Timon Harz
December 18, 2024
CMU Researchers Introduce miniCodeProps: A Minimal AI Benchmark for Verifying Code Properties
CMU researchers unveil miniCodeProps, a revolutionary benchmark designed to assess AI's capabilities in proving code properties. Learn how this innovation is pushing the boundaries of automated theorem proving and AI's role in software verification.

AI agents have recently shown great potential in automating mathematical theorem proving and code correctness verification through tools like Lean. These tools combine code with specifications and proofs to ensure that the code meets its intended requirements, providing strong safeguards for safety-critical applications. With the help of large language models, AI has demonstrated its ability to facilitate core steps in solution development—coding, specifying, and proving. While these advances are promising, fully automating program verification remains a significant challenge.
Traditionally, mathematical theorem proving has relied on tools like Lean, which train models using datasets such as Mathlib to solve problems with specific definitions and strategies. However, these tools have faced difficulties when it comes to adapting to program verification, which requires entirely different techniques. While machine learning has improved automation in systems like Coq and Isabelle, similar advancements for Lean in program verification are still lacking. Although other tools like Dafny, Verus, and benchmarks such as miniF2F and CoqGym offer alternatives, they have not fully addressed the challenge of adapting theorem-proving methods to the requirements of program verification.
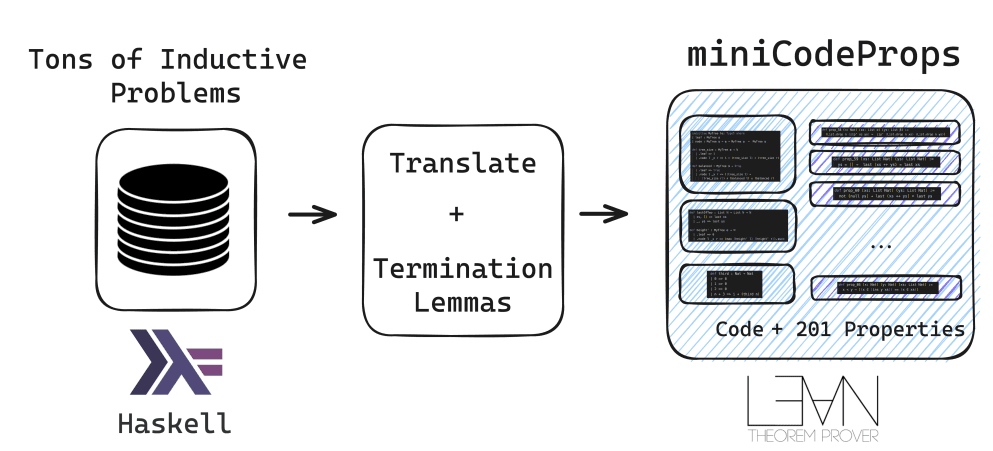
To address the challenge of automatically generating proofs for programs and their specifications, researchers from Carnegie Mellon University introduced miniCodeProps, a benchmark featuring 201 program specifications in the Lean proof assistant. The benchmark consists of simple, self-contained programs—such as lists, natural numbers, and binary trees—with varying levels of difficulty for proof generation. miniCodeProps is divided into three categories: intuitive properties of lists, trees, and numbers (medley); termination lemmas for recursive functions (termination); and properties of nonstandard sorting algorithms (sorting).
The functions primarily operate on linked lists, with some involving natural numbers and binary trees. The properties are classified by difficulty: easy (medley), medium (termination), and hard (sorting). Termination lemmas, which are essential for proving recursion termination in Lean 4, add an extra layer of complexity. The dataset, available in jsonlines format, provides crucial information such as the proof state and dependencies for each theorem. Notable examples, like the zip over concatenation property and sorting properties, illustrate the challenges of proving properties, particularly for more complex sorting algorithms.
The evaluation of miniCodeProps focused on two main tasks: full-proof generation and tactic-by-tactic generation. In full-proof generation, models were assessed based on their ability to produce complete proofs for given specifications. For tactic-by-tactic generation, models were tested on their ability to suggest the next appropriate tactic from the current proof state, evaluating incremental reasoning. The evaluation also considered the varying difficulty levels of the proofs, from simple properties of lists and numbers to more complex termination and sorting algorithm properties, measuring both efficiency and correctness in proof generation or tactic application.
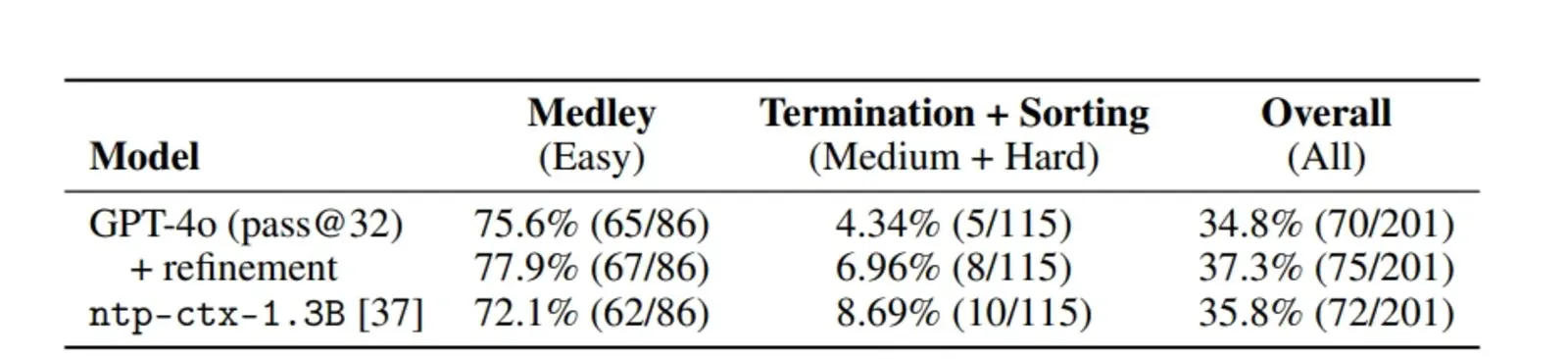
The results showed that neural theorem provers, such as GPT-4o, performed well on simpler tasks, achieving a 75.6% success rate on medley properties. However, performance on more difficult tasks, like termination and sorting, was lower, at 4.34% and 6.96%, respectively. The Mathlib-trained model ntp-ctx-1.3B demonstrated similar efficiency to GPT-4o, indicating the potential for domain-specific verifiers to make further progress. MiniCodeProps offers a valuable framework for improving automated theorem-proving agents used in code verification, supporting human engineers and providing additional guarantees through diverse reasoning approaches.
Ultimately, the miniCodeProps benchmark is a valuable tool for advancing automated ITP-based code verification. It features problems from a variety of inductive problem datasets, allowing for incremental progress in verifying program properties. However, the method does have limitations and struggles with more complex problems. Despite this, miniCodeProps holds significant potential to drive advancements in verification agents and can serve as a baseline for evaluating new approaches in automated code verification.
Researchers at Carnegie Mellon University (CMU) have introduced miniCodeProps, a benchmark designed to advance the field of automated code verification. This initiative addresses the critical need for tools that can ensure the correctness of software systems, thereby reducing the risk of bugs and vulnerabilities that can lead to significant real-world consequences.
The miniCodeProps benchmark comprises 201 program specifications within the Lean proof assistant framework. These specifications pertain to simple, self-contained programs involving fundamental data structures such as lists, natural numbers, and binary trees. The primary objective is to evaluate the capability of AI models, particularly large language models (LLMs), in automatically generating proofs that confirm these programs adhere to their specified properties. This approach aims to streamline the verification process, making it more accessible and efficient.
The benchmark is structured into three categories, each targeting different aspects of code properties:
Medley: This category includes intuitive properties related to lists, trees, and numbers.
Termination: It focuses on termination lemmas for recursive functions, ensuring that such functions conclude as intended.
Sorting: This section examines properties of nonstandard sorting algorithms, assessing their correctness and efficiency.
By encompassing a diverse range of properties, miniCodeProps provides a comprehensive framework for evaluating AI-driven code verification methods.
The evaluation of AI models using miniCodeProps involves two primary tasks:
Full-Proof Generation: Assessing the model's ability to produce complete proofs for given specifications.
Tactic-by-Tactic Generation: Evaluating the model's proficiency in suggesting the next appropriate tactic from the current proof state, thereby testing incremental reasoning capabilities.
These tasks are designed to measure both the efficiency and correctness of AI models in the context of code verification.
Initial results indicate that while current LLM-based provers perform well on simpler tasks, achieving a 75.6% success rate on medley properties, their performance diminishes on more complex tasks. For instance, they succeeded in proving only 4.34% of termination properties and 6.96% of sorting properties. This disparity highlights the challenges that remain in automating code verification and underscores the need for further research and development in this area.
The introduction of miniCodeProps represents a significant step forward in the quest to automate code verification. By providing a standardized benchmark, it facilitates the development and evaluation of AI models capable of verifying code properties. This advancement has the potential to enhance the reliability and security of software systems, ultimately benefiting both developers and end-users.
For those interested in exploring miniCodeProps further, the benchmark is publicly available, and the evaluation scripts can be accessed on GitHub. This openness encourages collaboration and innovation within the research community, fostering the advancement of automated code verification techniques.
Automating code verification is a critical advancement in software development, addressing the increasing complexity and scale of modern applications. As software systems become more intricate, the potential for errors and vulnerabilities escalates, posing significant risks to security, performance, and user trust. Traditional manual code reviews, while valuable, often struggle to keep pace with the rapid development cycles and the sheer volume of code produced. This discrepancy underscores the necessity for automated solutions that can efficiently and accurately verify code properties, ensuring that software meets the highest standards of quality and reliability.
The integration of artificial intelligence (AI) into code verification processes offers promising solutions to these challenges. AI's capacity to analyze vast amounts of code data, identify patterns, and detect anomalies positions it as a powerful tool in automating code verification. By leveraging machine learning algorithms, AI can learn from existing codebases, understand coding standards, and apply this knowledge to new code, effectively identifying potential issues that might elude human reviewers. This capability not only enhances the accuracy of code verification but also accelerates the review process, allowing developers to focus on more complex and creative aspects of software development.
The significance of automating code verification through AI extends beyond mere efficiency gains. It plays a pivotal role in enhancing code quality by systematically identifying and rectifying errors, inconsistencies, and security vulnerabilities early in the development lifecycle. This proactive approach reduces the likelihood of defects reaching production environments, thereby improving the overall reliability and security of software applications. Moreover, automated code verification contributes to maintaining coding standards and best practices across development teams, fostering a culture of quality and continuous improvement within organizations.
The role of AI in this context is multifaceted. Beyond automating the detection of errors, AI can assist in refactoring code to enhance readability and maintainability, suggest optimizations for performance improvements, and ensure compliance with industry-specific regulations and standards. For instance, AI-powered tools can analyze code to detect security vulnerabilities, such as SQL injection risks or buffer overflows, and recommend or implement fixes, thereby strengthening the security posture of applications. Additionally, AI can facilitate the integration of new technologies and frameworks by ensuring that code adheres to the latest standards and practices, thereby future-proofing software systems.
The adoption of AI in code verification also addresses the growing demand for rapid software development and deployment. In today's fast-paced technological landscape, organizations are under pressure to release software updates and new features swiftly. Automated code verification powered by AI enables continuous integration and continuous deployment (CI/CD) pipelines to function more effectively, ensuring that code changes are verified and validated promptly. This capability not only accelerates time-to-market but also ensures that each release maintains a high standard of quality and security, thereby enhancing customer satisfaction and trust.
Furthermore, the integration of AI into code verification processes aligns with broader trends in the software industry towards automation and intelligent systems. As AI technologies advance, their application in software development becomes increasingly sophisticated, offering new opportunities for innovation and efficiency. The development of benchmarks like miniCodeProps exemplifies this trend, providing standardized frameworks to evaluate and enhance AI-driven code verification tools. Such initiatives not only advance the state of the art in automated code verification but also set the stage for future developments in AI-assisted software engineering.
In summary, automating code verification through AI is a transformative development in software engineering, addressing the challenges of complexity, speed, and quality in modern software development. By leveraging AI's capabilities, organizations can achieve higher levels of code quality, security, and efficiency, leading to more reliable and robust software systems. As the field continues to evolve, the integration of AI in code verification is poised to become an indispensable component of the software development lifecycle, driving innovation and excellence in the industry.
Background
Ensuring the correctness of code is a fundamental challenge in software development, as even minor errors can lead to significant issues, including security vulnerabilities, system failures, and financial losses. The complexities involved in code verification arise from several factors, including the increasing sophistication of software systems, the diversity of programming languages and paradigms, and the limitations of traditional verification methods.
One of the primary challenges in code verification is the inherent complexity of modern software systems. As applications become more intricate, with numerous interacting components and dependencies, verifying the correctness of each part becomes increasingly difficult. This complexity is further compounded by the use of various programming languages, each with its own syntax, semantics, and idiosyncrasies, making it challenging to develop universal verification methods that can be applied across different languages and platforms.
Traditional code verification methods, such as manual code reviews, static analysis, and testing, have been foundational in identifying and rectifying errors. Manual code reviews involve developers examining code to detect potential issues, relying on their expertise and experience. While this method can be effective, it is time-consuming and prone to human error, especially as codebases grow larger and more complex. Static analysis tools analyze code without executing it, identifying potential vulnerabilities and coding standard violations. However, static analysis may produce false positives or miss subtle errors, particularly in dynamic or complex code structures. Testing, including unit, integration, and system testing, is essential for verifying code behavior under various conditions. Despite its importance, testing cannot guarantee the absence of all errors, as it is often impractical to test every possible input and execution path.
Formal verification, which involves mathematically proving that a system adheres to its specifications, offers a more rigorous approach to code verification. However, formal verification is resource-intensive and requires specialized knowledge, making it less accessible for many development teams. Additionally, the scalability of formal methods remains a concern, as applying them to large and complex codebases can be challenging. The gap between the ideal of perfect code and the reality of practical software development highlights the limitations of current verification methods and the need for more effective solutions.
The advent of AI and machine learning presents new opportunities and challenges in code verification. While AI has the potential to automate and enhance verification processes, it also introduces complexities, such as ensuring the reliability of AI-generated code and addressing the potential for AI models to learn and propagate errors present in training data. The challenge of verifying AI-generated code underscores the need for robust verification frameworks that can handle the unique characteristics of AI systems.
In summary, the complexities involved in code verification stem from the intricate nature of modern software systems, the limitations of traditional verification methods, and the emerging challenges posed by AI technologies. Addressing these challenges requires the development of more sophisticated, scalable, and accessible verification techniques that can ensure the reliability and security of software in an increasingly complex technological landscape.
The integration of artificial intelligence (AI), particularly large language models (LLMs), into the code verification process represents a significant advancement in software engineering. LLMs, such as OpenAI's GPT series, have demonstrated remarkable capabilities in understanding and generating human-like text, which has been extended to the realm of code generation and verification. These models are being explored to automate various aspects of the verification process, aiming to enhance efficiency, accuracy, and scalability.
One of the primary applications of LLMs in code verification is their ability to generate code snippets based on natural language descriptions. This capability allows developers to specify desired functionalities in plain language, with the LLM translating these specifications into code. While this approach can expedite the development process, it also necessitates rigorous verification to ensure that the generated code aligns with the intended specifications and is free from errors.
To address this challenge, researchers have been developing methods to enhance the reliability of AI-generated code. For instance, the Clover paradigm, introduced by Stanford AI Lab, focuses on closed-loop verifiable code generation. This approach checks consistencies among code, docstrings, and annotations, enforcing correctness in AI-generated code. By ensuring that the generated code, its documentation, and annotations are consistent, Clover aims to improve the trustworthiness of AI-generated code.
Another significant development is the LEVER framework, which learns to verify language-to-code generation through execution. LEVER trains verifiers to determine the correctness of programs based on natural language input, the program itself, and its execution results. By combining verification scores with the LLM generation probability, LEVER enhances the accuracy of code generation, achieving state-of-the-art results across various datasets.
Despite these advancements, challenges remain in ensuring the reliability of AI-generated code. LLMs can sometimes produce code that appears plausible but fails to meet the expected requirements or executes incorrectly—a phenomenon known as "code hallucinations." To address this, researchers have proposed methods to detect and mitigate such hallucinations. For example, the CodeHalu benchmark categorizes code hallucinations into mapping, naming, resource, and logic types, providing a framework to understand and address these issues.
Furthermore, the integration of AI in code verification is not limited to code generation. LLMs are also being utilized to assist in debugging and code optimization. Tools like LDB (Large Language Model Debugger) enable LLMs to refine their generated programs using runtime execution information, facilitating the identification and correction of errors in the code.
The role of AI in code verification is continually evolving, with ongoing research aimed at improving the accuracy, efficiency, and reliability of AI-assisted verification processes. As AI models become more sophisticated, their integration into the software development lifecycle is expected to become more seamless, offering developers powerful tools to ensure the correctness and security of their code.
miniCodeProps Benchmark
The development of miniCodeProps represents a significant advancement in the field of automated code verification, particularly in the context of leveraging artificial intelligence (AI) to enhance the verification process. Recognizing the limitations of traditional verification methods, researchers at Carnegie Mellon University (CMU) introduced miniCodeProps as a benchmark designed to evaluate AI models, especially large language models (LLMs), in their capacity to prove code properties.
The primary purpose of miniCodeProps is to provide a standardized framework for assessing the effectiveness of AI-driven verification tools. By offering a diverse set of program specifications within the Lean proof assistant environment, miniCodeProps enables researchers and practitioners to test and compare the performance of various AI models in generating proofs for code properties. This initiative aims to bridge the gap between theoretical advancements in AI and practical applications in software verification, fostering the development of more robust and reliable verification tools.
In designing miniCodeProps, the researchers focused on creating a benchmark that balances simplicity with complexity. The benchmark comprises 177 program specifications covering a range of topics, including lists, natural numbers, and binary trees. These topics were selected to encompass a variety of proof difficulties, from straightforward properties to more intricate challenges. This design choice ensures that miniCodeProps can effectively evaluate the capabilities of AI models across different levels of complexity, providing insights into their strengths and limitations.
The creation of miniCodeProps also involved careful consideration of the Lean proof assistant's features and capabilities. By utilizing Lean, a widely used tool in formal verification, the researchers ensured that the benchmark aligns with established practices in the verification community. This alignment facilitates the integration of AI models into existing verification workflows, promoting the adoption of AI-assisted verification methods in real-world applications.
The introduction of miniCodeProps has already yielded valuable insights into the performance of current AI models in code verification tasks. Initial evaluations revealed that while some models achieved success rates of approximately 25% on certain specifications, they struggled with more complex tasks. For instance, models demonstrated lower success rates on properties related to termination and sorting algorithms. These findings highlight the challenges that AI models face in automating code verification and underscore the need for further research and development in this area.
In summary, miniCodeProps serves as a crucial tool in advancing the field of automated code verification. By providing a comprehensive and standardized benchmark, it enables the evaluation of AI models in proving code properties, thereby contributing to the development of more effective and reliable verification tools. As AI technologies continue to evolve, benchmarks like miniCodeProps will play an essential role in integrating AI into the software development lifecycle, enhancing the quality and security of software systems.
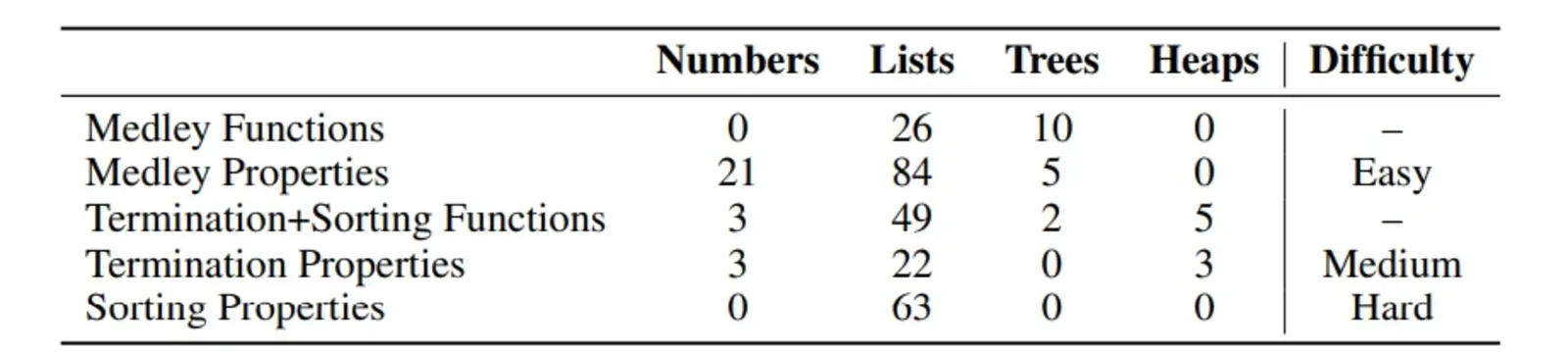
The miniCodeProps benchmark comprises 201 program specifications, each meticulously crafted to evaluate the capabilities of AI models in proving code properties. These specifications are categorized into three distinct difficulty levels: easy, medium, and hard, corresponding to the Medley, Termination, and Sorting categories, respectively. This structured approach ensures a comprehensive assessment of AI models across a spectrum of challenges, from straightforward properties to more complex verification tasks.
The Medley category encompasses intuitive properties of fundamental data structures such as lists, natural numbers, and binary trees. These properties are designed to be straightforward, serving as a baseline for evaluating the performance of AI models on simpler verification tasks. For instance, a typical specification in this category might involve proving the commutativity of a function on lists or verifying basic arithmetic properties of natural numbers. The simplicity of these tasks allows for a clear assessment of an AI model's ability to handle basic verification scenarios.
In contrast, the Termination category presents medium-difficulty challenges, focusing on proving termination properties of recursive functions. Termination proofs are crucial in formal verification, as they ensure that recursive functions do not result in infinite loops or unbounded recursion. Specifications in this category require AI models to demonstrate an understanding of recursive structures and the ability to reason about the conditions under which recursion will terminate. These tasks are more complex, requiring a deeper level of reasoning and a more sophisticated understanding of the underlying code structures.
The Sorting category represents the hardest level, involving properties of nonstandard sorting algorithms. Sorting algorithms are fundamental in computer science, and verifying their correctness is essential for ensuring reliable software systems. Specifications in this category challenge AI models to prove properties such as the stability of a sorting algorithm or its performance characteristics under various conditions. These tasks are particularly demanding, as they require a comprehensive understanding of algorithmic principles and the ability to reason about complex code behaviors.
Each specification within miniCodeProps is carefully designed to be self-contained, focusing on a single property or aspect of the code. This design choice ensures that the verification task is clear and unambiguous, allowing AI models to focus on the specific property being tested without the interference of extraneous factors. The self-contained nature of the specifications also facilitates the evaluation of AI models on individual properties, providing a granular assessment of their capabilities.
The inclusion of 201 specifications in the benchmark provides a robust dataset for evaluating AI models. This substantial number allows for a comprehensive assessment of a model's performance across a wide range of tasks, ensuring that the evaluation is both thorough and representative of the challenges encountered in real-world code verification scenarios. The diversity of the specifications, spanning different data structures and levels of complexity, ensures that the benchmark provides a holistic evaluation of an AI model's verification capabilities.
In summary, the miniCodeProps benchmark offers a structured and comprehensive framework for evaluating AI models in the context of code verification. By categorizing specifications into three levels of difficulty and focusing on self-contained properties, it provides a clear and effective means of assessing the performance of AI models across a spectrum of verification tasks. This approach not only facilitates the evaluation of current AI models but also serves as a valuable resource for guiding future research and development in the field of automated code verification.
The miniCodeProps benchmark is meticulously structured into three distinct categories, each designed to evaluate specific aspects of code verification through varying levels of complexity. These categories—Medley, Termination, and Sorting—encompass a total of 201 program specifications, providing a comprehensive framework for assessing AI models in proving code properties.
The Medley category comprises intuitive properties of fundamental data structures such as lists, natural numbers, and binary trees. These properties are designed to be straightforward, serving as a baseline for evaluating the performance of AI models on simpler verification tasks. For instance, a typical specification in this category might involve proving the commutativity of a function on lists or verifying basic arithmetic properties of natural numbers. The simplicity of these tasks allows for a clear assessment of an AI model's ability to handle basic verification scenarios.
In contrast, the Termination category presents medium-difficulty challenges, focusing on proving termination properties of recursive functions. Termination proofs are crucial in formal verification, as they ensure that recursive functions do not result in infinite loops or unbounded recursion. Specifications in this category require AI models to demonstrate an understanding of recursive structures and the ability to reason about the conditions under which recursion will terminate. These tasks are more complex, requiring a deeper level of reasoning and a more sophisticated understanding of the underlying code structures.
The Sorting category represents the hardest level, involving properties of nonstandard sorting algorithms. Sorting algorithms are fundamental in computer science, and verifying their correctness is essential for ensuring reliable software systems. Specifications in this category challenge AI models to prove properties such as the stability of a sorting algorithm or its performance characteristics under various conditions. These tasks are particularly demanding, as they require a comprehensive understanding of algorithmic principles and the ability to reason about complex code behaviors.
Each specification within miniCodeProps is carefully designed to be self-contained, focusing on a single property or aspect of the code. This design choice ensures that the verification task is clear and unambiguous, allowing AI models to focus on the specific property being tested without the interference of extraneous factors. The self-contained nature of the specifications also facilitates the evaluation of AI models on individual properties, providing a granular assessment of their capabilities.
The inclusion of 201 specifications in the benchmark provides a robust dataset for evaluating AI models. This substantial number allows for a comprehensive assessment of a model's performance across a wide range of tasks, ensuring that the evaluation is both thorough and representative of the challenges encountered in real-world code verification scenarios. The diversity of the specifications, spanning different data structures and levels of complexity, ensures that the benchmark provides a holistic evaluation of an AI model's verification capabilities.
In summary, the miniCodeProps benchmark offers a structured and comprehensive framework for evaluating AI models in the context of code verification. By categorizing specifications into three levels of difficulty and focusing on self-contained properties, it provides a clear and effective means of assessing the performance of AI models across a spectrum of verification tasks. This approach not only facilitates the evaluation of current AI models but also serves as a valuable resource for guiding future research and development in the field of automated code verification.
Evaluation and Results
The evaluation of AI models on the miniCodeProps benchmark employs two primary methodologies: full-proof generation and tactic-by-tactic generation. These approaches are designed to assess the capabilities of AI systems in automating the proof generation process within the Lean proof assistant environment.
In the full-proof generation approach, the AI model is tasked with producing a complete proof for a given program specification. This method involves the model generating one or more potential proofs, which are then verified by the Lean 4 kernel. The verification process checks the validity of each proof, ensuring that it adheres to the logical and syntactical rules of the Lean proof assistant. If any of the generated proofs are valid, the specification is considered successfully proven. This approach allows for a comprehensive evaluation of the AI model's ability to generate complete and correct proofs without incremental guidance. However, it may be computationally intensive, as it requires the model to produce entire proofs in a single generation.
Alternatively, the tactic-by-tactic generation approach involves the AI model suggesting individual proof steps, known as tactics, which are then executed by the Lean 4 kernel. Each tactic modifies the current proof state, and the resulting state is used to prompt the model for the next tactic. This process continues iteratively until the proof is complete or a predefined computational budget is exhausted. This method mirrors the interactive theorem proving process, where human users incrementally build proofs through a series of logical steps. It allows for a more granular assessment of the AI model's reasoning capabilities and its ability to navigate the proof landscape step by step. Additionally, this approach can be more efficient, as it focuses on generating one proof step at a time, potentially reducing the computational resources required compared to full-proof generation.
Both methodologies are evaluated within the context of the miniCodeProps benchmark, which consists of 201 program specifications categorized into three levels of difficulty: easy (Medley), medium (Termination), and hard (Sorting). These categories encompass a range of proof challenges, from straightforward properties of basic data structures to complex properties of nonstandard sorting algorithms. The benchmark provides a standardized framework for assessing the performance of AI models in code verification tasks, facilitating comparisons across different models and approaches.
The evaluation results indicate that while current AI models demonstrate some success on the easier Medley properties, they encounter significant challenges with the more complex Termination and Sorting properties. This highlights the need for further research and development to enhance the capabilities of AI systems in automated code verification. The findings underscore the importance of developing specialized models and training methodologies tailored to the unique demands of code verification tasks.
In the evaluation of AI models on the miniCodeProps benchmark, current Large Language Model (LLM)-based provers have demonstrated a success rate of approximately 25% in proving the provided program specifications. This performance varies across different categories of difficulty. Specifically, these models have shown promise in the Medley category, which includes intuitive properties of basic data structures such as lists, natural numbers, and binary trees. However, they encounter significant challenges with the more complex specifications in the Termination and Sorting categories. The Termination category focuses on proving termination properties of recursive functions, while the Sorting category involves properties of nonstandard sorting algorithms. These findings underscore the need for further research and development to enhance the capabilities of AI systems in automated code verification.
Implications and Future Directions
The miniCodeProps benchmark has significantly advanced the field of automated theorem proving, particularly in the context of code verification. By providing a structured and accessible set of 201 program specifications, it has enabled researchers and practitioners to systematically evaluate and compare the performance of various AI models, including large language models (LLMs), in automating the proof generation process. This benchmark has illuminated the current capabilities and limitations of AI systems in the realm of code verification, offering valuable insights into areas where further development is needed.
One of the key contributions of miniCodeProps is its role in highlighting the challenges that AI models face when tasked with verifying code properties. Despite the simplicity of the benchmark, current LLM-based provers have demonstrated a success rate of approximately 25% in proving the specifications. This outcome underscores the complexity inherent in code verification tasks and the necessity for specialized models and training methodologies tailored to this domain. The benchmark's design, encompassing a range of difficulty levels and focusing on self-contained properties, has been instrumental in revealing these challenges.
Furthermore, miniCodeProps has spurred discussions and research aimed at enhancing the performance of AI models in code verification. The benchmark has served as a catalyst for developing new approaches and techniques to improve the accuracy and efficiency of automated theorem proving systems. By providing a standardized framework for evaluation, miniCodeProps has facilitated the identification of specific areas where AI models can be improved, such as handling more complex proof structures and reasoning about intricate code behaviors.
In addition to its role in advancing AI capabilities, miniCodeProps has also contributed to the broader field of formal verification. By demonstrating the potential of AI in automating aspects of the verification process, the benchmark has opened avenues for integrating AI-driven tools into existing verification workflows. This integration has the potential to reduce the manual effort required in code verification, making the process more accessible and efficient. The insights gained from evaluating AI models on miniCodeProps can inform the development of hybrid systems that combine the strengths of human expertise with the computational power of AI, leading to more robust and reliable software systems.
The integration of artificial intelligence (AI) into code verification processes holds transformative potential for the software development industry. By automating aspects of code verification, AI can enhance efficiency, reduce human error, and accelerate the development lifecycle. However, realizing this potential requires addressing several significant challenges.
One of the primary challenges is ensuring the accuracy and reliability of AI-generated code. While AI models, particularly large language models (LLMs), have demonstrated proficiency in generating code snippets, they often lack the nuanced understanding required for complex verification tasks. This limitation can lead to the generation of code that is syntactically correct but semantically flawed, posing risks to software reliability and security. For instance, AI-generated code may inadvertently introduce vulnerabilities or fail to adhere to established coding standards, necessitating rigorous validation and testing procedures.
Another significant concern is the ethical implications of AI in code verification. AI models are trained on vast datasets that may contain biases, which can be inadvertently incorporated into the generated code. This issue raises questions about the fairness and inclusivity of AI-generated solutions. Addressing these ethical considerations requires the development of AI models that are transparent, interpretable, and subject to rigorous ethical standards to ensure that the code they produce is equitable and free from unintended biases.
Data privacy and security also present significant challenges. Integrating AI into code verification processes often necessitates access to sensitive data, raising concerns about data confidentiality and the potential for breaches. Implementing robust security measures and ensuring compliance with data protection regulations are essential to mitigate these risks. For example, in sectors like healthcare, where data sensitivity is paramount, AI systems must adhere to strict data protection standards to prevent unauthorized access and ensure patient confidentiality.
Furthermore, the computational demands of AI models pose practical challenges. The processing power required for training and deploying advanced AI models can be substantial, leading to increased costs and resource consumption. This issue is particularly pertinent for organizations with limited computational resources, potentially hindering the widespread adoption of AI in code verification. Developing more efficient algorithms and leveraging cloud-based solutions may help alleviate some of these concerns.
Despite these challenges, the future integration of AI in code verification processes offers promising avenues for innovation. Advancements in AI research are continually addressing these issues, leading to the development of more robust, ethical, and efficient AI models. For instance, recent studies have explored the use of AI in automating the repair of AI-generated code, demonstrating the potential for AI to enhance its own verification processes.
Conclusion
The miniCodeProps benchmark, introduced by researchers at Carnegie Mellon University, represents a significant advancement in the field of automated theorem proving, particularly concerning code verification. This benchmark comprises 201 program specifications within the Lean proof assistant, encompassing a diverse array of simple, self-contained programs such as lists, natural numbers, and binary trees. The specifications are categorized into three levels of difficulty: easy (Medley), medium (Termination), and hard (Sorting), each presenting unique challenges for automated verification systems.
The primary objective of miniCodeProps is to evaluate the capabilities of AI models, especially large language models (LLMs), in automating the proof generation process for code properties. By providing a standardized set of problems, miniCodeProps enables researchers to assess the performance of various AI systems in a consistent manner, facilitating comparisons and identifying areas for improvement. The benchmark's design reflects the complexities inherent in code verification tasks, offering insights into the current state of AI in this domain and highlighting the need for specialized models and training methodologies tailored to code verification.
Evaluations conducted using miniCodeProps have revealed that current LLM-based provers achieve a success rate of approximately 25% in proving the specifications. Performance varies across the different difficulty levels, with models demonstrating higher success rates on the easier Medley properties and lower success rates on the more complex Termination and Sorting properties. These findings underscore the challenges AI models face in automating code verification and highlight the necessity for further research to enhance their capabilities.
In summary, miniCodeProps serves as a valuable benchmark for advancing automated theorem proving in code verification. It provides a structured framework for evaluating AI models, offering insights into their strengths and limitations. The benchmark's focus on simple, self-contained programs with varied proof difficulties makes it an effective tool for driving progress in the development of AI-driven code verification systems. By identifying areas where AI models excel and where they encounter challenges, miniCodeProps contributes to the ongoing efforts to improve the efficiency and reliability of automated code verification processes.
The integration of artificial intelligence (AI) into code verification processes has the potential to revolutionize software development by enhancing efficiency, accuracy, and reliability. AI-driven tools can automate the detection and correction of defects, thereby reducing manual intervention and accelerating the development lifecycle. For instance, AI-powered testing frameworks can autonomously identify and rectify defects, ensuring that applications function correctly and meet quality standards.
However, realizing the full potential of AI in code verification requires addressing several challenges. Ensuring the accuracy and reliability of AI-generated code is paramount, as AI models may produce code that is syntactically correct but semantically flawed, leading to potential vulnerabilities and errors. Additionally, ethical considerations, such as mitigating biases in AI-generated code and ensuring transparency and interpretability of AI models, are crucial to prevent unintended consequences and maintain trust in AI systems. Data privacy and security concerns also arise, as integrating AI into code verification processes may necessitate access to sensitive data, requiring robust security measures and compliance with data protection regulations. Furthermore, the computational demands of AI models can be substantial, posing practical challenges for organizations with limited resources.
Despite these challenges, recent advancements demonstrate the promising future of AI in code verification. For example, Google has introduced an experimental AI-powered code agent named "Jules," designed to automatically fix coding errors for developers. This tool aims to handle time-consuming tasks, allowing developers to focus on building projects.
To fully harness the benefits of AI in code verification, it is imperative to invest in research and development that addresses these challenges. Collaboration among researchers, industry professionals, and policymakers is essential to develop AI models that are accurate, ethical, secure, and efficient. By fostering an environment that encourages innovation and addresses the complexities associated with AI integration, we can pave the way for more robust and reliable software systems.
In conclusion, while the integration of AI into code verification processes presents several challenges, it also offers significant opportunities to enhance the efficiency and reliability of software development. Addressing issues related to accuracy, ethics, data privacy, and computational demands is crucial for the successful adoption of AI in this domain. Ongoing research and development efforts are essential to overcome these challenges and fully realize the benefits of AI in code verification.
References
For readers interested in delving deeper into the intersection of artificial intelligence and code verification, several seminal works offer valuable insights. The foundational research on the miniCodeProps benchmark, titled "miniCodeProps: a Minimal Benchmark for Proving Code Properties," provides an in-depth exploration of the benchmark's design, objectives, and initial findings. This paper is accessible on arXiv and offers a comprehensive overview of the challenges and opportunities in automating code verification through AI.
In addition to the miniCodeProps study, the paper "AI-Assisted Assessment of Coding Practices in Modern Code Review" presents a system called AutoCommenter, which leverages large language models to automatically learn and enforce coding best practices across multiple programming languages. This research highlights the practical applications of AI in enhancing code quality and developer workflows.
For a broader perspective on the impact of AI models on software security, the systematic literature review "A Systematic Literature Review on the Impact of AI Models on the Security of Software and Systems" offers a critical examination of how AI-generated code influences software security. This review synthesizes existing research, providing a comprehensive understanding of the risks and benefits associated with AI in coding security-critical software.
Furthermore, the article "The Challenge of Verifying AI-Generated Code" discusses the complexities developers face when verifying code produced by AI tools. It explores recent academic research and proposes innovative solutions to address these challenges, offering practical insights for professionals in the field.
Collectively, these works offer a multifaceted view of the current landscape in AI-driven code verification, encompassing theoretical foundations, practical applications, security considerations, and verification challenges. Engaging with these resources will provide a deeper understanding of the ongoing research and developments in this dynamic field.
Press contact
Timon Harz
oneboardhq@outlook.com
Other posts





Company
About
Blog
Careers
Press
Legal
Privacy
Terms
Security