct regime or state. This switching mechanism allows the model to adapt to different temporal patterns, effectively capturing the underlying structure of the data. By learning the transitions between these states, SALT can model complex, non-linear temporal dynamics that are often present in real-world datasets.
The integration of ARHMMs within SALT provides a probabilistic framework that facilitates exact inference and straightforward parameter estimation. This probabilistic foundation enhances the model's interpretability and robustness, making it well-suited for applications where understanding the underlying data distribution is crucial. The combination of ARHMMs and SLDSs within SALT offers a balanced approach to modeling time-varying dynamics, leveraging the strengths of both methodologies while mitigating their individual limitations.
Empirical evaluations have demonstrated that SALT outperforms traditional models in various tasks, including behavioral and neural data analysis. For instance, a 2.8-billion-parameter LLM trained with SALT on the Pile dataset achieved superior results on benchmarks such as reading comprehension, commonsense reasoning, and natural language inference, all while utilizing only 70% of the training steps. This efficiency translates to a reduction of approximately 28% in wall-clock training time, highlighting the practical benefits of SALT's technical innovations.
In summary, SALT's technical innovations—low-rank tensor factorization, switching dynamics, and the integration of ARHMMs—collectively enhance the modeling of time-varying dynamics and long-range dependencies in large language models. These advancements contribute to more efficient training processes and improved performance across a range of applications, marking a significant step forward in the field of machine learning.
Implications and Applications
The introduction of SALT (Small model Aided Large model Training) by Google DeepMind represents a significant advancement in artificial intelligence (AI), with the potential to profoundly influence future AI research and applications. By leveraging smaller, less computationally intensive models to assist in training large language models (LLMs), SALT addresses several critical challenges in AI development, including resource constraints, training efficiency, and accessibility.
One of the most notable impacts of SALT is its ability to democratize access to advanced AI technologies. Traditionally, training LLMs requires substantial computational resources, making it a costly endeavor accessible primarily to well-funded organizations. SALT mitigates this barrier by utilizing smaller models to guide the training of larger ones, thereby reducing the computational load and associated costs. This approach enables institutions with limited resources to develop high-performing LLMs, fostering a more inclusive AI research environment.
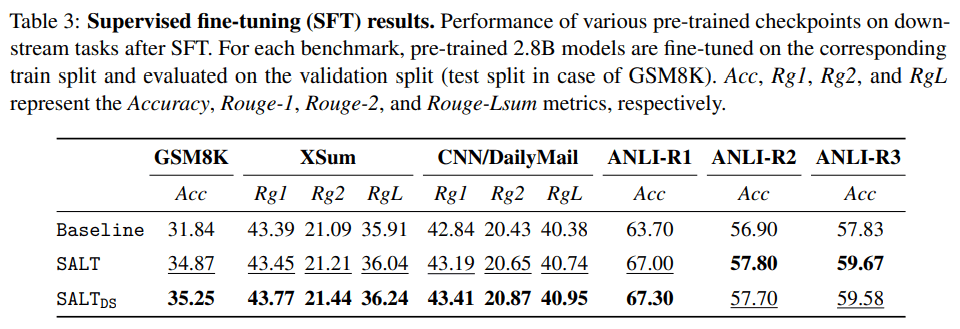
In terms of training efficiency, SALT introduces a two-stage process that enhances the learning capabilities of LLMs. In the initial stage, smaller models provide soft labels for training, allowing the larger models to learn from a broader range of data. This method accelerates the training process and improves the generalization of the LLMs. Subsequently, the LLMs undergo supervised fine-tuning, further refining their performance. Empirical evaluations have demonstrated that SALT-trained models exhibit better generalization in few-shot evaluations and downstream tasks, highlighting the effectiveness of this training methodology.
The integration of SALT into AI development has the potential to accelerate advancements across various sectors. In healthcare, for instance, more efficient LLM training could lead to improved predictive models for patient outcomes, personalized medicine, and drug discovery. By enabling the development of more accurate and accessible AI tools, SALT could revolutionize how healthcare systems operate, making them more responsive and effective.
In the realm of scientific research, SALT's impact is equally profound. DeepMind's previous work, such as the development of AlphaFold, has already demonstrated the transformative potential of AI in understanding complex biological structures. SALT could further accelerate discoveries in materials science, chemistry, and physics by enabling the rapid training of models capable of predicting molecular behaviors and interactions. This capability could lead to the development of new materials and drugs, addressing pressing global challenges.
Furthermore, SALT's approach to model training could influence the development of autonomous systems. By improving the efficiency and performance of LLMs, SALT could enhance the capabilities of AI-driven systems in areas such as robotics, transportation, and logistics. More efficient training processes would allow for the deployment of more sophisticated autonomous systems, leading to advancements in various industries.
In summary, SALT's innovative methodology has the potential to significantly impact AI research and applications by addressing resource constraints, enhancing training efficiency, and broadening access to advanced AI technologies. Its influence is expected to accelerate progress across multiple sectors, including healthcare, scientific research, and autonomous systems, thereby contributing to the advancement of AI as a transformative force in society.
The introduction of SALT (Small model Aided Large model Training) by Google DeepMind presents a transformative approach to training large language models (LLMs), with the potential to significantly impact various sectors. By utilizing smaller models to assist in the training of larger ones, SALT addresses several critical challenges in AI development, including resource constraints, training efficiency, and accessibility.
One of the most notable impacts of SALT is its ability to democratize access to advanced AI technologies. Traditionally, training LLMs requires substantial computational resources, making it a costly endeavor accessible primarily to well-funded organizations. SALT mitigates this barrier by utilizing smaller models to guide the training of larger ones, thereby reducing the computational load and associated costs. This approach enables institutions with limited resources to develop high-performing LLMs, fostering a more inclusive AI research environment.
In terms of training efficiency, SALT introduces a two-stage process that enhances the learning capabilities of LLMs. In the initial stage, smaller models provide soft labels for training, allowing the larger models to learn from a broader range of data. This method accelerates the training process and improves the generalization of the LLMs. Subsequently, the LLMs undergo supervised fine-tuning, further refining their performance. Empirical evaluations have demonstrated that SALT-trained models exhibit better generalization in few-shot evaluations and downstream tasks, highlighting the effectiveness of this training methodology.
The integration of SALT into AI development has the potential to accelerate advancements across various sectors. In healthcare, for instance, more efficient LLM training could lead to improved predictive models for patient outcomes, personalized medicine, and drug discovery. By enabling the development of more accurate and accessible AI tools, SALT could revolutionize how healthcare systems operate, making them more responsive and effective.
In the realm of scientific research, SALT's impact is equally profound. DeepMind's previous work, such as the development of AlphaFold, has already demonstrated the transformative potential of AI in understanding complex biological structures. SALT could further accelerate discoveries in materials science, chemistry, and physics by enabling the rapid training of models capable of predicting molecular behaviors and interactions. This capability could lead to the development of new materials and drugs, addressing pressing global challenges.
Furthermore, SALT's approach to model training could influence the development of autonomous systems. By improving the efficiency and performance of LLMs, SALT could enhance the capabilities of AI-driven systems in areas such as robotics, transportation, and logistics. More efficient training processes would allow for the deployment of more sophisticated autonomous systems, leading to advancements in various industries.
SALT (Sequence Alignment (un)Likelihood Training) represents a significant advancement in training large language models (LLMs), offering notable improvements in both efficiency and performance compared to traditional methods. By integrating human edits into the training process, SALT enhances the quality of generated summaries, particularly in specialized domains such as medical summarization.
In conventional training approaches, LLMs are typically trained on large datasets using maximum likelihood estimation, which focuses on predicting the next token in a sequence. While effective, this method may not fully capture the nuances of human language, especially in specialized contexts. SALT addresses this limitation by incorporating human edits into the training loop, allowing the model to learn from both human-generated and model-generated data. This dual-source training enables the model to better align with human expectations and improve the quality of its outputs.
The effectiveness of SALT has been demonstrated in various experiments. In the medical domain, models trained with SALT have shown superior performance in summarization tasks compared to those trained with traditional reinforcement learning from human feedback (RLHF) methods. This improvement is attributed to the model's ability to learn from human edits, leading to more accurate and contextually appropriate summaries.
Moreover, SALT's approach to training is more resource-efficient. By leveraging human edits, the model requires fewer training steps to achieve high performance, reducing computational costs and time. This efficiency makes SALT particularly advantageous for institutions with limited computational resources, democratizing access to advanced AI technologies.
Conclusion
SALT (Small model Aided Large model Training) is a novel approach introduced by Google DeepMind to enhance the training of large language models (LLMs). By leveraging smaller, less computationally intensive models, SALT addresses several critical challenges in AI development, including resource constraints, training efficiency, and accessibility.
Traditional training methods for LLMs often require substantial computational resources, making them costly and accessible primarily to well-funded organizations. SALT mitigates this barrier by utilizing smaller models to guide the training of larger ones, thereby reducing the computational load and associated costs. This approach enables institutions with limited resources to develop high-performing LLMs, fostering a more inclusive AI research environment.
In terms of training efficiency, SALT introduces a two-stage process that enhances the learning capabilities of LLMs. In the initial stage, smaller models provide soft labels for training, allowing the larger models to learn from a broader range of data. This method accelerates the training process and improves the generalization of the LLMs. Subsequently, the LLMs undergo supervised fine-tuning, further refining their performance. Empirical evaluations have demonstrated that SALT-trained models exhibit better generalization in few-shot evaluations and downstream tasks, highlighting the effectiveness of this training methodology.
The integration of SALT into AI development has the potential to accelerate advancements across various sectors. In healthcare, for instance, more efficient LLM training could lead to improved predictive models for patient outcomes, personalized medicine, and drug discovery. By enabling the development of more accurate and accessible AI tools, SALT could revolutionize how healthcare systems operate, making them more responsive and effective.
In the realm of scientific research, SALT's impact is equally profound. DeepMind's previous work, such as the development of AlphaFold, has already demonstrated the transformative potential of AI in understanding complex biological structures. SALT could further accelerate discoveries in materials science, chemistry, and physics by enabling the rapid training of models capable of predicting molecular behaviors and interactions. This capability could lead to the development of new materials and drugs, addressing pressing global challenges.
Furthermore, SALT's approach to model training could influence the development of autonomous systems. By improving the efficiency and performance of LLMs, SALT could enhance the capabilities of AI-driven systems in areas such as robotics, transportation, and logistics. More efficient training processes would allow for the deployment of more sophisticated autonomous systems, leading to advancements in various industries.
In summary, SALT's innovative methodology has the potential to significantly impact AI research and applications by addressing resource constraints, enhancing training efficiency, and broadening access to advanced AI technologies. Its influence is expected to accelerate progress across multiple sectors, including healthcare, scientific research, and autonomous systems, thereby contributing to the advancement of AI as a transformative force in society.
SALT (Small model Aided Large model Training) has emerged as a transformative approach in the field of artificial intelligence, particularly in the training of large language models (LLMs). By leveraging smaller models to guide the training of larger ones, SALT addresses several critical challenges, including resource constraints, training efficiency, and accessibility. This innovative methodology has the potential to significantly influence future developments in AI research and applications.
One of the most promising aspects of SALT is its ability to democratize access to advanced AI technologies. Traditional training methods for LLMs often require substantial computational resources, making them costly and accessible primarily to well-funded organizations. SALT mitigates this barrier by utilizing smaller models to guide the training of larger ones, thereby reducing the computational load and associated costs. This approach enables institutions with limited resources to develop high-performing LLMs, fostering a more inclusive AI research environment. As a result, we can anticipate a broader range of organizations and researchers contributing to AI advancements, leading to a more diverse and innovative landscape.
In terms of training efficiency, SALT introduces a two-stage process that enhances the learning capabilities of LLMs. In the initial stage, smaller models provide soft labels for training, allowing the larger models to learn from a broader range of data. This method accelerates the training process and improves the generalization of the LLMs. Subsequently, the LLMs undergo supervised fine-tuning, further refining their performance. Empirical evaluations have demonstrated that SALT-trained models exhibit better generalization in few-shot evaluations and downstream tasks, highlighting the effectiveness of this training methodology. Looking ahead, we can expect further refinements in this process, potentially incorporating more sophisticated techniques to enhance model performance and reduce training times even further.
The integration of SALT into AI development has the potential to accelerate advancements across various sectors. In healthcare, for instance, more efficient LLM training could lead to improved predictive models for patient outcomes, personalized medicine, and drug discovery. By enabling the development of more accurate and accessible AI tools, SALT could revolutionize how healthcare systems operate, making them more responsive and effective. This could result in better patient care, more efficient medical research, and a more personalized approach to treatment.
In the realm of scientific research, SALT's impact is equally profound. DeepMind's previous work, such as the development of AlphaFold, has already demonstrated the transformative potential of AI in understanding complex biological structures. SALT could further accelerate discoveries in materials science, chemistry, and physics by enabling the rapid training of models capable of predicting molecular behaviors and interactions. This capability could lead to the development of new materials and drugs, addressing pressing global challenges. Additionally, the ability to model complex systems more efficiently could open new avenues in scientific exploration and innovation.
Furthermore, SALT's approach to model training could influence the development of autonomous systems. By improving the efficiency and performance of LLMs, SALT could enhance the capabilities of AI-driven systems in areas such as robotics, transportation, and logistics. More efficient training processes would allow for the deployment of more sophisticated autonomous systems, leading to advancements in various industries. This could result in safer, more efficient transportation systems, more capable robots in manufacturing and service industries, and improved logistics operations.
In summary, SALT's innovative methodology has the potential to significantly impact AI research and applications by addressing resource constraints, enhancing training efficiency, and broadening access to advanced AI technologies. Its influence is expected to accelerate progress across multiple sectors, including healthcare, scientific research, and autonomous systems, thereby contributing to the advancement of AI as a transformative force in society. As research in this area continues, we can anticipate further developments that will refine and expand the capabilities of SALT, leading to even more profound impacts on AI and its applications.
References
SALT (Sequence Alignment (un)Likelihood Training) is a novel approach introduced by Google DeepMind to enhance the training of large language models (LLMs). By integrating human edits into the training process, SALT aims to improve the quality of generated summaries, particularly in specialized domains such as medical summarization. The foundational research paper detailing SALT is titled "Improving Summarization with Human Edits" by Zonghai Yao, Benjamin J. Schloss, and Sai P. Selvaraj, published on October 9, 2023.
In addition to the primary research paper, several related articles provide further insights into SALT and its applications:
"Google DeepMind Introduces 'SALT': A Machine Learning Approach to Efficiently Train High-Performing Large Language Models Using SLMs" discusses the innovative use of smaller language models (SLMs) to enhance LLM training efficiency.
"The SALT: Revolutionizing Large Language Model (LLM) Training with Small Language Models (SLMs)" explores how SALT leverages SLMs to make LLM training more efficient and affordable.
For a broader understanding of the context and challenges in LLM training, the following resources are recommended:
"An Emulator for Fine-Tuning Large Language Models using Small Language Models" by Eric Mitchell et al. investigates the decoupling of knowledge and skills gained during pre-training and fine-tuning stages in LLMs.
"Self-Augmentation Improves Zero-Shot Cross-Lingual Transfer" by Fei Wang et al. examines methods to enhance cross-lingual transferability in multilingual pretrained language models.
These resources offer valuable perspectives on the advancements and methodologies in LLM training, complementing the insights provided by SALT.
Press contact
Timon Harz
oneboardhq@outlook.com
Other posts





Company
About
Blog
Careers
Press
Legal
Privacy
Terms
Security