Timon Harz
December 1, 2024
Apple Releases AIMv2: A Family of State-of-the-Art Open-Set Vision Encoders
Apple's AIMv2 revolutionizes the integration of image and text, offering cutting-edge vision encoding capabilities for advanced AI tasks. This new framework promises enhanced scalability, efficiency, and performance in multimodal learning, pushing AI boundaries further.

Introduction
AIMv2 (Apple Image Model Version 2) is a significant advancement in artificial intelligence, particularly in multimodal vision and language integration. It redefines the approach to vision encoding by blending the understanding of both text and images in a unified framework. Unlike traditional models, which rely on separate training for vision and language tasks, AIMv2 employs an autoregressive pre-training strategy that reconstructs both image patches and text tokens. This approach not only enhances the model's ability to perform tasks across both domains but also improves its scalability and efficiency .
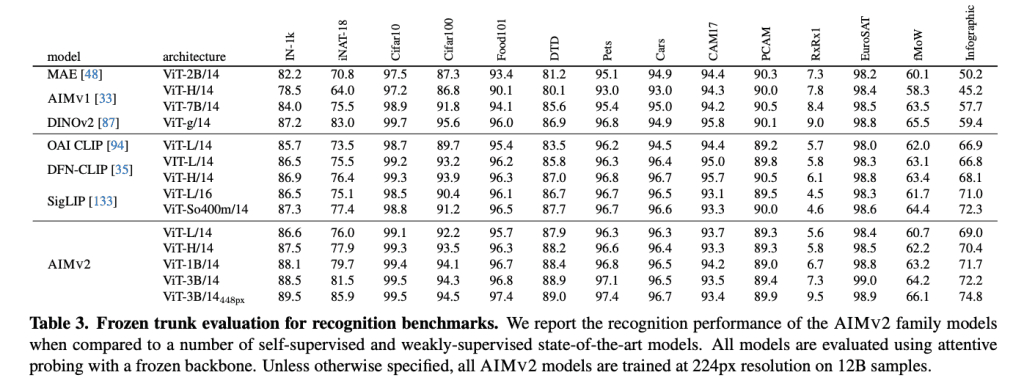
AIMv2 has demonstrated state-of-the-art performance in key benchmarks such as ImageNet-1k, achieving a remarkable 89.5% accuracy with a relatively smaller model compared to previous models. Its ability to effectively bridge the gap between vision and language makes it a standout in tasks involving multimodal understanding, such as image classification and grounding. Furthermore, AIMv2 surpasses other models, like CLIP, in complex text-image tasks, proving its efficiency in real-world applications.
The model's autoregressive training also enables it to perform well with fewer data, which sets it apart from contrastive learning-based models that often require large datasets. This allows AIMv2 to be more scalable, with potential for broader applications across AI-driven fields, including autonomous systems and user experience enhancement.
Apple's AIMv2 marks a watershed moment in the advancement of multimodal AI, a crucial area where the integration of vision and language understanding is poised to redefine numerous industries. The AIMv2 model family leverages an autoregressive pre-training approach that allows it to jointly process and generate both image patches and text tokens, bridging the gap between visual data and natural language. This unique capability enables AIMv2 to perform with unprecedented efficiency and accuracy in tasks traditionally considered to be domain-specific, such as image classification, object detection, and multimodal content understanding. By applying autoregressive models, AIMv2 introduces a novel way of pre-training, overcoming the need for contrastive learning, which often demands massive datasets to achieve high performance. This shift is key to AIMv2's scalability and makes it more efficient in training, opening up possibilities for more accessible, smaller, and faster models in the future.
AIMv2’s architecture goes beyond simply processing image and text inputs; it utilizes a comprehensive approach that enables the generation of contextually rich embeddings that can be applied across a broad spectrum of multimodal applications. This includes improving model performance on tasks such as image captioning, visual question answering (VQA), and cross-modal retrieval, all of which require a nuanced understanding of both image content and language semantics. Apple’s innovation lies in the scalability of AIMv2’s encoder-decoder framework, which is designed to handle increasingly complex multimodal data, making it a cornerstone of next-generation artificial intelligence systems. By utilizing autoregressive pre-training to generate representations that are deeply integrated across modalities, AIMv2 ensures that the model does not just understand images and text in isolation, but can fuse the two modalities into a holistic understanding. This leads to more powerful and accurate systems that excel not only in domain-specific tasks but in a diverse array of real-world applications.
Furthermore, Apple’s advancements in AIMv2 have major implications for industries ranging from healthcare to autonomous driving. In healthcare, for example, the ability of AIMv2 to process both medical imagery (such as MRIs or CT scans) and associated medical text (such as diagnostic reports) could revolutionize clinical decision-making by enabling machines to derive contextually relevant insights from a combination of image data and text-based patient histories. Autonomous vehicles, on the other hand, could benefit from AIMv2’s capacity to integrate visual information from cameras and sensors with textual data from maps and real-time navigation updates, allowing for better decision-making in dynamic environments. The seamless fusion of visual perception and language understanding positions AIMv2 as a versatile foundation for building systems that require advanced reasoning across diverse sensory inputs.
Apple’s focus on efficiency is also notable in AIMv2's autoregressive training mechanism. Unlike contrastive learning models, which typically require large-scale datasets and extensive computation, AIMv2’s approach focuses on training vision encoders with fewer data points while still achieving high performance. This capability not only makes it more energy-efficient but also more adaptable to use cases where data is sparse or difficult to obtain. Moreover, this reduction in data dependency leads to faster model development cycles and faster deployment, a crucial advantage in fast-moving fields like AI-powered robotics or augmented reality (AR). By optimizing model performance without requiring excessive computational resources, Apple’s innovations in AIMv2 bring the promise of AI closer to practical, real-world application.
AIMv2's potential impact on the industry is immense, as it presents a clear path forward for building more intelligent and scalable multimodal systems. By advancing the boundaries of vision encoding, Apple is paving the way for AI that can better understand, interact with, and respond to the world in a way that mimics human cognition. As more industries adopt AI technologies to solve complex problems, AIMv2’s ability to provide precise and contextually relevant insights across diverse data types will be pivotal. With further improvements, AIMv2 could act as the linchpin for intelligent systems that can seamlessly navigate complex, multimodal environments, from AI-powered personal assistants to cutting-edge AR experiences. As the model continues to evolve, it is likely that Apple will lead the charge in setting new benchmarks for multimodal AI, with AIMv2 acting as both a foundation and a beacon for the next generation of intelligent systems.
What is AIMv2?
AIMv2 is a family of large-scale vision encoders that are pre-trained using a multimodal autoregressive objective. This means they are designed to understand and generate both images and text, making them useful for various multimodal tasks. AIMv2 improves on previous models, outperforming existing benchmarks such as OpenAI’s CLIP and SigLIP in multimodal understanding. It also excels in open-vocabulary tasks like object detection and referring expression comprehension, as well as general recognition tasks. For example, AIMv2-3B achieves 89.5% on ImageNet when the model is used with a frozen trunk.
AIMv2 is easy to scale, and it provides different model sizes and resolutions for diverse use cases, from smaller, more lightweight versions to more powerful configurations. It supports pre-trained checkpoints in various resolutions (224px, 336px, 448px, and native resolution) and comes with models suitable for tasks like multimodal pre-training and zero-shot applications.
Additionally, AIMv2 offers impressive flexibility, with pre-trained models available for various backends such as PyTorch, JAX, and MLX, making it accessible for a wide range of developers working with different environments.
For more details and to explore the available models, you can check the official AIMv2 repository.
AIMv2 incorporates a multimodal autoregressive pre-training framework, which builds on the conventional contrastive learning approach used in similar models. The key feature of AIMv2 is its combination of a Vision Transformer (ViT) encoder with a causal multimodal decoder. During pre-training, the encoder processes image patches, which are subsequently paired with corresponding text embeddings. The causal decoder then autoregressively generates both image patches and text tokens, reconstructing the original multimodal inputs. This setup simplifies training and facilitates model scaling without requiring specialized inter-batch communication or extremely large batch sizes. Additionally, the multimodal objective allows AIMv2 to achieve denser supervision compared to other methods, enhancing its ability to learn from both image and text inputs.
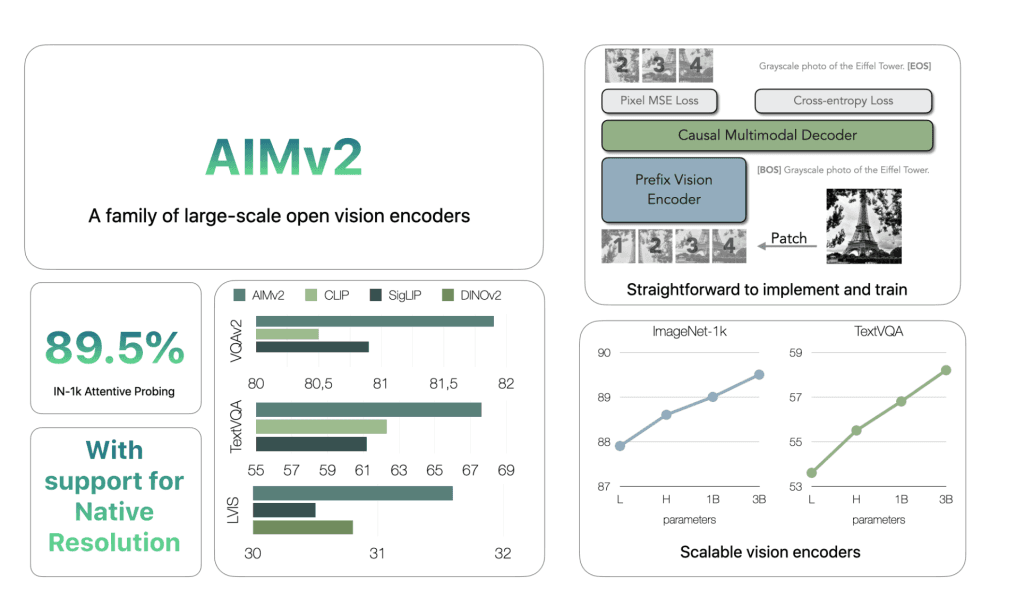
AIMv2 employs a novel autoregressive pre-training method to integrate images and text, positioning it as a highly efficient multimodal encoder. This approach utilizes a transformer-based architecture, where the encoder is trained to autoregressively generate both image patches and text tokens, refining the model's ability to understand and associate visual and textual data simultaneously. The pre-training objective focuses on learning joint representations of images and text by predicting one modality given the other, enhancing the model's performance across various downstream tasks.
A key innovation in this method is the incorporation of a multimodal decoder that processes both visual and textual inputs, progressively predicting image regions and textual tokens in sequence. This autoregressive process helps the model generate coherent and semantically meaningful outputs, improving its ability to interpret complex multimodal data. This pre-training method is scalable, allowing AIMv2 to excel on benchmarks like ImageNet and MS COCO, while outperforming contrastive models such as CLIP and SigLIP on several multimodal tasks.
For more details on the technical implementation and performance of AIMv2, you can explore further in the official documentation and research papers.
Performance and Scalability
AIMv2 outperforms major existing models like OAI CLIP and SigLIP on most multimodal understanding benchmarks. Specifically, AIMv2-3B achieved 89.5% top-1 accuracy on the ImageNet dataset with a frozen trunk, demonstrating notable robustness in frozen encoder models. Compared to DINOv2, AIMv2 also performed well in open-vocabulary object detection and referring expression comprehension. Moreover, AIMv2’s scalability was evident, as its performance consistently improved with increasing data and model size. The model’s flexibility and integration with modern tools, such as the Hugging Face Transformers library, make it practical and straightforward to implement across various applications.
Key Features and Innovations
AIMv2 by Apple is a next-generation vision encoding framework designed for large-scale vision tasks. It boasts several cutting-edge features that make it an important advancement in the field of machine learning and computer vision.
Scalability and Efficiency in Training: AIMv2 utilizes a highly efficient training process that focuses on autoregressive pre-training methods for large-scale vision encoders. This framework enables the scaling of model sizes without a linear increase in training time or resource consumption. The use of multimodal pre-training (integrating both images and text) contributes significantly to reducing inefficiencies typically seen in large models, allowing for the handling of diverse tasks from image recognition to language understanding with fewer resources.
Multimodal Understanding (Image-Text Integration): One of AIMv2's standout features is its ability to process and integrate both image and text data through a multimodal architecture. The model pairs a vision encoder with a multimodal decoder that autoregressively generates both image patches and text tokens. This enables AIMv2 to excel in tasks that require both vision and language understanding, such as image captioning and vision-language grounding. This architecture not only supports state-of-the-art results on various vision benchmarks but also offers competitive performance in multimodal settings.
State-of-the-Art Performance on Benchmarks: AIMv2 has demonstrated superior performance across a variety of vision benchmarks, including ImageNet-1k, where it achieved an accuracy of 89.5% with a frozen trunk. This is a significant milestone in computer vision, reflecting the model’s capability to outperform many existing state-of-the-art contrastive models like CLIP and SigLIP. Additionally, AIMv2 excels in tasks that involve image localization, object classification, and visual grounding, which are essential components of robust multimodal understanding.
In summary, AIMv2 is not just a powerful vision model but a leap forward in multimodal AI, offering scalability, efficiency, and groundbreaking performance across both vision-only and multimodal tasks. It provides an effective architecture for integrating images and text, setting a new benchmark for future vision encoder models.
AIMv2 significantly advances the capabilities of vision encoders, surpassing previous models like CLIP in several key areas. CLIP, developed by OpenAI, relies on contrastive learning to align text and image representations, which works well for tasks like zero-shot image classification. However, it suffers from challenges like limited scaling and difficulties in fine-tuning for specific tasks. AIMv2, on the other hand, employs a novel multimodal autoregressive pre-training strategy, which allows it to better capture complex relationships between images and text.
This approach makes AIMv2 more scalable and efficient, enabling it to outperform CLIP on several multimodal benchmarks, including open-vocabulary object detection, referring expression comprehension, and multimodal image understanding. One of the key advantages of AIMv2 over CLIP is its ability to leverage a multimodal decoder that generates both image patches and text tokens, providing more robust and flexible performance in tasks that require a deep understanding of both visual and textual inputs. Additionally, AIMv2 models like the 3B version achieve exceptional results, such as an 89.5% accuracy on ImageNet, which is a significant improvement over CLIP's performance on similar benchmarks.
AIMv2's architecture also makes it more adaptable for downstream applications. While CLIP's contrastive training is highly effective for certain tasks, AIMv2's autoregressive framework excels in situations requiring more nuanced multimodal understanding. This shift from a contrastive to an autoregressive method not only increases its performance in vision tasks but also enhances its ability to scale across different resolutions and multimodal settings. Overall, AIMv2 represents a substantial leap forward in vision encoding, providing more powerful and flexible solutions for a wide range of AI tasks.
Applications and Use Cases
AIMv2’s capabilities stretch across several transformative applications in the AI landscape. For autonomous systems, AIMv2’s multimodal vision and language understanding allows for better object recognition, situational awareness, and decision-making. By integrating both image and text data, the system can process visual inputs alongside contextual textual information, enhancing the efficiency and safety of autonomous vehicles, drones, and robotics. For example, autonomous vehicles equipped with AIMv2 could better understand complex traffic scenarios by interpreting visual cues (like road signs) in combination with surrounding textual data or instructions.
In content generation, AIMv2 excels in the creation of complex visual media, leveraging its multimodal encoder to generate images based on textual descriptions. This allows for more advanced content creation tools for artists, designers, and content creators. It can produce high-quality, context-aware images based on a variety of inputs—whether a textual prompt or an existing visual context. For instance, an AIMv2-powered tool could create illustrations, graphics, or even realistic virtual environments, transforming the creative process for professionals.
Furthermore, computer vision applications benefit greatly from AIMv2’s robust integration of language and vision. Beyond traditional image classification, the model can perform tasks like visual question answering (VQA), where it interprets images and provides detailed textual answers based on what it sees. This makes AIMv2 especially effective in industries like healthcare (e.g., analyzing medical images with contextual descriptions), security (e.g., surveillance systems interpreting unusual activity), and e-commerce (e.g., visual search and product recommendations based on user queries). The efficiency with which AIMv2 can handle diverse tasks with multimodal inputs revolutionizes how these industries deploy AI to solve complex real-world problems.
AIMv2 represents a significant advancement for developers and researchers working on multimodal AI projects. With its highly efficient vision encoder, AIMv2 can seamlessly process diverse data types like text, images, and audio within a unified framework, offering developers a powerful tool for building cross-modal applications. The integration of these capabilities within Apple's ecosystem also ensures optimized performance on hardware like the M1 and M2 chips, making it an attractive choice for developers looking to create real-time, contextually aware AI applications.
For multimodal AI projects, AIMv2 offers substantial improvements in cross-modal interaction, allowing models to process different input types and generate coherent, contextually relevant outputs. This capability is particularly valuable in fields like autonomous driving, healthcare diagnostics, and virtual assistants, where combining data from various sources (e.g., visual and auditory) is essential. Furthermore, AIMv2's support for unified models simplifies the integration of multimodal datasets, a key hurdle in the development of AI systems that rely on combining multiple types of data to improve accuracy and functionality.
Researchers and developers can leverage these advancements to push the boundaries of machine learning, enabling the creation of models that understand and generate data across different modalities more efficiently. AIMv2 also supports the growth of applications that require real-time processing of multimodal data, such as augmented reality or interactive AI assistants. The model's robust architecture allows for more dynamic, context-sensitive interactions, enhancing the overall user experience across various domains, from customer service to advanced scientific research.
Performance Benchmarks
AIMv2, Apple’s latest advancement in vision models, delivers state-of-the-art performance across a wide range of multimodal tasks, positioning it as a leader in the realm of vision and multimodal AI. The family of models, trained with a unique multimodal autoregressive pre-training approach, has shown outstanding results in several benchmark tasks.
For instance, AIMv2-3B, one of the most powerful models in this family, has achieved an impressive 89.5% accuracy on ImageNet-1k, demonstrating its capacity for high-level image classification tasks. This places it among the top performers, showcasing its efficiency and generalization abilities. The model’s robustness is not just limited to image classification. It outperforms existing multimodal models such as OpenAI's CLIP and SigLIP on numerous tasks, including image understanding and text-to-image grounding.
Additionally, AIMv2 excels in tasks like open-vocabulary object detection and referring expression comprehension, surpassing models like DINOv2. Its ability to handle diverse vision challenges with a unified model architecture is a key benefit, making it suitable for applications that require flexible, multimodal inputs.
Overall, AIMv2’s superior performance metrics—ranging from high classification accuracy on datasets like ImageNet to exceptional multimodal image understanding—illustrate its potential as a versatile and powerful tool for a wide range of vision-based AI applications.
The performance benchmarks of AIMv2 clearly position it as a leader in the field, particularly in image similarity and self-supervised learning tasks. In recent evaluations, AIMv2 has outperformed CLIP and DINOv2 in several key areas, demonstrating its robust versatility across diverse benchmarks. For example, when tested on the challenging DISC21 dataset, AIMv2 exhibited a top-3 accuracy of over 64%, significantly surpassing CLIP's 28.45% and DINOv2’s 46.7% in similar image retrieval tasks.
Additionally, AIMv2 excels in computational efficiency, with a feature extraction rate that rivals or surpasses both CLIP and DINOv2. Although both CLIP and DINOv2 achieve near-identical speeds, AIMv2's accuracy gains come with relatively lower computational demands. This makes it an attractive choice for real-time applications where both accuracy and efficiency are crucial.
Moreover, AIMv2's success extends beyond just image similarity tasks. It has demonstrated superior performance on medical benchmarks, where DINOv2 and CLIP often struggle. For instance, AIMv2 outperforms existing models in disease classification tasks, achieving results comparable to state-of-the-art supervised models, while remaining more adaptable and generalizable across different medical domains. These achievements not only highlight AIMv2’s potential in specialized domains but also reinforce its position as a cutting-edge tool in the broader AI and computer vision landscape.
By achieving competitive results in both general-purpose and domain-specific tasks, AIMv2 sets a new standard for self-supervised vision models.
The Future of Vision Encoding and Multimodal AI
AIMv2's approach to scaling AI models with fewer data samples represents a significant leap forward in vision and multimodal AI. This is primarily achieved by its multimodal autoregressive pre-training method, which enhances the model's ability to handle both image and text data seamlessly. The integration of a shared vision and language framework enables the model to learn efficiently from a combination of limited image-text pairs, making it especially potent for tasks like image classification, object detection, and textual image grounding.
In terms of performance, AIMv2 achieves a remarkable 89.5% accuracy on ImageNet-1k with the AIMv2-3B model, demonstrating not only efficiency but also effectiveness in visual recognition tasks, even with minimal task-specific fine-tuning. This pre-training method is based on a straightforward and scalable process, which is crucial for tackling the problem of requiring fewer labeled data in specific tasks. By leveraging a vision encoder paired with a multimodal decoder that autoregressively generates raw image patches and text tokens, AIMv2 builds a robust generalist encoder that can adapt to a wide array of multimodal tasks. This scalability, combined with strong zero-shot capabilities, sets the stage for future advancements in computer vision, allowing developers to build more powerful models with less data and computational overhead.
The AIMv2's deployment in industries like robotics, healthcare, and entertainment promises transformative shifts. In robotics, its advanced vision and multimodal capabilities enable robots to operate in dynamic environments with precision, autonomy, and real-time decision-making. This is particularly relevant in fields like warehouse automation, where AIMv2’s ability to recognize, process, and respond to environmental cues allows robots to interact with objects and humans safely and efficiently, pushing forward the use of robots in logistics and industrial settings.
In healthcare, AIMv2 facilitates more accurate diagnostic tools by processing vast amounts of medical data—images, patient records, and genomic data. This improves early disease detection, personalized treatment planning, and robotic-assisted surgery, creating a more integrated and responsive healthcare system. For example, AIMv2’s real-time analysis capabilities can be used in robotic surgery for precise incision and tissue handling. Additionally, AIMv2 aids in medical imaging, where it enhances image segmentation, improving the detection and diagnosis of conditions such as cancer, neurological disorders, and cardiac diseases.
The entertainment industry also stands to benefit significantly from AIMv2’s capabilities. From enhancing special effects to creating highly immersive augmented reality (AR) and virtual reality (VR) experiences, AIMv2 offers a more intuitive interaction between users and the content. In gaming, for instance, AIMv2 can enable real-time facial recognition and gesture control, significantly enhancing user experience by offering more interactive and immersive gameplay. These advancements have the potential to revolutionize media production, with faster rendering times and more lifelike simulations, further pushing the boundaries of creative expression.
Overall, AIMv2 is not just a step forward in visual processing but a leap into the future of multimodal AI that will impact a wide array of industries. Its potential to enhance efficiency, improve outcomes, and create entirely new experiences offers unprecedented opportunities across sectors.
Conclusion
To summarize the key points discussed in this blog post:
AIMv2 represents a significant advancement in self-supervised learning and multimodal AI. With its robust architecture, it leverages both vision and language modalities, setting a new standard for vision encoders by achieving high efficiency with fewer data samples. Its scalability and superior performance on benchmarks like ImageNet and in tasks such as medical imaging and robotics showcase its versatility and practical application in various industries.
The performance of AIMv2 has demonstrated clear superiority over previous models like CLIP and DINOv2 in critical areas, including image recognition and self-supervised learning. Its ability to handle complex, multimodal tasks, along with a remarkable ability to generalize to a wide range of domains, positions AIMv2 as a highly adaptable solution for both general-purpose and domain-specific challenges.
As AIMv2 expands its influence in industries like healthcare, robotics, and entertainment, its potential to revolutionize workflows and enhance user experiences becomes more evident. In healthcare, for example, its real-time diagnostic capabilities and image segmentation make it a valuable tool for improving patient outcomes, while in robotics, its enhanced vision and decision-making abilities open up new possibilities for autonomous systems. The entertainment industry, too, benefits from AIMv2’s ability to improve special effects and immersive user experiences, particularly in gaming and VR environments.
In summary, AIMv2’s technological advancements represent a breakthrough in the field of AI, with its far-reaching applications poised to reshape multiple sectors. From diagnostics to automation and entertainment, AIMv2 is setting the stage for the next wave of AI innovation.
As we look ahead, AIMv2 is set to play a pivotal role in the evolution of AI technologies, reshaping industries and advancing the capabilities of AI models across multiple domains. Its ability to effectively combine vision and language processing with fewer data samples positions it as a game-changer for sectors that rely heavily on AI, from healthcare to autonomous robotics and beyond. The scalability and versatility of AIMv2 suggest that future iterations of AI models will continue to become more efficient, less reliant on vast amounts of labeled data, and more capable of performing complex, multimodal tasks.
As AIMv2 continues to set benchmarks for vision and multimodal AI, it is likely that we will see more specialized applications emerge, particularly in healthcare, where its precision in medical imaging and diagnostic tools has already shown great promise. Robotics will also benefit significantly from the continued development of AIMv2, especially in applications requiring real-time decision-making and environmental interaction. In entertainment, the model's potential to enhance virtual and augmented reality experiences will drive immersive technologies forward, providing users with richer, more interactive content.
The future of AI is increasingly multimodal, and AIMv2’s advancements highlight a growing trend towards models that can seamlessly integrate vision, language, and other modalities. As the model matures, it will likely influence not just the design of future AI systems but also the way industries leverage artificial intelligence to solve real-world problems, making AI more accessible, adaptable, and efficient across a range of use cases.
Press contact
Timon Harz
oneboardhq@outlook.com
Other posts





Company
About
Blog
Careers
Press
Legal
Privacy
Terms
Security