Timon Harz
December 14, 2024
Deploying Transformers on the Apple Neural Engine
Discover how to apply key optimizations to Transformer models for efficient deployment on Apple devices. We demonstrate the process with a case study of the distilbert model, showcasing significant improvements in speed and memory usage.

Each year, more machine learning (ML) models at Apple are adopting the Transformer architecture, powering experiences like panoptic segmentation in Camera with HyperDETR, on-device scene analysis in Photos, image captioning for accessibility, and machine translation. At WWDC 2022, Apple introduced an open-source reference PyTorch implementation of the Transformer architecture, allowing developers worldwide to deploy state-of-the-art Transformer models seamlessly on Apple devices.
This implementation is specifically optimized for the Apple Neural Engine (ANE), a high-throughput, energy-efficient engine for ML inference on Apple silicon. It helps developers minimize the impact of ML inference workloads on memory, responsiveness, and battery life while supporting user privacy by keeping inference data on-device. In this article, we explain the principles behind this reference implementation to guide developers on optimizing their models for ANE execution. We then demonstrate these principles by deploying the popular Hugging Face distilbert model with just a few lines of code. After optimization, this model runs up to 10 times faster and consumes 14 times less memory.
The Transformer Architecture
Introduced in 2017, the Transformer architecture revolutionized fields like natural language processing and computer vision, delivering state-of-the-art results across diverse tasks without requiring domain-specific components. The flexibility and success of this architecture led to the rapid proliferation of Transformer-based models, with models like GPT-2 and BERT available on the Hugging Face model hub. These pretrained models contribute to ongoing research and have prompted the development of efficient deployment strategies for both on-device and server-side applications.
The Apple Neural Engine
The Apple Neural Engine (ANE) debuted in 2017 as part of the A11 chip in iPhone X, offering a peak throughput of 0.6 teraflops (TFlops) in half-precision floating-point format (FP16). It powered key features such as Face ID and Memoji. By 2021, the fifth-generation ANE, found in the M1 chip, delivers 15.8 TFlops, offering 26 times the processing power of the original. As the ANE's capabilities expanded to include iPads and Macs, its use in Apple and third-party applications grew, supporting the increasing demand for on-device machine learning.

Figure 1: The evolution of the Apple Neural Engine, 2017 to 2021. The 16-core Neural Engine on the A15 Bionic chip on iPhone 13 Pro has a peak throughput of 15.8 teraflops, an increase of 26 times that of iPhone X.
Accelerating ML Training and Deployment with Metal Performance Shaders and Core ML
When training machine learning (ML) models, developers can accelerate the process on GPUs with PyTorch and TensorFlow using the Metal Performance Shaders (MPS) backend. For deployment on Apple devices, coremltools, Apple's open-source tool, allows for easy conversion of PyTorch and TensorFlow models to Core ML's model format. Core ML then optimizes execution by utilizing the CPU, GPU, and Apple Neural Engine (ANE), forming a hybrid execution plan that maximizes efficiency based on device capabilities. This enables models to leverage the ANE even when the entire execution can't take place there due to specific model requirements. This streamlined process helps developers deploy models on Apple devices without worrying about device-specific constraints.
Optimizing Transformers for the Apple Neural Engine
While hybrid execution offers flexibility, developers can optimize model performance by focusing on a specific, principled approach that fully harnesses the ANE. This strategy improves throughput, reduces memory usage, and minimizes context-transfer overhead between engines, allowing the CPU and GPU to handle non-ML tasks while the ANE processes the most demanding workloads.
Principles Behind Optimizing Transformers for the Neural Engine
Principle 1: Selecting the Right Data Format
The Transformer architecture typically processes a 3D input tensor representing a batch of sequences, but for optimal performance on the ANE, the input should be in a 4D, channels-first format (B, C, 1, S). To achieve this, we swap nn.Linear layers with nn.Conv2d layers. We also use a load_state_dict_pre_hook to adjust the weights of previously trained models to match the new format. Proper alignment of the last axis to 64 bytes is crucial to avoid unnecessary memory padding, which can significantly increase memory usage and degrade performance.
Principle 2: Chunking Large Intermediate Tensors
In the multihead attention function, splitting the query, key, and value tensors into smaller chunks improves cache residency and optimizes multicore utilization during compilation. Smaller chunks help ensure better performance and efficiency.
Principle 3: Minimizing Memory Copies
To minimize memory overhead, we avoid reshapes and limit tensor transposes, except for a single transpose on the key tensor before the query and key matmul operation. By using the einsum operation (bchq,bkhc->bkhq), we eliminate unnecessary reshape and transpose operations, optimizing the matrix multiplication for scaled dot-product attention.
Principle 4: Addressing Bandwidth Limitations
After applying optimizations, some Transformer models still face bandwidth limitations when sequence lengths are short. This occurs because large parameter tensors are fetched from memory and applied to a limited number of inputs, resulting in memory fetching dominating the overall latency. To mitigate this, developers can increase batch size for batch inference workloads or reduce the parameter tensor size through quantization or pruning, thus speeding up memory fetching.
Principles Transformed into Code: ane_transformers
We’ve packaged the principles discussed into a reference implementation and made it available on PyPI to accelerate Transformer models running on Apple devices with the Apple Neural Engine (ANE), specifically on A14 and later, or M1 and later chips. This package, named ane_transformers, was first used in HyperDETR, the on-device application featured in a previous article.
In the following, we demonstrate how these principles can be applied to a pretrained Transformer model, distilbert from Hugging Face. The code for this example is also available through ane_transformers.
Case Study: Hugging Face distilbert
As deep learning scaling laws continue to hold, the ML community is training increasingly larger and more powerful Transformer models. However, most open-source Transformer implementations are optimized either for large-scale training hardware or no hardware at all. Despite advancements in model compression, state-of-the-art models are growing faster than compression techniques can keep up.
This gap creates a significant need for on-device inference optimizations that can translate research advances into practical applications. Such optimizations would enable ML practitioners to deploy larger models on the same input set or scale the input sets without exceeding the available compute resources.
In this case study, we apply the principles behind our open-source reference PyTorch implementation to the widely used distilbert model from Hugging Face. The optimizations resulted in a forward pass that is up to 10 times faster while reducing peak memory consumption by 14 times on the iPhone 13. Using our reference implementation, with a sequence length of 128 and batch size of 1, the iPhone 13's ANE achieves an average latency of 3.47 ms at 0.454 W and 9.44 ms at 0.072 W. Even with these optimizations, the ANE peak throughput is not fully saturated for this model, and performance could be further improved by incorporating quantization and pruning techniques.
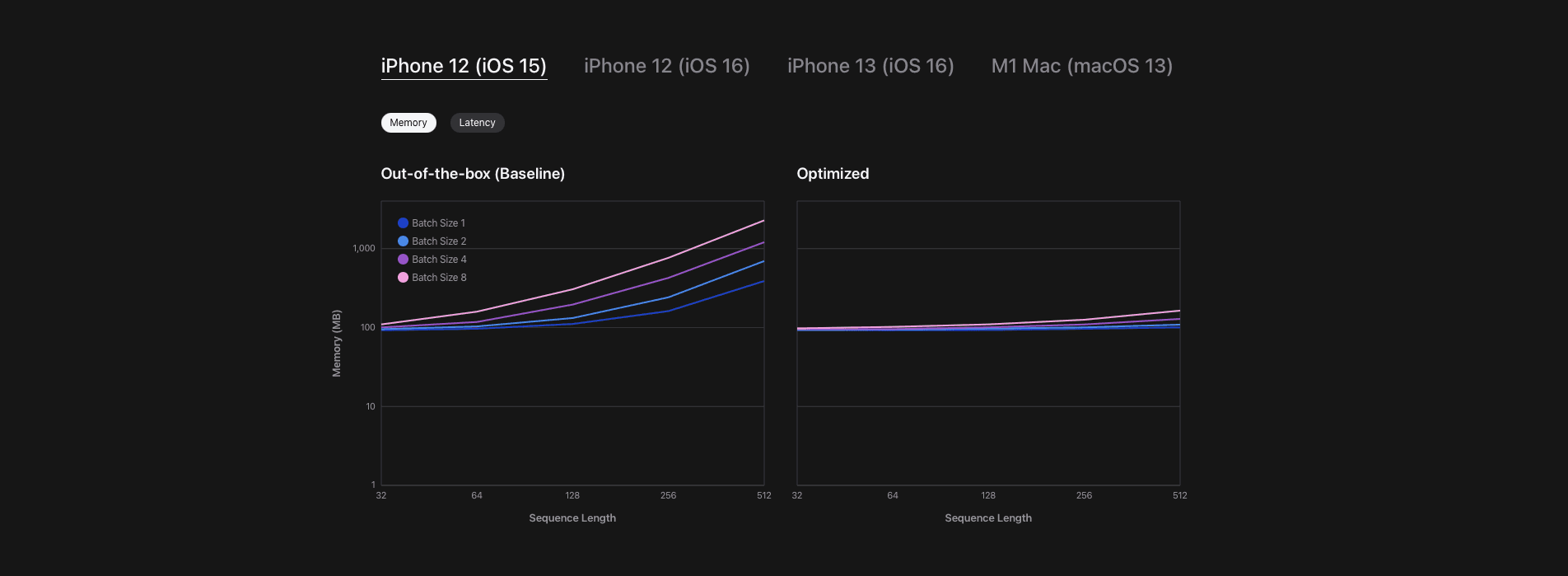
Figure 2: Performance curves (latency, memory) for Hugging Face distilbert on various Apple devices and operating system versions. Shaded ranges indicate performance under varying power consumption.
Contextualizing the Performance:
To put the reported numbers in context, a recent article from Hugging Face and AWS noted that “the average latency… is 5-6 ms for a sequence length of 128” when running the same model from our case study on server-side ML-optimized ASIC hardware at AWS. In comparison, we’re pleased to report that our on-device inference latency holds up well against these server-side benchmarks, even though the device is far more energy-constrained. Figure 2 illustrates the latency and memory consumption for the same model across various sequence lengths, batch sizes, and devices.
Bringing It All Together: From PyTorch to Xcode
Now, we’ll demonstrate how these optimizations can be implemented with just a few lines of code and how to profile the model in Xcode using the new Core ML Performance Report feature available in Xcode 14.
To begin, initialize the baseline distilbert model from the Hugging Face model hub:
Next, initialize the optimized model, and load the parameters from the baseline model to ensure output parity, as measured by peak-signal-to-noise-ratio (PSNR):
Now, create sample inputs for the model:
Then, trace the optimized model to obtain the expected TorchScript format for conversion with coremltools:
Finally, use coremltools to convert the model to a Core ML model package and save it:
To test performance, developers can now open Xcode, add the model package file to their project, and generate a performance report on local devices. For instance, they can run the report on a Mac or any Apple device connected to the Mac. Figure 3 shows a performance report generated for this model on an iPhone 13 Pro Max with iOS 16.0.
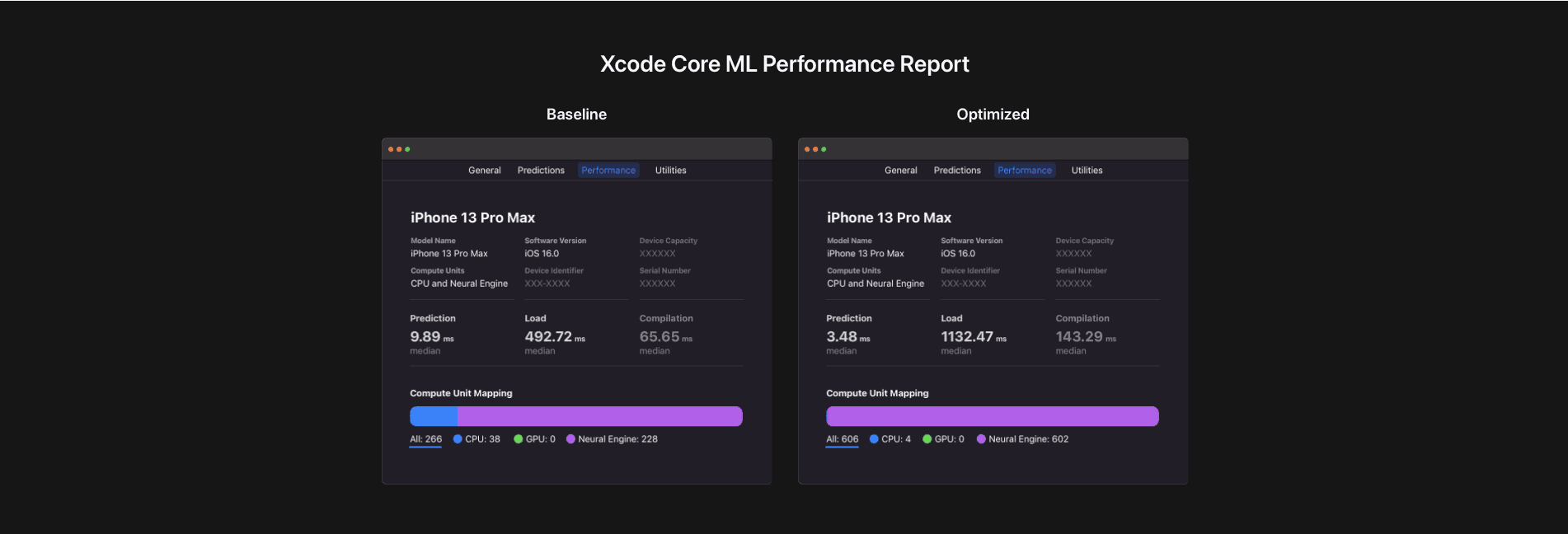
Figure 3: Core ML performance reports generated in Xcode. Developers can review runtime statistics, layer dispatch to each engine, and accomplish additional tasks.
Conclusion
Transformers are becoming ubiquitous in ML as their capabilities scale up with their size. Deploying Transformers on-devices requires efficient strategies, and we are thrilled to provide guidance to developers on this topic. Learn more about the implementation described in this post on the Machine Learning ANE Transformers GitHub.
Press contact
Timon Harz
oneboardhq@outlook.com
Other posts





Company
About
Blog
Careers
Press
Legal
Privacy
Terms
Security